Chapter 4. Reach-in Reporting AntiPattern
With the microservices architecture style, services and the corresponding data are contained within a single bounded context, meaning that the data is typically migrated to separate databases (or schemas). While this works well for services, it plays havoc with respect to reporting within a microservices architecture.
There are four main techniques for handling reporting in a microservices architecture: the database pull model, HTTP pull model, batch pull model, and finally the event-based push model. The first three techniques pull data from each of the service databases, hence the antipattern name “reach-in reporting.” Since the first three models represent the problem associated with this antipattern, let’s take a look at those techniques first to see why they lead you into trouble.
Issues with Microservices Reporting
The problem with reporting is two-fold: how do you obtain reporting data in a timely manner and still maintain the bounded context between the service and its data? Remember, the bounded context within microservices includes the service and its corresponding data, and it is critical to maintain it.
One of the ways reporting is typically handled in a microservices architecture is to use what is known as the database pull model, where a reporting service (or reporting requests) pulls the data directly from the service databases. This technique is illustrated in Figure 4-1.
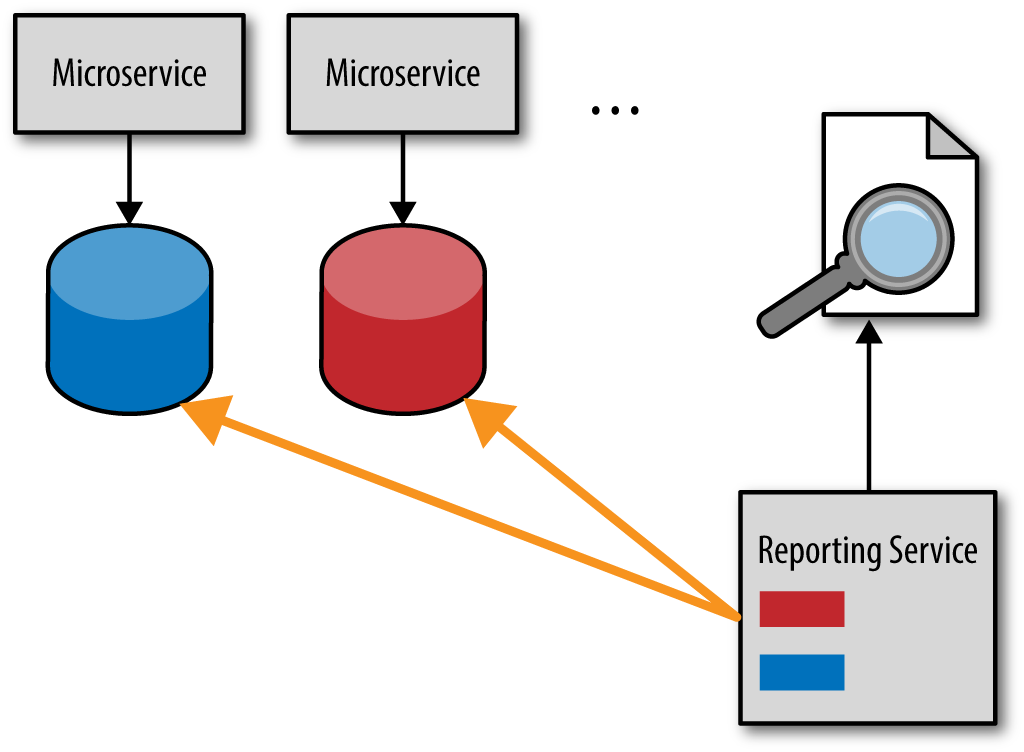
Figure 4-1. Database pull-reporting model
Logically, the fastest and easiest way to get timely data is to access it directly. While this may seem like a good idea at the time, it leads to significant interdependencies between services and the reporting service. This is a typical implementation of the shared database integration style, which couples applications together through a shared database. This means that the services no longer own their data. Any service database schema change or database refactoring must include reporting service modifications as well, breaking that important bounded context between the service and the data.
The way to avoid the issue of data coupling is to use another technique called the HTTP pull model. With this model, rather than accessing each service database directly, the reporting service makes a restful HTTP call to each service, asking for its data. This model is illustrated in Figure 4-2.
