Chapter 1. Contemporary Machine Learning Risk Management
Building the best machine learning system starts with cultural competencies and business processes. This chapter presents numerous cultural and procedural approaches we can use to improve ML performance and safeguard our organizations’ ML against real-world safety and performance problems. It also includes a case study that illustrates what happens when an ML system is used without proper human oversight. The primary goal of the approaches discussed in this chapter is to create better ML systems. This might mean improved in silico test data performance. But it really means building models that perform as expected once deployed in vivo, so we don’t lose money, hurt people, or cause other harms.
Note
In vivo is Latin for “within the living.” We’ll sometimes use this term to mean something closer to “interacting with the living,” as in how ML models perform in the real world when interacting with human users. In silico means “by means of computer modeling or computer simulation,” and we’ll use this term to describe the testing data scientists often perform in their development environments before deploying ML models.
The chapter begins with a discussion of the current legal and regulatory landscape for ML and some nascent best-practice guidance, to inform system developers of their fundamental obligations when it comes to safety and performance. We’ll also introduce how the book aligns to the National Institute of Standards and Technology (NIST) AI Risk Management Framework (RMF) in this part of the chapter. Because those who do not study history are bound to repeat it, the chapter then highlights AI incidents, and discusses why understanding AI incidents is important for proper safety and performance in ML systems. Since many ML safety concerns require thinking beyond technical specifications, the chapter then blends model risk management (MRM), information technology (IT) security guidance, and practices from other fields to put forward numerous ideas for improving ML safety culture and processes within organizations. The chapter will close with a case study focusing on safety culture, legal ramifications, and AI incidents.
None of the risk management approaches discussed in this chapter are a silver bullet. If we want to manage risk successfully, we’ll need to pick from the wide variety of available controls those that work best for our organization. Larger organizations will typically be able to do more risk management than smaller organizations. Readers at large organizations may be able to implement many controls across various departments, divisions, or internal functions. Readers at smaller organizations will have to choose their risk management tactics judiciously. In the end, a great deal of technology risk management comes down to human behavior. Whichever risk controls an organization implements, they’ll need to be paired with strong governance and policies for the people that build and maintain ML systems.
A Snapshot of the Legal and Regulatory Landscape
It’s a myth that ML is unregulated. ML systems can and do break the law. Forgetting or ignoring the legal context is one of the riskiest things an organization can do with respect to ML systems. That said, the legal and regulatory landscape for ML is complicated and changing quickly. This section aims to provide a snapshot of important laws and regulations for overview and awareness purposes. We’ll start by highlighting the pending EU AI Act. We’ll then discuss the many US federal laws and regulations that touch on ML, US state and municipal laws for data privacy and AI, and the basics of product liability, then end the section with a rundown of recent Federal Trade Commission (FTC) enforcement actions.
Warning
The authors are not lawyers and nothing in this book is legal advice. The intersection of law and AI is an incredibly complex topic that data scientists and ML engineers are not equipped to handle alone. You may have legal concerns about ML systems that you work on. If so, seek real legal advice.
The Proposed EU AI Act
The EU has proposed sweeping regulations for AI that are expected to be passed in 2023. Known as the EU AI Act (AIA), they would prohibit certain uses of AI like distorting human behavior, social credit scoring, and real-time biometric surveillance. The AIA deems other uses to be high risk, including applications in criminal justice, biometric identification, employment screening, critical infrastructure management, law enforcement, essential services, immigration, and others—placing a high documentation, governance, and risk management burden on these. Other applications would be considered limited or low risk, with fewer compliance obligations for their makers and operators. Much like the EU General Data Protection Regulation (GDPR) has changed the way companies handle data in the US and around the world, EU AI regulations are designed to have an outsized impact on US and other international AI deployments. Whether we’re working in the EU or not, we may need to start familiarizing ourselves with the AIA. One of the best ways is to read the Annexes, especially Annexes 1 and 3–8, that define terms and layout documentation and conformity requirements.
US Federal Laws and Regulations
Because we’ve been using algorithms in one form or another for decades in our government and economy, many US federal laws and regulations already touch on AI and ML. These regulations tend to focus on social discrimination by algorithms, but also treat transparency, privacy, and other topics. The Civil Rights Acts of 1964 and 1991, the Americans with Disabilities Act (ADA), the Equal Credit Opportunity Act (ECOA), the Fair Credit Reporting Act (FCRA), and the Fair Housing Act (FHA) are some of the federal laws that attempt to prevent discrimination by algorithms in areas like employment, credit lending, and housing. ECOA and FCRA, along with their more detailed implementation in Regulation B, attempt to increase transparency in ML-based credit lending and guarantee recourse rights for credit consumers. For a rejected credit application, lenders are expected to indicate the reasons for the rejection, i.e., an adverse action, and describe the features in the ML model that drove the decision. If the provided reasoning or data is wrong, consumers should be able to appeal the decision.
The practice of MRM, defined in part in the Federal Reserve’s SR 11-7 guidance, forms a part of regulatory examinations for large US banks, and sets up organizational, cultural, and technical processes for good and reliable performance of ML used in mission-critical financial applications. Much of this chapter is inspired by MRM guidance, as it’s the most battle-tested ML risk management framework out there. Laws like the Health Insurance Portability and Accountability Act of 1996 (HIPAA) and the Family Educational Rights and Privacy Act (FERPA) set up serious data privacy expectations in healthcare and for students. Like the GDPR, HIPAA’s and FERPA’s interactions with ML are material, complex, and still debated. These are not even all the US laws that might affect our use of ML, but hopefully this brief listing provides an idea of what the US federal government has decided is important enough to regulate.
State and Municipal Laws
US states and cities have also taken up laws and regulations for AI and ML. New York City (NYC) Local Law 144, which mandates bias audits for automated employment decision tools, was initially expected to go into effect in January 2023. Under this law, every major employer in NYC will have to conduct bias testing of automated employment software and post the results on their website. Washington DC’s proposed Stop Discrimination by Algorithms Act attempts to replicate federal expectations for nondiscrimination and transparency, but for a much broader set of applications, for companies that operate in DC or use the data of many DC citizens.
Numerous states passed their own data privacy laws as well. Unlike the older HIPAA and FERPA federal laws, these state data privacy laws are often intentionally designed to partially regulate the use of AI and ML. States like California, Colorado, Virginia, and others have passed data privacy laws that mention increased transparency, decreased bias, or both, for automated decision-making systems. Some states have put biometric data or social media in their regulatory crosshairs too. For example, Illinois’ Biometric Information Privacy Act (BIPA) outlaws many uses of biometric data, and IL regulators have already started enforcement actions. The lack of a federal data privacy or AI law combined with this new crop of state and local laws makes the AI and ML compliance landscape very complicated. Our uses of ML may or may not be regulated, or may be regulated to varying degrees, based on the specific application, industry, and geography of the system.
