May 2018
Intermediate to advanced
576 pages
14h 42m
English
We want to apply the policy iteration algorithm in order to find an optimal policy for the tunnel environment. Let's start by defining a random initial policy and a value matrix with all values (except the terminal states) equal to 0:
import numpy as npnb_actions = 4policy = np.random.randint(0, nb_actions, size=(height, width)).astype(np.uint8)tunnel_values = np.zeros(shape=(height, width))
The initial random policy (t=0) is shown in the following chart:
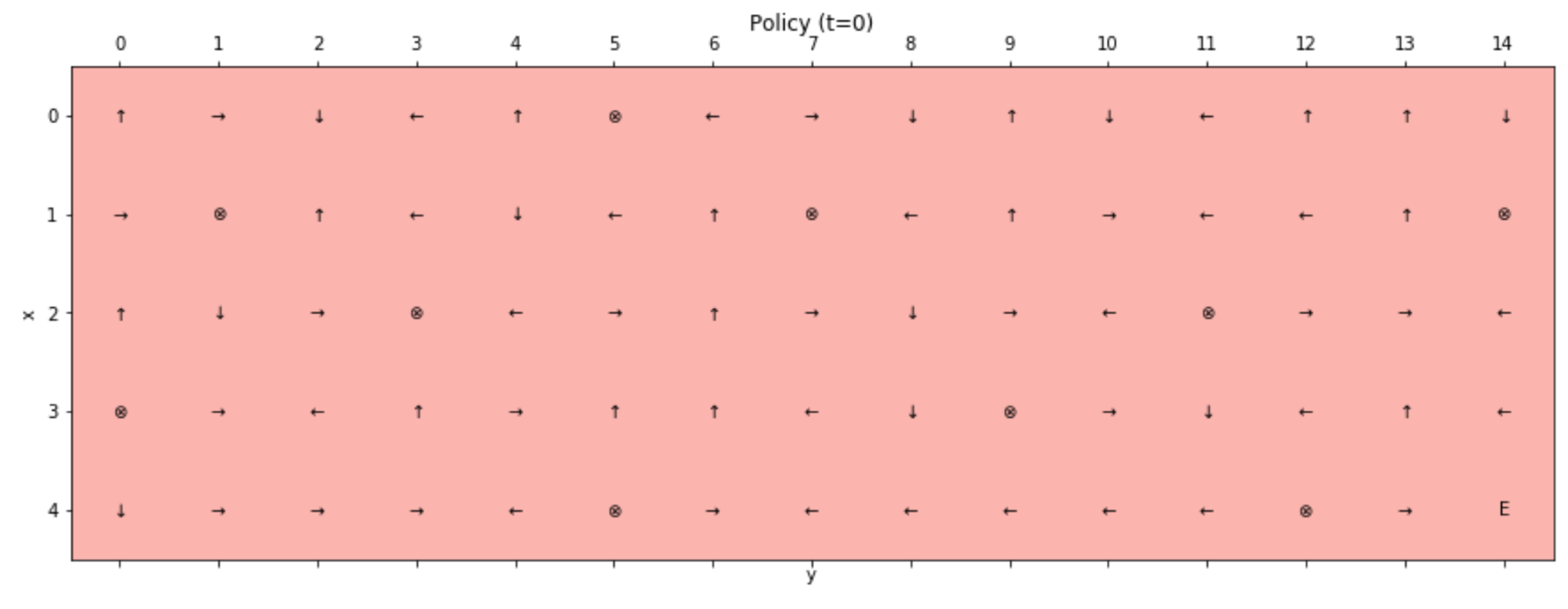
The states denoted with ⊗ represent the wells, while the final positive one is represented by the capital letter ...
Read now
Unlock full access