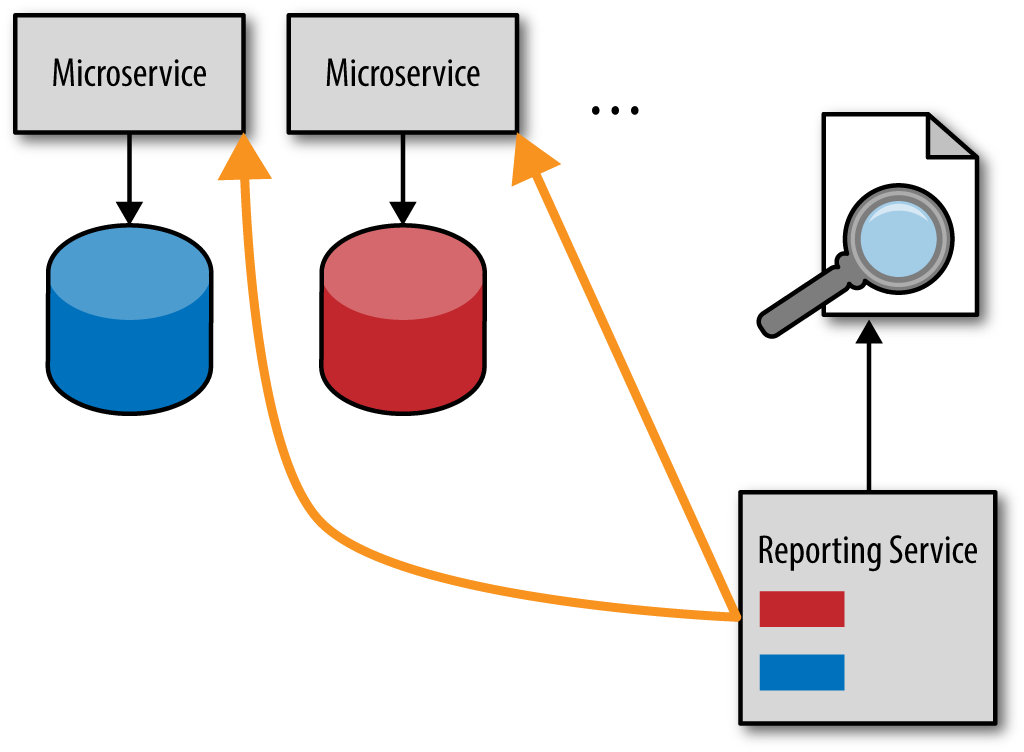
Figure 4-2. HTTP pull-reporting model
While this model preserves the bounded context of each service, it is unfortunately too slow, particularly for complex reporting requests. Furthermore, depending on the report being requested, the data volume might be too large of a payload for a simple HTTP call.
A third option in response to the issues associated with the HTTP pull model is to use the batch pull model illustrated in Figure 4-3. Notice that this model uses a separate reporting database or data warehouse that contains the aggregated and reduced reporting data. The reporting database is usually populated through a batch job that runs in the evening to extract all reporting data that has changed, aggregate and reduce that data, and insert it into the reporting database or data warehouse.
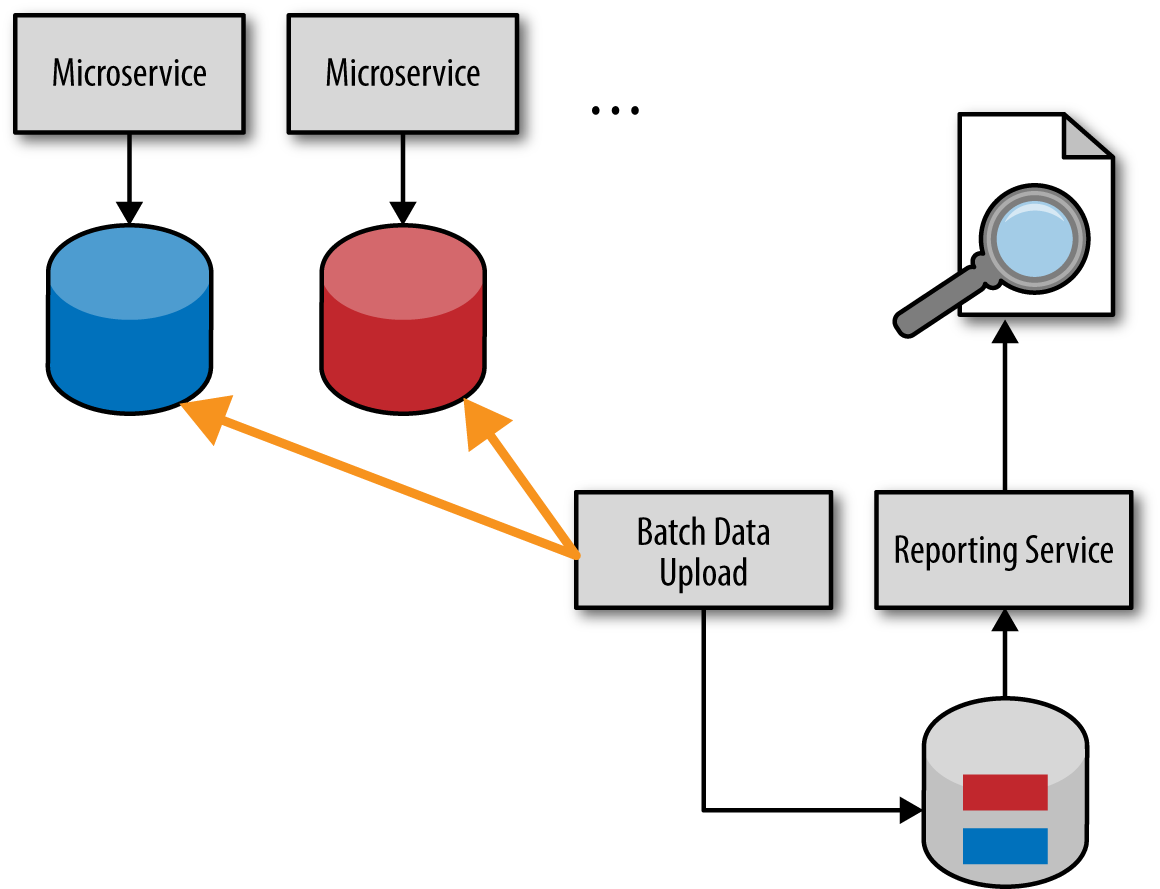
Figure 4-3. Batch pull-reporting model
The batch pull model shares the same issue with the HTTP pull model—they both implement the shared database integration style—therefore breaking the bounded context of each service. If the service database schema changes, so must the batch data upload process.