Basic Product Liability
As makers of consumer products, data scientists and ML engineers have a fundamental obligation to create safe systems. To quote a recent Brookings Institute report, “Products Liability Law as a Way to Address AI Harms”, “Manufacturers have an obligation to make products that will be safe when used in reasonably foreseeable ways. If an AI system is used in a foreseeable way and yet becomes a source of harm, a plaintiff could assert that the manufacturer was negligent in not recognizing the possibility of that outcome.” Just like car or power tool manufacturers, makers of ML systems are subject to broad legal standards for negligence and safety. Product safety has been the subject of large amounts of legal and economic analysis, but this subsection will focus on one of the first and simplest standards for negligence: the Hand rule. Named after Judge Learned Hand, and coined in 1947, it provides a viable framework for ML product makers to think about negligence and due diligence. The Hand rule says that a product maker takes on a burden of care, and that the resources expended on that care should always be greater than the cost of a likely incident involving the product. Stated algebraically:
In more plain terms, organizations are expected to apply care, i.e., time, resources, or money, to a level commensurate to the cost associated with a foreseeable risk. Otherwise liability can ensue. In Figure 1-1, Burden is the parabolically increasing line, and risk, or Probability multiplied by Loss, is the parabolically decreasing line. While these lines are not related to a specific measurement, their parabolic shape is meant to reflect the last-mile problem in removing all ML system risk, and shows that the application of additional care beyond a reasonable threshold leads to diminishing returns for decreasing risk as well.
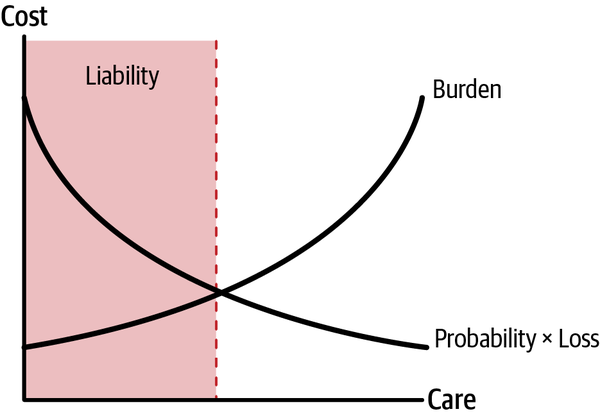
Figure 1-1. The Hand rule (adapted from “Economic Analysis of Alternative Standards of Liability in Accident Law”)
Note
A fairly standard definition for the risk of a technology incident is the estimated likelihood of the incident multiplied by its estimated cost. More broadly, the International Organization for Standardization (ISO) defines risk in the context of enterprise risk management as the “effect of uncertainty on objectives.”
While it’s probably too resource intensive to calculate the quantities in the Hand rule exactly, it is important to think about these concepts of negligence and liability when designing an ML system. For a given ML system, if the probability of an incident is high, if the monetary or other loss associated with a system incident is large, or if both quantities are large, organizations need to spend extra resources on ensuring safety for that system. Moreover, organizations should document to the best of their ability that due diligence exceeds the estimated failure probabilities multiplied by the estimated losses.
Federal Trade Commission Enforcement
How might we actually get in trouble? If you’re working in a regulated industry, you probably know your regulators. But if we don’t know if our work is regulated or who might be enforcing consequences if we cross a legal or regulatory red line, it’s probably the US Federal Trade Commission we need to be most concerned with. The FTC is broadly focused on unfair, deceptive, or predatory trade practices, and they have found reason to take down at least three prominent ML algorithms in three years. With their new enforcement tool, algorithmic disgorgement, the FTC has the ability to delete algorithms and data, and, typically, prohibit future revenue generation from an offending algorithm. Cambridge Analytica was the first firm to face this punishment, after their deceptive data collection practices surrounding the 2016 election. Everalbum and WW, known as Weight Watchers, have also faced disgorgement.
The FTC has been anything but quiet about its intention to enforce federal laws around AI and ML. FTC commissioners have penned lengthy treatises on algorithms and economic justice. They have also posted at least two blogs providing high-level guidance for companies who would like to avoid the unpleasantness of enforcement actions. These blogs highlight a number of concrete steps organizations should take. For example, in “Using Artificial Intelligence and Algorithms”, the FTC makes it clear that consumers should not be misled into interacting with an ML system posing as a human. Accountability is another prominent theme in “Using Artificial Intelligence and Algorithms,” “Aiming for Truth, Fairness, and Equity in Your Company’s Use of AI”, and other related publications. In “Aiming for Truth, Fairness, and Equity in Your Company’s Use of AI,” the FTC states, “Hold yourself accountable—or be ready for the FTC to do it for you” (emphasis added by the original author). This extremely direct language is unusual from a regulator. In “Using Artificial Intelligence and Algorithms,” the FTC puts forward, “Consider how you hold yourself accountable, and whether it would make sense to use independent standards or independent expertise to step back and take stock of your AI.” The next section introduces some of the emerging independent standards we can use to increase accountability, make better products, and decrease any potential legal liability.
Authoritative Best Practices
Data science mostly lacks professional standards and licensing today, but some authoritative guidance is starting to appear on the horizon. ISO is beginning to outline technical standards for AI. Making sure our models are in line with ISO standards would be one way to apply an independent standard to our ML work. Particularly for US-based data scientists, the NIST AI RMF is a very important project to watch.
Version 1 of the AI RMF was released in January 2023. The framework puts forward characteristics of trustworthiness in AI systems: validity, reliability, safety, security, resiliency, transparency, accountability, explainability, interpretability, bias management, and enhanced privacy. Then it presents actionable guidance across four organizational functions—map, measure, manage, and govern—for achieving trustworthiness. The guidance in the map, measure, manage, and govern functions is subdivided into more detailed categories and subcategories. To see these categories of guidance, check out the RMF or the AI RMF playbook, which provides even more detailed suggestions.
Note
The NIST AI Risk Management Framework is a voluntary tool for improving the trustworthiness of AI and ML systems. The AI RMF is not regulation and NIST is not a regulator.
To follow our own advice, and that of regulators and publishers of authoritative guidance, and to make this book more useful, we’ll be calling out how we believe the content of each chapter in Part I aligns to the AI RMF. Following this paragraph, readers will find a callout box that matches the chapter subheadings with AI RMF subcategories. The idea is that readers can use the table to understand how employing the approaches discussed in each chapter may help them adhere to the AI RMF. Because the subcategory advice may, in some cases, sound abstract to ML practitioners, we provide more practice-oriented language that matches the RMF categories; this will be helpful in translating the RMF into in vivo ML deployments. Check out the callout box to see how we think Chapter 1 aligns with the AI RMF, and look for similar tables at the start of each chapter in Part I.
