May 2018
Intermediate to advanced
576 pages
14h 42m
English
If it's theoretically possible to create an unbiased model (even asymptotically), this is not true for variance. To understand this concept, it's necessary to introduce an important definition: the Fisher information. If we have a parameterized model and a data-generating process pdata, we can define the likelihood function by considering the following parameters:
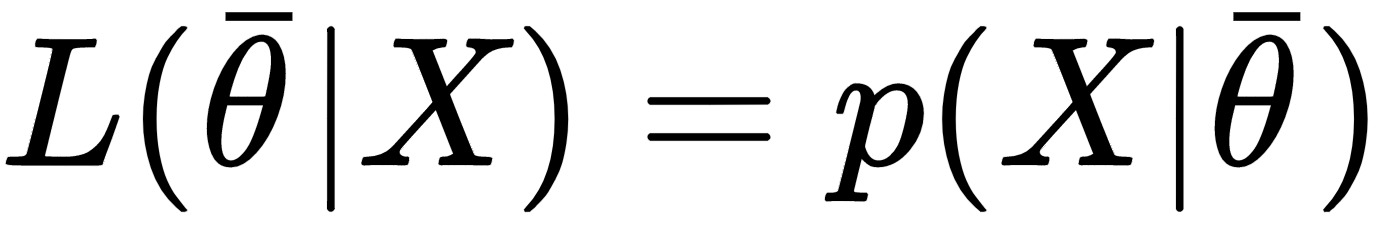
This function allows measuring how well the model describes the original data generating process. The shape of the likelihood can vary substantially, from well-defined, peaked curves, to almost flat surfaces. Let's consider the following graph, showing two examples ...
Read now
Unlock full access






