Let's consider an input dataset, X:
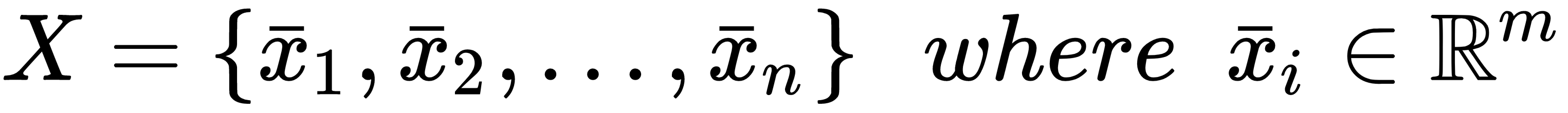
Every vector is made up of m features, so each of them is a candidate for the creation of a node based on a tuple (feature, threshold):

Single splitting node
According to the feature and the threshold, the structure of the tree will change. Intuitively, we should pick the feature that best separates our data. In other words, a perfectly separating feature will only be present in a node, and the two subsequent branches won't be based on it anymore. These conditions guarantee the convergence ...