AI Incidents
In many ways, the fundamental goal of ML safety processes and related model debugging, also discussed in Chapter 3, is to prevent and mitigate AI incidents. Here, we’ll loosely define AI incidents as any outcome of the system that could cause harm. As becomes apparent when using the Hand rule as a guide, the severity of an AI incident is increased by the loss the incident causes, and decreased by the care taken by the operators to mitigate those losses.
Because complex systems drift toward failure, there is no shortage of AI incidents to discuss as examples. AI incidents can range from annoying to deadly—from mall security robots falling down stairs, to self-driving cars killing pedestrians, to mass-scale diversion of healthcare resources away from those who need them most. As pictured in Figure 1-2, AI incidents can be roughly divided into three buckets:
- Abuses
-
AI can be used for nefarious purposes, apart from specific hacks and attacks on other AI systems. The day may already have come when hackers use AI to increase the efficiency and potency of their more general attacks. What the future could hold is even more frightening. Specters like autonomous drone attacks and ethnic profiling by authoritarian regimes are already on the horizon.
- Attacks
-
Examples of all major types of attacks—confidentiality, integrity, and availability attacks (see Chapter 5 for more information)—have been published by researchers. Confidentiality attacks involve the exfiltration of training data or model logic from AI system endpoints. Integrity attacks include adversarial manipulation of training data or model outcomes, either through adversarial examples, evasion, impersonation, or poisoning. Availability attacks can be conducted through more standard denial-of-service approaches, through sponge examples that overuse system resources, or via algorithmic discrimination induced by some adversary to deny system services to certain groups of users.
- Failures
-
AI system failures tend to involve algorithmic discrimination, safety and performance lapses, data privacy violations, inadequate transparency, or problems in third-party system components.
AI incidents are a reality. And like the systems from which they arise, AI incidents can be complex. AI incidents have multiple causes: failures, attacks, and abuses. They also tend to blend traditional notions of computer security with concerns like data privacy and algorithmic discrimination.
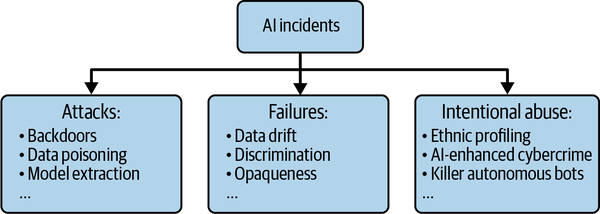
Figure 1-2. A basic taxonomy of AI incidents (adapted from “What to Do When AI Fails")
The 2016 Tay chatbot incident is an informative example. Tay was a state-of-the-art chatbot trained by some of the world’s leading experts at Microsoft Research for the purpose of interacting with people on Twitter to increase awareness about AI. Sixteen hours after its release—and 96,000 tweets later—Tay had spiraled into writing as a neo-Nazi pornographer and had to be shut down. What happened? Twitter users quickly learned that Tay’s adaptive learning system could easily be poisoned. Racist and sexual content tweeted at the bot was incorporated into its training data, and just as quickly resulted in offensive output. Data poisoning is an integrity attack, but due to the context in which it was carried out, this attack resulted in algorithmic discrimination. It’s also important to note that Tay’s designers, being world-class experts at an extremely well-funded research center, seemed to have put some guardrails in place. Tay would respond to certain hot-button issues with precanned responses. But that was not enough, and Tay devolved into a public security and algorithmic discrimination incident for Microsoft Research.
Think this was a one-off incident? Wrong. Just recently, again due to hype and failure to think through performance, safety, privacy, and security risks systematically, many of Tay’s most obvious failures were repeated in Scatter Lab’s release of its Lee Luda chatbot. When designing ML systems, plans should be compared to past known incidents in hope of preventing future similar incidents. This is precisely the point of recent AI incident database efforts and associated publications.
AI incidents can also be an apolitical motivator for responsible technology development. For better or worse, cultural and political viewpoints on topics like algorithmic discrimination and data privacy can vary widely. Getting a team to agree on ethical considerations can be very difficult. It might be easier to get them working to prevent embarrassing and potentially costly or dangerous incidents, which should be a baseline goal of any serious data science team. The notion of AI incidents is central to understanding ML safety; a central theme of this chapter’s content is cultural competencies and business processes that can be used to prevent and mitigate AI incidents. We’ll dig into those mitigants in the next sections and take a deep dive into a real incident to close the chapter.
Cultural Competencies for Machine Learning Risk Management
An organization’s culture is an essential aspect of responsible AI. This section will discuss cultural competencies like accountability, drinking our own champagne, domain expertise, and the stale adage “move fast and break things.”
Organizational Accountability
A key to the successful mitigation of ML risks is real accountability within organizations for AI incidents. If no one’s job is at stake when an ML system fails, gets attacked, or is abused for nefarious purposes, then it’s entirely possible that no one in that organization really cares about ML safety and performance. In addition to developers who think through risks, apply software quality assurance (QA) techniques, and model debugging methods, organizations need individuals or teams who validate ML system technology and audit associated processes. Organizations also need someone to be responsible for AI incident response plans. This is why leading financial institutions, whose use of predictive modeling has been regulated for decades, employ a practice known as model risk management. MRM is patterned off the Federal Reserve’s SR 11-7 model risk management guidance, which arose out the of the financial crisis of 2008. Notably, implementation of MRM often involves accountable executives and several teams that are responsible for the safety and performance of models and ML systems.
Implementation of MRM standards usually requires several different teams and executive leadership. These are some of the key tenets that form the cultural backbone for MRM:
- Written policies and procedures
-
The organizational rules for making and using ML should be written and available for all organizational stakeholders. Those close to ML systems should have trainings on the policies and procedures. These rules should also be audited to understand when they need to be updated. No one should be able to claim ignorance of the rules, the rules should be transparent, and the rules should not change without approval. Policies and procedures should include clear mechanisms for escalating serious risks or problems to senior management, and likely should put forward whistleblower processes and protections.
- Effective challenge
-
Effective challenge dictates that experts with the capability to change a system, who did not build the ML system being challenged, perform validation and auditing. MRM practices typically distribute effective challenge across three “lines of defense,” where conscientious system developers make up the first line of defense and independent, skilled, and empowered technical validators and process auditors make up the second and third lines, respectively.
