May 2018
Intermediate to advanced
576 pages
14h 42m
English
An alternative to KD Trees is provided by Ball Trees. The idea is to rearrange the dataset in a way that is almost insensitive to high-dimensional samples. A ball is defined as a set of points whose distance from a center sample is less than or equal to a fixed radius:
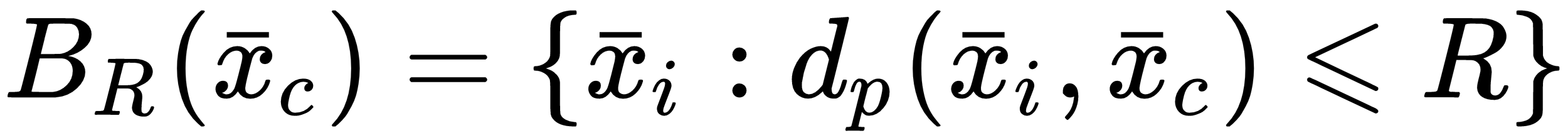
Starting from the first main ball, it's possible to build smaller ones nested into the parent ball and stop the process when the desired depth has been reached. A fundamental condition is that a point can always belong to a single ball. In this way, considering the cost of the N-dimensional distance, the computational complexity is O(N log M) and doesn't suffer the ...
Read now
Unlock full access