Asynchronous Event Pushing
The solution for avoiding the reach-in reporting antipattern is to use what is called an event-based push model. Sam Newman, in his book Building Microservices, refers to this technique as a data pump. This model, which is illustrated in Figure 4-4, relies on asynchronous event processing to make sure the reporting database has the right information as soon as possible.
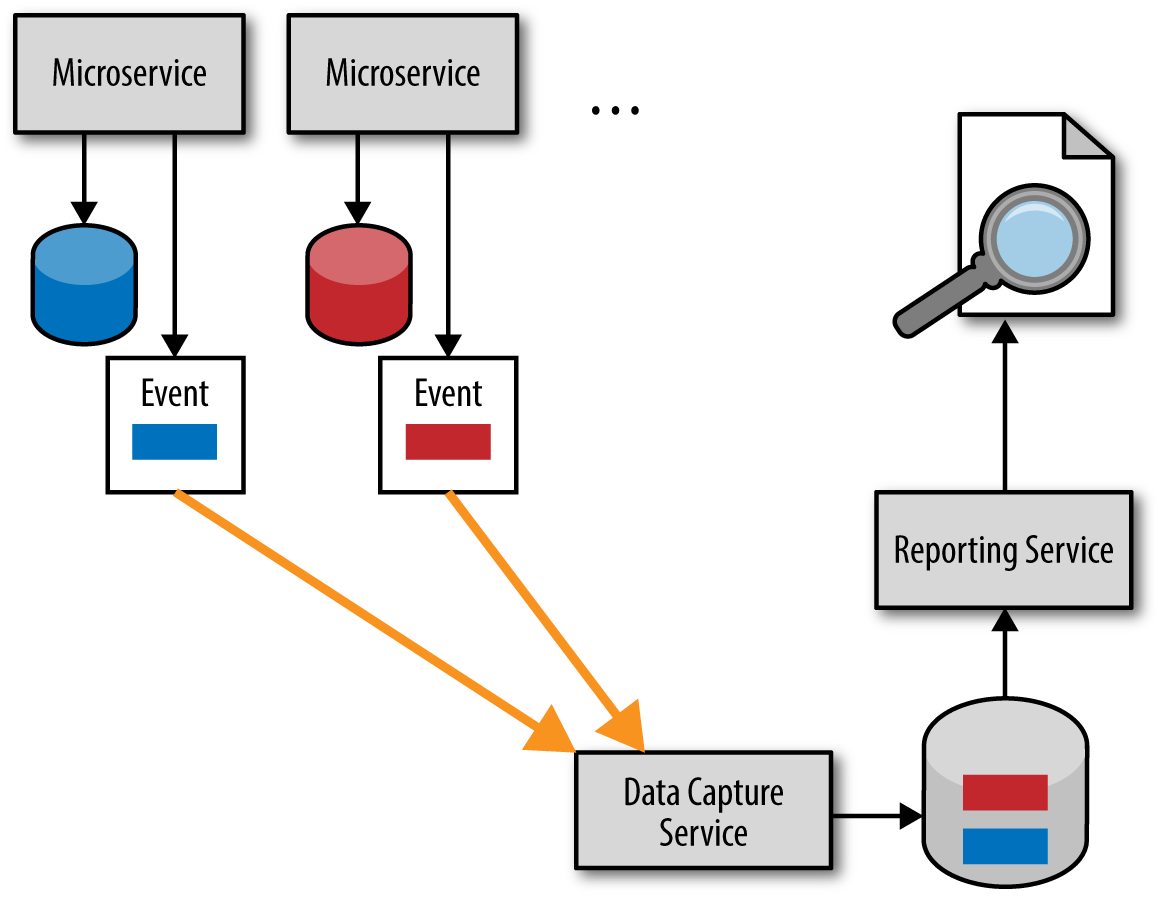
Figure 4-4. Event-based push-reporting model
While it is true that the event-based push model is relatively complex to implement, it does preserve the bounded context of each service while at the same time ensuring a reasonable timeliness of data. Like the batch pull model, this model also has a separate reporting database owned by the reporting service. However, rather than a batch process pulling data, each microservice asynchronously sends its notable data updates (e.g., the data the reporting service needs) as a separate event to a data-capture service, which then reduces the data and updates the reporting database.