- Accountable leadership
-
A specific executive within an organization should be accountable for ensuring AI incidents do not happen. This position is often referred to as chief model risk officer (CMRO). It’s also not uncommon for CMRO terms of employment and compensation to be linked to ML system performance. The role of CMRO offers a very straightforward cultural check on ML safety and performance. If our boss really cares about ML system safety and performance, then we start to care too.
- Incentives
-
Data science staff and management must be incentivized to implement ML responsibly. Often, compressed product timelines can incentivize the creation of a minimum viable product first, with rigorous testing and remediation relegated to the end of the model lifecycle immediately before deployment to production. Moreover, ML testing and validation teams are often evaluated by the same criteria as ML development teams, leading to a fundamental misalignment where testers and validators are encouraged to move quickly rather than assure quality. Aligning timeline, performance evaluation, and pay incentives to team function helps solidify a culture of responsible ML and risk mitigation.
Of course, small or young organizations may not be able to spare an entire full-time employee to monitor ML system risk. But it’s important to have an individual or group held accountable if ML systems cause incidents and rewarded if the systems work well. If an organization assumes that everyone is accountable for ML risk and AI incidents, the reality is that no one is accountable.
Culture of Effective Challenge
Whether our organization is ready to adopt full-blown MRM practices, or not, we can still benefit from certain aspects of MRM. In particular, the cultural competency of effective challenge can be applied outside of the MRM context. At its core, effective challenge means actively challenging and questioning steps taken throughout the development of ML systems. An organizational culture that encourages serious questioning of ML system designs will be more likely to develop effective ML systems or products, and to catch problems before they explode into harmful incidents. Note that effective challenge cannot be abusive, and it must apply equally to all personnel developing an ML system, especially so-called “rockstar” engineers and data scientists. Effective challenge should also be structured, such as weekly meetings where current design thinking is questioned and alternative design choices are seriously considered.
Diverse and Experienced Teams
Diverse teams can bring wider and previously uncorrelated perspectives to bear on the design, development, and testing of ML systems. Nondiverse teams often do not. Many have documented the unfortunate outcomes that can arise as a result of data scientists not considering demographic diversity in the training or results of ML systems. A potential solution to these kinds of oversights is increasing demographic diversity on ML teams from its current woeful levels. Business or other domain experience is also important when building teams. Domain experts are instrumental in feature selection and engineering, and in the testing of system outputs. In the mad rush to develop ML systems, domain-expert participation can also serve as a safety check. Generalist data scientists often lack the experience necessary to deal with domain-specific data and results. Misunderstanding the meaning of input data or output results is a recipe for disaster that can lead to AI incidents when a system is deployed. Unfortunately, when it comes to data scientists forgetting or ignoring the importance of domain expertise, the social sciences deserve a special emphasis. In a trend referred to as “tech’s quiet colonization of the social sciences”, several organizations have pursued regrettable ML projects that seek to replace decisions that should be made by trained social scientists or that simply ignore the collective wisdom of social science domain expertise altogether.
Drinking Our Own Champagne
Also known as “eating our own dog food,” the practice of drinking our own champagne refers to using our own software or products inside of our own organization. Often a form of prealpha or prebeta testing, drinking our own champagne can identify problems that emerge from the complexity of in vivo deployment environments before bugs and failures affect customers, users, or the general public. Because serious issues like concept drift, algorithmic discrimination, shortcut learning, and underspecification are notoriously difficult to identify using standard ML development processes, drinking our own champagne provides a limited and controlled, but also realistic, test bed for ML systems. Of course, when organizations employ demographically and professionally diverse teams and include domain experts in the field where the ML system will be deployed, drinking our own champagne is more likely to catch a wide variety of problems. Drinking our own champagne also brings the classical Golden Rule into AI. If we’re not comfortable using a system on ourselves or in our own organization, then we probably shouldn’t deploy that system.
Note
One important aspect to consider about deployment environments is the impact of our ML systems on ecosystems and the planet—for example:
-
The carbon footprint of ML models
-
The possibility that an ML system could damage the environment by causing an AI incident
If we’re worried about the environmental impacts of our model, we should loop in ML governance with broader environmental, social, and governance efforts at our organization.
Moving Fast and Breaking Things
The mantra “move fast and break things” is almost a religious belief for many “rock-star” engineers and data scientists. Sadly, these top practitioners also seem to forget that when they go fast and break things, things get broken. As ML systems make more high-impact decisions that implicate autonomous vehicles, credit, employment, university grades and attendance, medical diagnoses and resource allocation, mortgages, pretrial bail, parole, and more, breaking things means more than buggy apps. It can mean that a small group of data scientists and engineers causes real harm at scale to many people. Participating in the design and implementation of high-impact ML systems requires a mindset change to prevent egregious performance and safety problems. Practitioners must change from prioritizing the number of software features they can push, or the test data accuracy of an ML model, to recognizing the implications and downstream risks of their work.
Organizational Processes for Machine Learning Risk Management
Organizational processes play a key role in ensuring that ML systems are safe and performant. Like the cultural competencies discussed in the previous section, organizational processes are a key nontechnical determinant of reliability in ML systems. This section on processes starts out by urging practitioners to consider, document, and attempt to mitigate any known or foreseeable failure modes for their ML systems. We then discuss more about MRM. While “Cultural Competencies for Machine Learning Risk Management” focused on the people and mindsets necessary to make MRM a success, this section will outline the different processes MRM uses to mitigate risks in advanced predictive modeling and ML systems. While MRM is a worthy process standard to which we can all aspire, there are additional important process controls that are not typically part of MRM. We’ll look beyond traditional MRM in this section and highlight crucial risk control processes like pair or double programming and security permission requirements for code deployment. This section will close with a discussion of AI incident response. No matter how hard we work to minimize harms while designing and implementing an ML system, we still have to prepare for failures and attacks.
Forecasting Failure Modes
ML safety and ethics experts roughly agree on the importance of thinking through, documenting, and attempting to mitigate foreseeable failure modes for ML systems. Unfortunately, they also mostly agree that this is a nontrivial task. Happily, new resources and scholarship on this topic have emerged in recent years that can help ML system designers forecast incidents in more systematic ways. If holistic categories of potential failures can be identified, it makes hardening ML systems for better real-world performance and safety a more proactive and efficient task. In this subsection, we’ll discuss one such strategy, along with a few additional processes for brainstorming future incidents in ML systems.
Known past failures
As discussed in “Preventing Repeated Real World AI Failures by Cataloging Incidents: The AI Incident Database”, one the most efficient ways to mitigate potential AI incidents in our ML systems is to compare our system design to past failed designs. Much like transportation professionals investigating and cataloging incidents, then using the findings to prevent related incidents and test new technologies, several ML researchers, commentators, and trade organizations have begun to collect and analyze AI incidents in hopes of preventing repeated and related failures. Likely the most high-profile and mature AI incident repository is the AI Incident Database. This searchable and interactive resource allows registered users to search a visual database with keywords and locate different types of information about publicly recorded incidents.
