May 2018
Intermediate to advanced
576 pages
14h 42m
English
Scikit-Learn implements a slightly different algorithm proposed by Zhu and Ghahramani (in the aforementioned paper) where the affinity matrix W can be computed using both methods (KNN and RBF), but it is normalized to become a probability transition matrix:
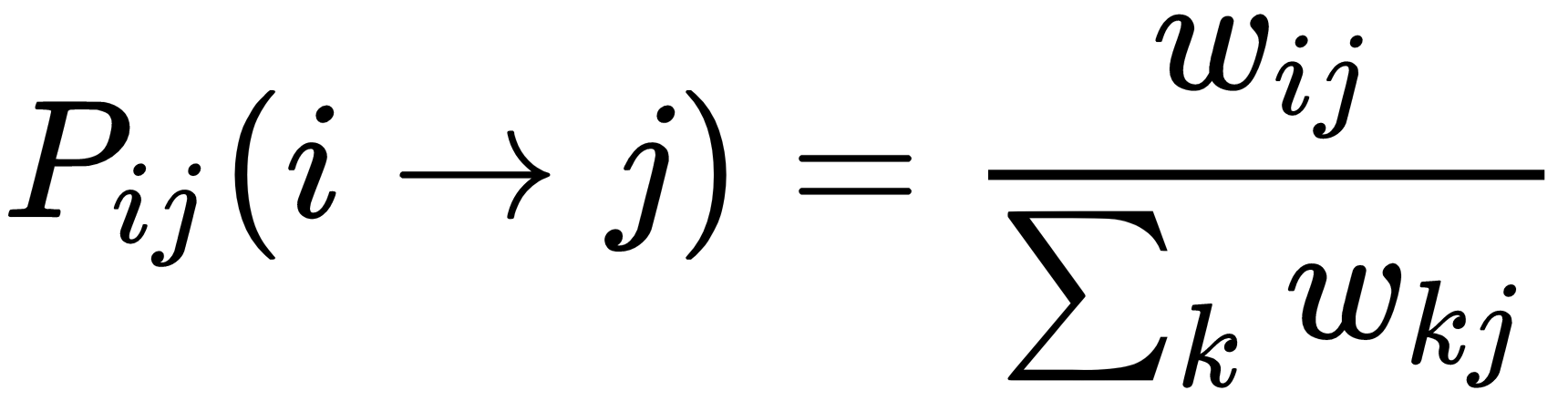
The algorithm operates like a Markov random walk, with the following sequence (assuming that there are Q different labels):
Read now
Unlock full access






