The k-means clustering
The k-means clustering is an unsupervised learning technique that helps in partitioning data of n observations into K buckets of similar observations.
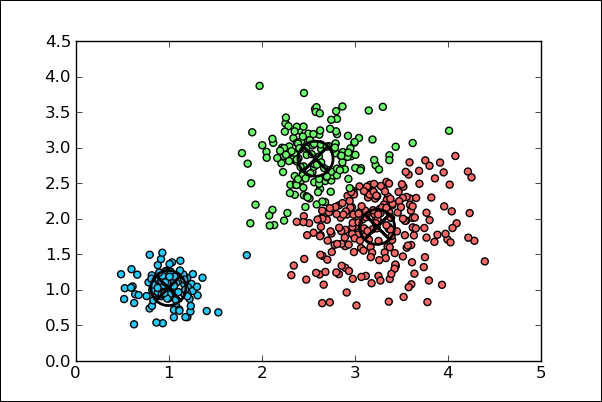
The clustering algorithm is called so because it operates by computing the mean of the features which refer to the dependent variables based on which we cluster things, such as segmenting of customers based on an average transaction amount and the average number of products purchased in a quarter of a year. This mean value then becomes the center of a cluster. The number K refers to the number of clusters, that is, the technique consisting of computing a K number of means, leading ...
Get Mastering Python for Data Science now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