Consult this resource while developing ML systems. If a system similar to the one we’re currently designing, implementing, or deploying has caused an incident in the past, this is one of strongest indicators that our new system could cause an incident. If we see something that looks familiar in the database, we should stop and think about what we’re doing a lot more carefully.
Failures of imagination
Imagining the future with context and detail is never easy. And it’s often the context in which ML systems operate, accompanied by unforeseen or unknowable details, that lead to AI incidents. In a recent workshop paper, the authors of “Overcoming Failures of Imagination in AI Infused System Development and Deployment” put forward some structured approaches to hypothesize about those hard-to-imagine future risks. In addition to deliberating on the who (e.g., investors, customers, vulnerable nonusers), what (e.g., well-being, opportunities, dignity), when (e.g., immediately, frequently, over long periods of time), and how (e.g., taking an action, altering beliefs) of AI incidents, they also urge system designers to consider the following:
-
Assumptions that the impact of the system will be only beneficial (and to admit when uncertainty in system impacts exists)
-
The problem domain and applied use cases of the system, as opposed to just the math and technology
-
Any unexpected or surprising results, user interactions, and responses to the system
Causing AI incidents is embarrassing, if not costly or illegal, for organizations. AI incidents can also hurt consumers and the general public. Yet, with some foresight, many of the currently known AI incidents could have been mitigated, if not wholly avoided. It’s also possible that in performing the due diligence of researching and conceptualizing ML failures, we find that our design or system must be completely reworked. If this is the case, take comfort that a delay in system implementation or deployment is likely less costly than the harms our organization or the public could experience if the flawed system was released.
Model Risk Management Processes
The process aspects of MRM mandate thorough documentation of modeling systems, human review of systems, and ongoing monitoring of systems. These processes represent the bulk of the governance burden for the Federal Reserve’s SR 11-7 MRM guidance, which is overseen by the Federal Reserve and the Office of the Comptroller of the Currency for predictive models deployed in material consumer finance applications. While only large organizations will be able to fully embrace all that MRM has to offer, any serious ML practitioner can learn something from the discipline. The following section breaks MRM processes down into smaller components so that readers can start thinking through using aspects of MRM in their organization.
Risk tiering
As outlined in the opening of this chapter, the product of the probability of a harm occurring and the likely loss resulting from that harm is an accepted way to rate the risk of a given ML system deployment. The product of risk and loss has a more formal name in the context of MRM, materiality. Materiality is a powerful concept that enables organizations to assign realistic risk levels to ML systems. More importantly, this risk-tiering allows for the efficient allocation of limited development, validation, and audit resources. Of course, the highest materiality applications should receive the greatest human attention and review, while the lowest materiality applications could potentially be handled by automatic machine learning (AutoML) systems and undergo minimal validation. Because risk mitigation for ML systems is an ongoing, expensive task, proper resource allocation between high-, medium-, and low-risk systems is a must for effective governance.
Model documentation
MRM standards also require that systems be thoroughly documented. First, documentation should enable accountability for system stakeholders, ongoing system maintenance, and a degree of incident response. Second, documentation must be standardized across systems for the most efficient audit and review processes. Documentation is where the rubber hits the road for compliance. Documentation templates, illustrated at a very high level by the following section list, are documents that data scientists and engineers fill in as they move through a standardized workflow or in the later stages of model development. Documentation templates should include all the steps that a responsible practitioner should conduct to build a sound model. If parts of the document aren’t filled out, that points to sloppiness in the training process. Since most documentation templates and frameworks also call for adding one’s name and contact information to the finished model document, there should be no mystery about who is not pulling their weight. For reference, the following section list is a rough combination of typical sections in MRM documentation and the sections recommended by the Annexes to the EU Artificial Intelligence Act:
-
Basic Information
-
Names of Developers and Stakeholders
-
Current Date and Revision Table
-
Summary of Model System
-
Business or Value Justification
-
Intended Uses and Users
-
Potential Harms and Ethical Considerations
-
-
Development Data Information
-
Source for Development Data
-
Data Dictionary
-
Privacy Impact Assessment
-
Assumptions and Limitations
-
Software Implementation for Data Preprocessing
-
-
Model Information
-
Description of Training Algorithm with Peer-Reviewed References
-
Specification of Model
-
Performance Quality
-
Assumptions and Limitations
-
Software Implementation for Training Algorithm
-
-
Testing Information
-
Quality Testing and Remediation
-
Discrimination Testing and Remediation
-
Security Testing and Remediation
-
Assumptions and Limitations
-
Software Implementation for Testing
-
-
Deployment Information
-
Monitoring Plans and Mechanisms
-
Up- and Downstream Dependencies
-
Appeal and Override Plans and Mechanisms
-
Audit Plans and Mechanisms
-
Change Management Plans
-
Incident Response Plans
-
-
References (if we’re doing science, then we’re building on the shoulders of giants and we’ll have several peer-reviewed references in a formatted bibliography!)
Of course, these documents can be hundreds of pages long, especially for high-materiality systems. The proposed datasheet and model card standards may also be helpful for smaller or younger organizations to meet these goals. If readers are feeling like lengthy model documentation sounds impossible for their organization today, then maybe these two simpler frameworks might work instead.
Model monitoring
A primary tenant of ML safety is that ML system performance in the real world is hard to predict and, accordingly, performance must be monitored. Hence, deployed-system performance should be monitored frequently and until a system is decommissioned. Systems can be monitored for any number of problematic conditions, the most common being input drift. While ML system training data encodes information about a system’s operating environment in a static snapshot, the world is anything but static. Competitors can enter markets, new regulations can be promulgated, consumer tastes can change, and pandemics or other disasters can happen. Any of these can change the live data that’s entering our ML system away from the characteristics of its training data, resulting in decreased, or even dangerous, system performance. To avoid such unpleasant surprises, the best ML systems are monitored both for drifting input and output distributions and for decaying quality, often known as model decay. While performance quality is the most common quantity to monitor, ML systems can also be monitored for anomalous inputs or predictions, specific attacks and hacks, and for drifting fairness characteristics.
Model inventories
Any organization that is deploying ML should be able to answer straightforward questions like:
-
How many ML systems are currently deployed?
-
How many customers or users do these systems affect?
-
Who are the accountable stakeholders for each system?
MRM achieves this goal through the use of model inventories. A model inventory is a curated and up-to-date database of all an organization’s ML systems. Model inventories can serve as a repository for crucial information for documentation, but should also link to monitoring plans and results, auditing plans and results, important past and upcoming system maintenance and changes, and plans for incident response.
