The silhouette score is based on the principle of maximum internal cohesion and maximum cluster separation. In other words, we would like to find the number of clusters that produce a subdivision of the dataset into dense blocks that are well-separated from each other. In this way, every cluster will contain very similar elements and, selecting two elements belonging to different clusters, their distance should be greater than the maximum intra-cluster one.
After defining a distance metric (Euclidean is normally a good choice), we can compute the average intra-cluster distance for each element:
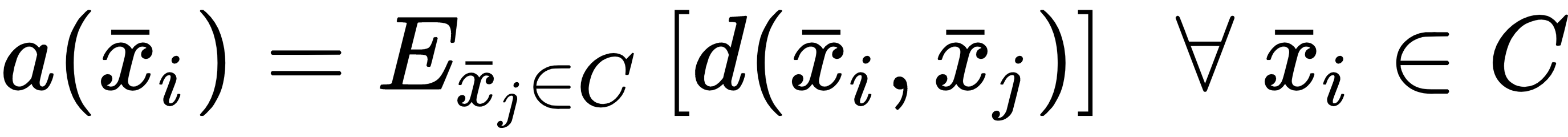
We can also define the average ...

