
10.4. PORTABLE SPEECH-TO-SPEECH TRANSLATION 347
Table 10.8 Summary of translation results for tight coupling between recog-
nition and translation (D = lattice density).
BLEU Score Improvement
Baseline 16.8 −
Lattice (D = 3) 14.2 −15.5%
with Acoustic Model (D = 3) 18.0 7.3%
- Length specific 19.5 16.2%
with AC and Source LM (D = 4)
18.9 12.7%
- Length specific 20.5 21.8%
10.4 Portable Speech-to-Speech Translation:
The ATR System
This section describes example-based and transfer-based approaches to
speech-to-speech translation (S2ST) in greater detail and exemplifies their
use in a complete speech-to-speech system—namely, the system developed
at ATR (Advanced Telecommunications Research Institute International)
in Japan. ATR was founded in 1986 as a basic research institute in cooper-
ation with the Japanese government and the private sector, and initiated a
research program on Japanese-English speech-2-speech translation (S2ST)
soon afterward. This program has addressed not only S2ST approaches
proper but also the speech recognition, speech synthesis, and integration
components that are required for a complete end-to-end system. The first
phase of the program focused on a feasibility study of S2ST, which only
allowed a limited vocabulary and clear, read speech. In the second phase,
the technology was extended to handle “natural” conversations in a lim-
ited domain. The target of the current third phase is to field the S2ST
system in real environments. The intended domain of the system is dialog
applications.
While earlier phases of the research program were characterized
by hybrid rule-based and statistical approaches, the current technol-
ogy is heavily corpus-based and uses primarily statistical techniques to
extract information from linguistically annotated databases. The reason
is that corpus-based methods greatly facilitate the development of sys-
tems for multiple languages and multiple domains and are capable of
incorporating recent innovative technology trends for each component.
Domain portability is particularly important, since S2ST systems are often
348 CHAPTER 10. SPEECH-TO-SPEECH TRANSLATION
used for applications in a specific situation, such as supporting a tourist’s
conversation in non-native languages. Therefore, the S2ST technique
must include automatic or semiautomatic functions for adapting to spe-
cific situations/domains in speech recognition, machine translation, and
speech synthesis (Lavie et al., 2001b).
10.4.1 A Corpus-Based MT System
Corpus-based machine translation (MT) technologies were proposed in
order to handle the limitations of the rule-based systems that had formerly
been the dominant paradigm in machine translation. Experience has shown
that corpus-based approaches (1) can be applied to different domains;
(2) are easy to adapt to multiple languages because knowledge can be
automatically extracted from bilingual corpora using machine learning
methods; and (3) can handle ungrammatical sentences, which are common
in spoken language. Corpus-based approaches used at ATR include, for
example, Transfer-Driven Machine Translation (TDMT) (Furuse and Iida,
1994; Sumita et al., 1999), which is an exampled-based MT system based
on the syntactic transfer method. One current research theme is to develop
example-based translation technologies that can be applied across a wide
range of domains, and to develop stochastic translation technologies that
can be applied to language pairs with completely different structures, such
as English and Japanese. Example-based methods and stochastic methods
each have different advantages and disadvantages and can be combined
into a single, more powerful system.
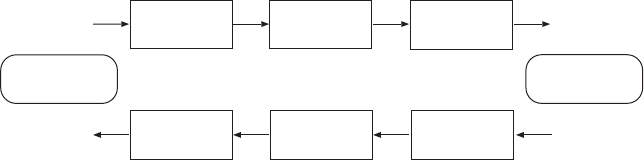
Our overall speech-to-speech translation system is shown in
Figure 10.7. The system consists of three major modules: a multilingual
Speech
Recognition
Speech
Recognition
Machine
Translation
Machine
Translation
Speech
Synthesis
Speech
Synthesis
English/Chinese
Utterances
Japanese
Utterances
Figure 10.7: Block diagram of the ATR S2ST system.
10.4. PORTABLE SPEECH-TO-SPEECH TRANSLATION 349
speech recognition module, a multilingual machine translation module,
and a multilingual speech synthesis module. These modules are designed
to process Japanese, English, and Chinese using corpus-based methods.
Each module is described in more detail below.
Multilingual Speech Recognition
The speech recognition component uses an HMM-based approach with
context-dependent acoustic models. In order to efficiently capture contex-
tual and temporal variations in the input while constraining the number of
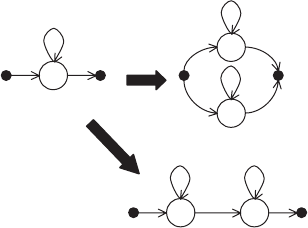
parameters, the system uses the successive state splitting (SSS) algorithm
(Takami and Sagayama, 1992) in combination with a minimum descrip-
tion length criterion (Jitsuhiro et al., 2003). This algorithm constructs
appropriate context-dependent model topologies by iteratively identify-
ing an HMM state that should be split into two independent states. It
then reestimates the parameters of the resulting HMMs based on the stan-
dard maximum-likelihood criterion. Two types of splitting are supported:
contextual splitting and temporal splitting, as shown in Figure 10.8.
Language modeling in the multilingual speech recognizer is performed
by statistical N-gram models with word classes. Word classes are typically
established by considering a word’s dependencies on its left-hand and right-
hand context. Usually, only words having the same left-hand and right-
hand context dependence belong to the same word class. However, this
Contextual Splitting
Temporal Splitting
S
i
a
ii
a
i
1
i
1
a
i
1
i
1
a
i
1
i
2
a
i
2
i
2
a
i
1
i
1
a
i
2
i
2
S
i
1
S
i
2
S
i
1
S
i
2
= 1 −
Figure 10.8: Contextual splitting and temporal splitting.
Get Multilingual Speech Processing now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