System validation and process auditing
Under traditional MRM practices, an ML system undergoes two primary reviews before its release. The first review is a technical validation of the system, where skilled validators, not uncommonly PhD-level data scientists, attempt to poke holes in system design and implementation, and work with system developers to fix any discovered problems. The second review investigates processes. Audit and compliance personnel carefully analyze the system design, development, and deployment, along with documentation and future plans, to ensure all regulatory and internal process requirements are met. Moreover, because ML systems change and drift over time, review must take place whenever a system undergoes a major update or at an agreed upon future cadence.
Readers may be thinking (again) that their organization doesn’t have the resources for such extensive reviews. Of course that is a reality for many small or younger organizations. The keys for validation and auditing, that should work at nearly any organization, are having technicians who did not develop the system test it, having a function to review nontechnical internal and external obligations, and having sign-off oversight for important ML system deployments.
Change management
Like all complex software applications, ML systems tend to have a large number of different components. From backend ML code, to application programming interfaces (APIs), to graphical user interfaces (GUIs), changes in any component of the system can cause side effects in other components. Add in issues like data drift, emergent data privacy and anti-discrimination regulations, and complex dependencies on third-party software, and change management in ML systems becomes a serious concern. If we’re in the planning or design phase of a mission-critical ML system, we’ll likely need to make change management a first-class process control. Without explicit planning and resources for change management, process or technical mistakes that arise through the evolution of the system, like using data without consent or API mismatches, are very difficult to prevent. Furthermore, without change management, such problems might not even be detected until they cause an incident.
We’ll circle back to MRM throughout the book. It’s one the most battle-tested frameworks for governance and risk management of ML systems. Of course, MRM is not the only place to draw inspiration for improved ML safety and performance processes, and the next subsection will draw out lessons from other practice areas.
Note
Reading the 21-page SR 11-7 model risk management guidance is a quick way to up-skill yourself in ML risk management. When reading it, pay special attention to the focus on cultural and organizational structures. Managing technology risks is often more about people than anything else.
Beyond Model Risk Management
There are many ML risk management lessons to be learned from financial audit, data privacy, and software development best practices and from IT security. This subsection will shine a light on ideas that exist outside the purview of traditional MRM: model audits, impact assessments, appeals, overrides, opt outs, pair or double programming, least privilege, bug bounties, and incident response, all from an ML safety and performance perspective.
Model audits and assessments
Audit is a common term in MRM, but it also has meanings beyond what it is typically known as—the third line of defense in a more traditional MRM scenario. The phrase model audit has come to prominence in recent years. A model audit is an official testing and transparency exercise focusing on an ML system that tracks adherence to some policy, regulation, or law. Model audits tend to be conducted by independent third parties with limited interaction between auditor and auditee organizations. For a good breakdown of model audits, check out the recent paper “Algorithmic Bias and Risk Assessments: Lessons from Practice”. The paper “Closing the AI Accountability Gap: Defining an End-to-End Framework for Internal Algorithmic Auditing” puts forward a solid framework for audits and assessments, even including worked documentation examples. The related term, model assessment, seems to mean a more informal and cooperative testing and transparency exercise that may be undertaken by external or internal groups.
ML audits and assessments may focus on bias issues or other serious risks including safety, data privacy harms, and security vulnerabilities. Whatever their focus, audits and auditors have be fair and transparent. Those conducting audits should be held to clear ethical or professional standards, which barely exist as of 2023. Without these kinds of accountability mechanisms or binding guidelines, audits can be an ineffective risk management practice, and worse, tech-washing exercises that certify harmful ML systems. Despite flaws, audits are an en vogue favorite risk control tactic of policy-makers and researchers, and are being written into laws—for example, the aforementioned New York City Local Law 144.
Impact assessments
Impact assessments are a formal documentation approach used in many fields to forecast and record the potential issues a system could cause once implemented. Likely due to their use in data privacy, impact assessments are starting to show up in organizational ML policies and proposed laws. Impact assessments are an effective way to think through and document the harms that an ML system could cause, increasing accountability for designers and operators of AI systems. But impact assessments are not enough on their own. Remembering the definition of risk and materiality previously put forward, impact is just one factor in risk. Impacts must be combined with likelihoods to form a risk measure, then risks must be actively mitigated, where the highest-risk applications are accorded the most oversight. Impact assessments are just the beginning of a broader risk management process. Like other risk management processes, they must be performed at a cadence that aligns to the system being assessed. If a system changes quickly, it will need more frequent impact assessments. Another potential issue with impact assessments is caused when they are designed and implemented by the ML teams that are also being assessed. In this case, there will be a temptation to diminish the scope of the assessment and downplay any potential negative impacts. Impact assessments are an important part of broader risk management and governance strategies, but they must be conducted as often as required by a specific system, and likely conducted by independent oversight professionals.
Appeal, override, and opt out
Ways for users or operators to appeal and override inevitable wrong decisions should be built into most ML systems. It’s known by many names across disciplines: actionable recourse, intervenability, redress, or adverse action notices. This can be as simple as the “Report inappropriate predictions” function in the Google search bar, or it can be as sophisticated as presenting data and explanations to users and enabling appeal processes for demonstrably wrong data points or decision mechanisms. Another similar approach, known as opt out, is to let users do business with an organization the old-fashioned way without going through any automated processing. Many data privacy laws and major US consumer finance laws address recourse, opt out, or both. Automatically forcing wrong decisions on many users is one of the clearest ethical wrongs in ML. We shouldn’t fall into an ethical, legal, and reputational trap that’s so clear and so well-known, but many systems do. That’s likely because it takes planning and resources for both processes and technology, laid out from the beginning of designing an ML system, to get appeal, override, and opt out right.
Pair and double programming
Because they tend to be complex and stochastic, it’s hard to know if any given ML algorithm implementation is correct! This is why some leading ML organizations implement ML algorithms twice as a QA mechanism. Such double implementation is usually achieved by one of two methods: pair programming or double programming. In the pair programming approach, two technical experts code an algorithm without collaborating. Then they join forces and work out any discrepancies between their implementations. In double programming, the same practitioner implements the same algorithm twice, but in very different programming languages, such as Python (object-oriented) and SAS (procedural). They must then reconcile any differences between their two implementations. Either approach tends to catch numerous bugs that would otherwise go unnoticed until the system was deployed. Pair and double programming can also align with the more standard workflow of data scientists prototyping algorithms, while dedicated engineers harden them for deployment. However, for this to work, engineers must be free to challenge and test data science prototypes and should not be relegated to simply recoding prototypes.
