Chapter 7. Introduction to the Aggregation Framework
Many applications require data analysis of one form or another. MongoDB provides powerful support for running analytics natively using the aggregation framework. In this chapter, we introduce this framework and some of the fundamental tools it provides. We’ll cover:
The aggregation framework
Aggregation stages
Aggregation expressions
Aggregation accumulators
In the next chapter we’ll dive deeper and look at more advanced aggregation features, including the ability to perform joins across collections.
Pipelines, Stages, and Tunables
The aggregation framework is a set of analytics tools within MongoDB that allow you to do analytics on documents in one or more collections.
The aggregation framework is based on the concept of a pipeline. With an aggregation pipeline we take input from a MongoDB collection and pass the documents from that collection through one or more stages, each of which performs a different operation on its inputs (Figure 7-1). Each stage takes as input whatever the stage before it produced as output. The inputs and outputs for all stages are documents—a stream of documents, if you will.
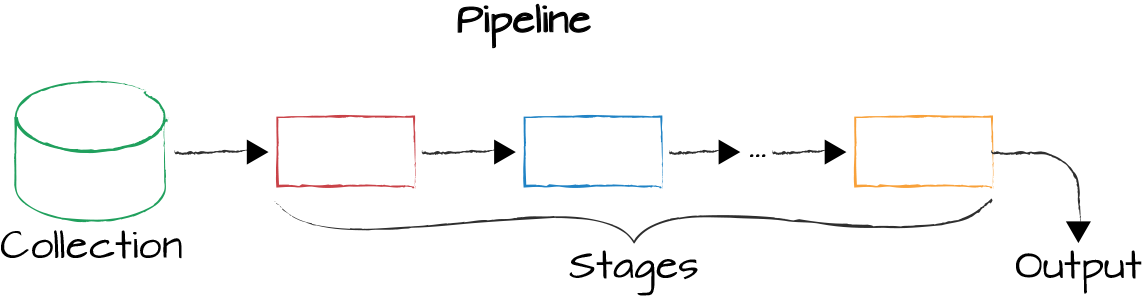
Figure 7-1. The aggregation pipeline
If you’re familiar with pipelines in a Linux shell, such as bash, this is a very similar idea. Each stage has a specific job that it does. It expects a specific form of document and produces a specific ...
Get MongoDB: The Definitive Guide, 3rd Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

