A Random Forest is a bagging ensemble method based on a set of Decision Trees. If we have Nc classifiers, the original dataset is split into Nc subsets (with replacement) called bootstrap samples:
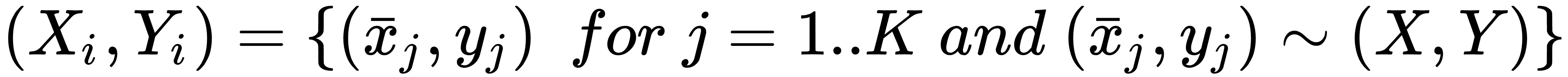
Contrary to a single Decision Tree, in a Random Forest the splitting policy is based on a medium level of randomness. In fact, instead of looking for the best choice, a random subset of features (for each tree) is used (in general, the number of features is computed using sqrt(•) or log(•)), trying to find the threshold that best separates the data. As a result, there will be many trees that are trained in a weaker way, and each of ...