Security permissions for model deployment
The concept of least privilege from IT security states that no system user should ever have more permissions than they need. Least privilege is a fundamental process control that, likely because ML systems touch so many other IT systems, tends to be thrown out the window for ML build-outs and for so-called “rock star” data scientists. Unfortunately, this is an ML safety and performance antipattern. Outside the world of overhyped ML and rock star data science, it’s long been understood that engineers cannot adequately test their own code and that others in a product organization—product managers, attorneys, or executives—should make the final call as to when software is released.
For these reasons, the IT permissions necessary to deploy an ML system should be distributed across several teams within IT organizations. During development sprints, data scientists and engineers certainly must retain full control over their development environments. But, as important releases or reviews approach, the IT permissions to push fixes, enhancements, or new features to user-facing products are transferred away from data scientists and engineers to product managers, testers, attorneys, executives, or others. Such process controls provide a gate that prevents unapproved code from being deployed.
Bug bounties
Bug bounties are another concept we can borrow from computer security. Traditionally, a bug bounty is when an organization offers rewards for finding problems in its software, particularly security vulnerabilities. Since ML is mostly just software, we can do bug bounties for ML systems. While we can use bug bounties to find security problems in ML systems, we can also use them to find other types of problems related to reliability, safety, transparency, explainability, interpretability, or privacy. Through bug bounties, we use monetary rewards to incentivize community feedback in a standardized process. As we’ve highlighted elsewhere in the chapter, incentives are crucial in risk management. Generally, risk management work is tedious and resource consuming. If we want our users to find major problems in our ML systems for us, we need to pay them or reward them in some other meaningful way. Bug bounties are typically public endeavors. If that makes some organizations nervous, internal hackathons in which different teams look for bugs in ML systems may have some of the same positive effects. Of course, the more participants are incentivized to participate, the better the results are likely to be.
AI incident response
According to the vaunted SR 11-7 guidance, “even with skilled modeling and robust validation, model risk cannot be eliminated.” If risks from ML systems and ML models cannot be eliminated, then such risks will eventually lead to incidents. Incident response is already a mature practice in the field of computer security. Venerable institutions like NIST and SANS have published computer security incident response guidelines for years. Given that ML is a less mature and higher-risk technology than general-purpose enterprise computing, formal AI incident response plans and practices are a must for high-impact or mission-critical AI systems.
Formal AI incident response plans enable organizations to respond more quickly and effectively to inevitable incidents. Incident response also plays into the Hand rule discussed at the beginning of the chapter. With rehearsed incident response plans in place, organizations may be able to identify, contain, and eradicate AI incidents before they spiral into costly or dangerous public spectacles. AI incident response plans are one of the most basic and universal ways to mitigate AI-related risks. Before a system is deployed, incident response plans should be drafted and tested. For young or small organizations that cannot fully implement model risk management, AI incident response is a cost-effective and potent AI risk control to consider. Borrowing from computer incident response, AI incident response can be thought of in six phases:
- Phase 1: Preparation
-
In addition to clearly defining an AI incident for our organization, preparation for AI incidents includes personnel, logistical, and technology plans for when an incident occurs. Budget must be set aside for response, communication strategies must be put in place, and technical safeguards for standardizing and preserving model documentation, out-of-band communications, and shutting down AI systems must be implemented. One of the best ways to prepare and rehearse for AI incidents are tabletop discussion exercises, where key organizational personnel work through a realistic incident. Good starter questions for an AI incident tabletop include the following:
-
Who has the organizational budget and authority to respond to an AI incident?
-
Can the AI system in question be taken offline? By whom? At what cost? What upstream processes will be affected?
-
Which regulators or law enforcement agencies need to be contacted? Who will contact them?
-
Which external law firms, insurance agencies, or public relation firms need to be contacted? Who will contact them?
-
Who will manage communications? Internally, between responders? Externally, with customers or users?
-
- Phase 2: Identification
-
Identification is when organizations spot AI failures, attacks, or abuses. Identification also means staying vigilant for AI-related abuses. In practice, this tends to involve more general attack identification approaches, like network intrusion monitoring, and more specialized monitoring for AI system failures, like concept drift or algorithmic discrimination. Often the last step of the identification phase is to notify management, incident responders, and others specified in incident response plans.
- Phase 3: Containment
-
Containment refers to mitigating the incident’s immediate harms. Keep in mind that harms are rarely limited to the system where the incident began. Like more general computer incidents, AI incidents can have network effects that spread throughout an organizations’ and its customers’ technologies. Actual containment strategies will vary depending on whether the incident stemmed from an external adversary, an internal failure, or an off-label use or abuse of an AI system. If necessary, containment is also a good place to start communicating with the public.
- Phase 4: Eradication
-
Eradication involves remediating any affected systems. For example, sealing off any attacked systems from vectors of in- or ex-filtration, or shutting down a discriminatory AI system and temporarily replacing it with a trusted rule-based system. After eradication, there should be no new harms caused by the incident.
- Phase 5: Recovery
-
Recovery means ensuring all affected systems are back to normal and that controls are in place to prevent similar incidents in the future. Recovery often means retraining or reimplementing AI systems, and testing that they are performing at documented preincident levels. Recovery can also require careful analysis of technical or security protocols for personnel, especially in the case of an accidental failure or insider attack.
- Phase 6: Lessons learned
-
Lessons learned refers to corrections or improvements of AI incident response plans based on the successes and challenges encountered while responding to the current incident. Response plan improvements can be process- or technology-oriented.
When reading the following case, think about the phases of incident response, and whether an AI incident response plan would have been an effective risk control for Zillow.
Case Study: The Rise and Fall of Zillow’s iBuying
In 2018, the real estate tech company Zillow entered the business of buying homes and flipping them for a profit, known as iBuying. The company believed that its proprietary, ML-powered Zestimate algorithm could do more than draw eyeballs to its extremely popular web products. As reported by Bloomberg, Zillow employed domain experts to validate the numbers generated by their algorithms when they first started to buy homes. First, local real estate agents would price the property. The numbers were combined with the Zestimate, and a final team of experts vetted each offer before it was made.
According to Bloomberg, Zillow soon phased out these teams of domain experts in order to “get offers out faster,” preferring the speed and scale of a more purely algorithmic approach. When the Zestimate did not adapt to a rapidly inflating real estate market in early 2021, Zillow reportedly intervened to increase the attractiveness of its offers. As a result of these changes, the company began acquiring properties at a rate of nearly 10,000 homes per quarter. More flips means more staff and more renovation contractors, but as Bloomberg puts it, “Zillow’s humans couldn’t keep up.” Despite increasing staffing levels by 45% and bringing on “armies” of contractors, the iBuying system was not achieving profitability. The combination of pandemic staffing and supply challenges, the overheated housing market, and complexities around handling large numbers of mortgages were just too much for the iBuying project to manage.
