Flume is an Apache open source project and product, which is designed to move large amounts of data at a big data scale. It is highly scalable, distributed, and reliable, working on the basis of data source, data sink, and data channels, as shown in the following diagram taken from http://flume.apache.org/:
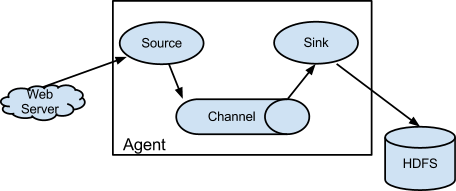
Flume uses agents to process data streams. As can be seen in the previous figure, an agent has a data source, data processing channel, and data sink. A clearer way to describe this flow is via the figure we just saw. The channel acts as a queue for the sourced data and the sink passes the data to the next link in the chain.
Flume ...

