May 2018
Intermediate to advanced
576 pages
14h 42m
English
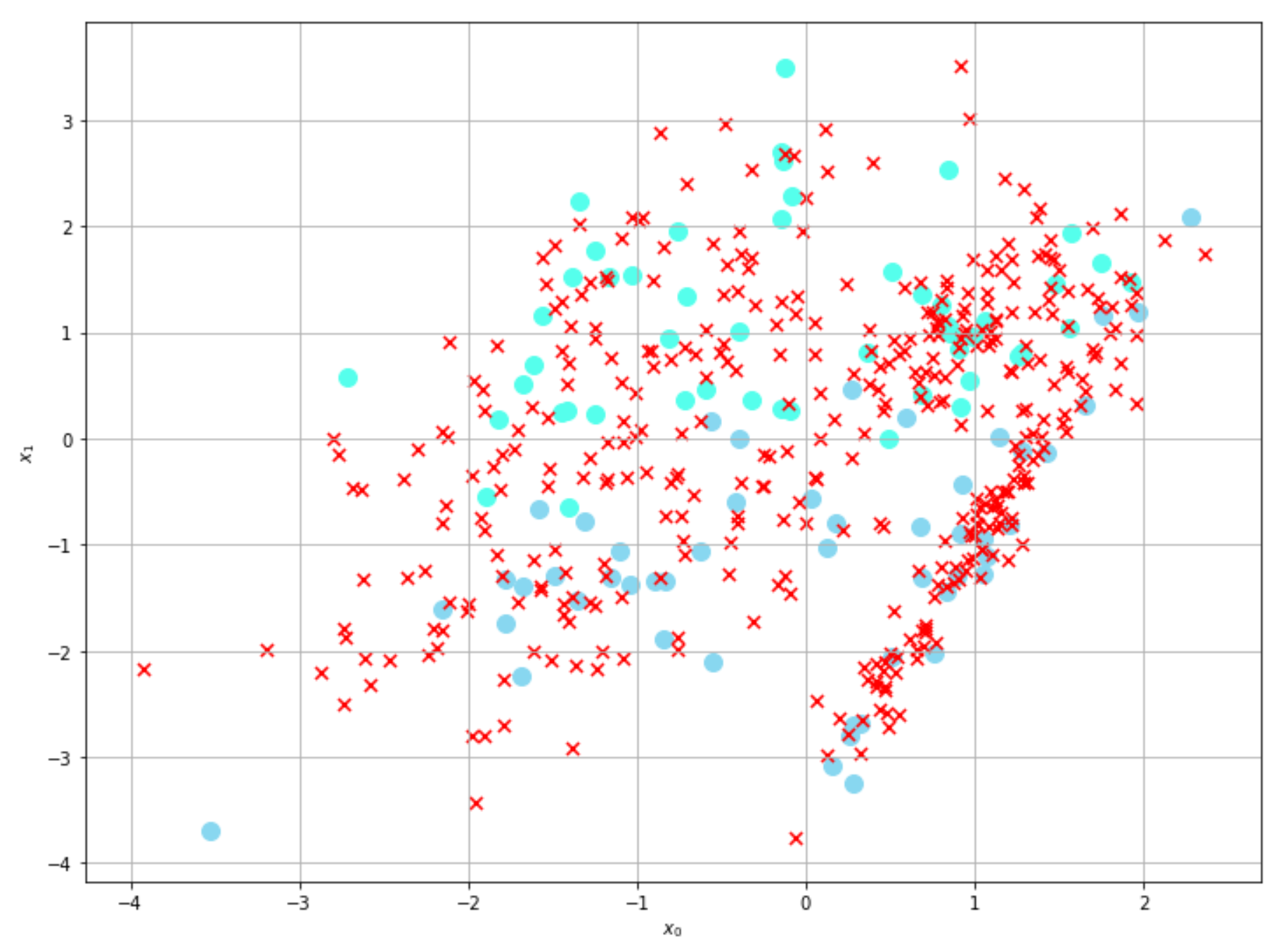
In our Python implementation, we are going to use a bidimensional dataset similar to one employed in the previous method; however, in this case, we impose 400 unlabeled samples out of a total of 500 points:
from sklearn.datasets import make_classificationnb_samples = 500nb_unlabeled = 400X, Y = make_classification(n_samples=nb_samples, n_features=2, n_redundant=0, random_state=1000)Y[Y==0] = -1Y[nb_samples - nb_unlabeled:nb_samples] = 0
The corresponding plot is shown in the following graph:
The procedure is similar to the one we used before. First of all, we need to initialize our variables: ...
Read now
Unlock full access