In October of 2021, Zillow announced that it would stop making offers through the end of the year. As a result of Zillow’s appetite for rapid growth, as well as labor and supply shortages, the company had a huge inventory of homes to clear. To solve its inventory problem, Zillow was posting most homes for resale at a loss. Finally, on November 2, Zillow announced that it was writing down its inventory by over $500 million. Zillow’s foray into the automated house-flipping business was over.
Fallout
In addition to the huge monetary loss of its failed venture, Zillow announced that it would lay off about 2,000 employees—a full quarter of the company. In June of 2021, Zillow was trading at around $120 per share. At the time of this writing, nearly one year later, shares are approximately $40, erasing over $30 billion in stock value. (Of course, the entire price drop can’t be attributed to the iBuying incident, but it certainly factored into the loss.) The downfall of Zillow’s iBuying is rooted in many interwoven causes, and cannot be decoupled from the pandemic that struck in 2020 and upended the housing market. In the next section, we’ll examine how to apply what we’ve learned in this chapter about governance and risk management to Zillow’s misadventures.
Lessons Learned
What does this chapter teach us about the Zillow iBuying saga? Based on the public reporting, it appears Zillow’s decision to sideline human review of high-materiality algorithms was probably a factor in the overall incident. We also question whether Zillow had adequately thought through the financial risk it was taking on, whether appropriate governance structures were in place, and whether the iBuying losses might have been handled better as an AI incident. We don’t know the answers to many of these questions with respect to Zillow, so instead we’ll focus on insights readers can apply at their own organizations:
- Lesson 1: Validate with domain experts.
-
In this chapter, we stressed the importance of diverse and experienced teams as a core organizational competency for responsible ML development. Without a doubt, Zillow has internal and external access to world-class expertise in real estate markets. However, in the interest of speed and automation—sometimes referred to as “moving fast and breaking things” or “product velocity”—Zillow phased the experts out of the process of acquiring homes, choosing instead to rely on its Zestimate algorithm. According to follow-up reporting by Bloomberg in May 2022, “Zillow told its pricing experts to stop questioning the algorithms, according to people familiar with the process.” This choice may have proven fatal for the venture, especially in a rapidly changing, pandemic-driven real estate market. No matter the hype, AI is not smarter than humans yet. If we’re making high-risk decisions with ML, keep humans in the loop.
- Lesson 2: Forecast failure modes.
-
The coronavirus pandemic of 2020 created a paradigm shift in many domains and markets. ML models, which usually assume that the future will resemble the past, likely suffered across the board in many verticals. We shouldn’t expect a company like Zillow to see a pandemic on the horizon. But as we’ve discussed, rigorously interrogating the failure modes of our ML system constitutes a crucial competency for ML in high-risk settings. We do not know the details of Zillow’s model governance frameworks, but the downfall of Zillow’s iBuying stresses the importance of effective challenge and asking hard questions, like “What happens if the cost of performing renovations doubles over the next two years?” and “What will be the business cost of overpaying for homes by two percent over the course of six months?” For such a high-risk system, probable failure modes should be enumerated and documented, likely with board of directors oversight, and the actual financial risk should have been made clear to all senior decision-makers. At our organization, we need to know the cost of being wrong with ML and that senior leadership is willing to tolerate those costs. Maybe senior leaders at Zillow were accurately informed of iBuying’s financial risks, maybe they weren’t. What we know now is that Zillow took a huge risk, and it did not pay off.
- Lesson 3: Governance counts.
-
Zillow’s CEO is famous for risk-taking, and has a proven track record of winning big bets. But, we simply can’t win every bet we make. This is why we manage and govern risks when conducting automated decision making, especially in high-risk scenarios. SR 11-7 states, “the rigor and sophistication of validation should be commensurate with the bank’s overall use of models.” Zillow is not a bank, but Bloomberg’s May 2022 postmortem puts it this way: Zillow was “attempting to pivot from selling online advertising to operating what amounted to a hedge fund and a sprawling construction business.” Zillow drastically increased the materiality of its algorithms, but appears not to have drastically increased governance over those algorithms. As noted, most of the public reporting points to Zillow decreasing human oversight of its algorithms during its iBuying program, not increasing oversight. A separate risk function, empowered with the organizational stature to stop models from moving into production, and with the appropriate budget and staff levels, that reports directly to the board of directors and operates independently from business and technology functions headed by the CEO and CTO, is common in major consumer finance organization. This organizational structure, when it works as intended, allows for more objective and risk-based decisions about ML model performance, and avoids the conflicts of interest and confirmation bias that tend to occur when business and technology leaders evaluate their own systems for risk. We don’t know if Zillow had an independent model governance function—it is quite rare these days outside of consumer finance. But we do know that no risk or oversight function was able to stop the iBuying program before losses became staggering. While it’s a tough battle to fight as a single technician, helping our organization apply independent audits to its ML systems is a workable risk mitigation practice.
- Lesson 4: AI incidents occur at scale.
-
Zillow’s iBuying hijinks aren’t funny. Money was lost. Careers were lost—thousands of employees were laid off or resigned. This looks like a $30 billion AI incident. From the incident response lens, we need to be prepared for systems to fail, we need to be monitoring for systems to fail, and we need to have documented and rehearsed plans in place for containment, eradication, and recovery. From public reporting, it does appear that Zillow was aware of its iBuying problems, but its culture was more focused on winning big than preparing for failure. Given the size of the financial loss, Zillow’s containment efforts could have been more effective. Zillow was able to eradicate its most acute problems with the declaration of the roughly half-billion dollar write-off in November of 2021. As for recovery, Zillow’s leadership has plans for a new real estate super app, but given the stock price at the time of this writing, recovery is a long way off and investors are weary. Complex systems drift toward failure. Perhaps a more disciplined incident-handling approach could save our organization when it bets big with ML.
The final and most important lesson we can take away from the Zillow Offers saga is at the heart of this book. Emerging technologies always come with risks. Early automobiles were dangerous. Planes used to crash into mountainsides much more frequently. ML systems can perpetuate discriminatory practices, pose security and privacy risks, and behave unexpectedly. A fundamental difference between ML and other emerging technologies is that these systems can make decisions quickly and at huge scales. When Zillow leaned into its Zestimate algorithm, it could scale up its purchasing to hundreds of homes per day. In this case, the result was a write-down of half of a billion dollars, even larger stock losses, and the loss of thousands of jobs. This phenomenon of rapid failure at scale can be even more directly devastating when the target of interest is access to capital, social welfare programs, or the decision of who gets a new kidney.
Resources
Get Machine Learning for High-Risk Applications now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

