May 2018
Intermediate to advanced
576 pages
14h 42m
English
Let's suppose we have a Gaussian data generating process, pdata ∼ N(0, Σ), and M n-dimensional zero-centered samples drawn from it:
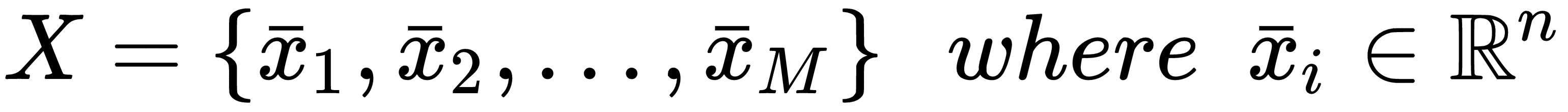
If pdata has a mean μ ≠ 0, it's also possible to use this model, but it's necessary to account for this non-null value with slight changes in some formulas. As the zero-centering normally has no drawbacks, it's easier to remove the mean to simplify the model.
One of the most common problems in unsupervised learning is finding a lower dimensional distribution plower such that the Kullback-Leibler divergence with pdata is minimized. When performing a factor analysis (FA), following the original proposal ...
Read now
Unlock full access