The event-based push model requires a contract between each microservice and the data capture service for the data it is asynchronously sending, but that contract is separate from the database schema owned by the service. However, the services are somewhat coupled in that each service must know when to send what information for reporting purposes.
In the chart in Figure 4-5, you can see that the database pull model maximizes on timeliness of data, but breaks the bounded context. The HTTP pull model preserves the bounded context, but has issues associated with timeouts and data volume. The batch pull model turns out to be the least-desirable model out of the four options because optimizes neither the bounded context nor the timeliness of data. Only the event-based push model maximizes both the bounded context of each service and the timeliness of reporting data.
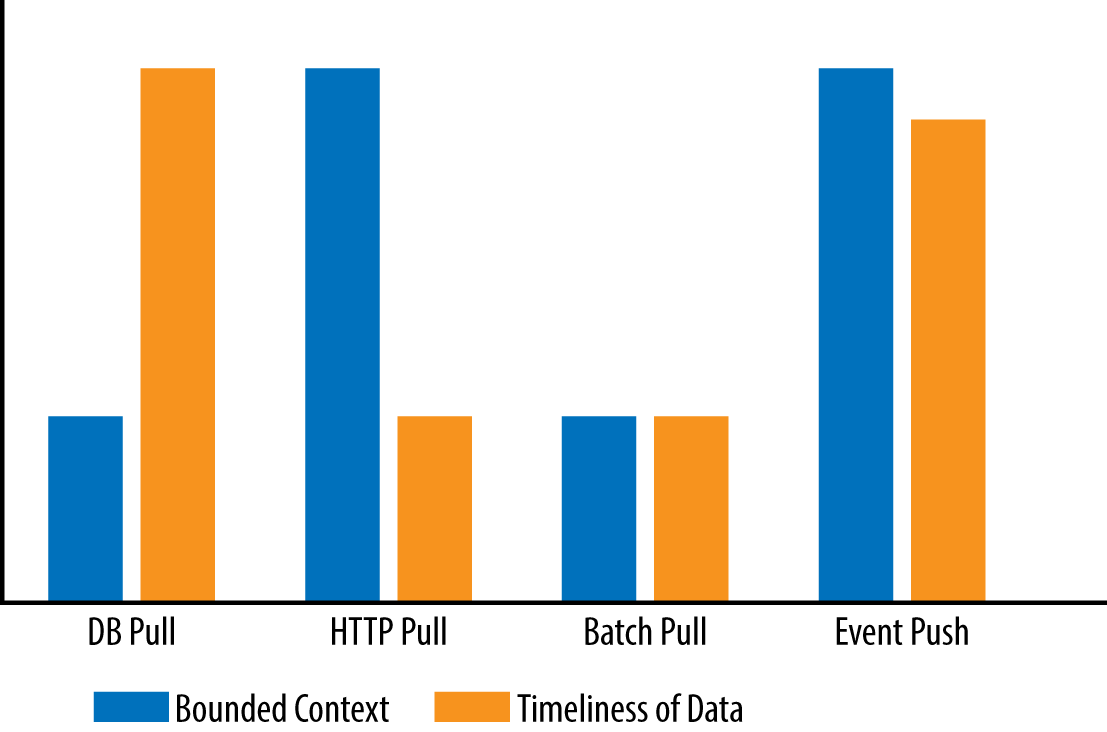
Figure 4-5. Comparing reporting models
Get Microservices AntiPatterns and Pitfalls now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

