February 2019
Beginner to intermediate
308 pages
7h 42m
English
Let's dive into the dataset to understand the kind of data we are working with. We import the dataset into pandas:
import pandas as pddf = pd.read_csv('diabetes.csv')
Let's take a quick look at the first five rows of the dataset by calling the df.head() command:
print(df.head())
We get the following output:
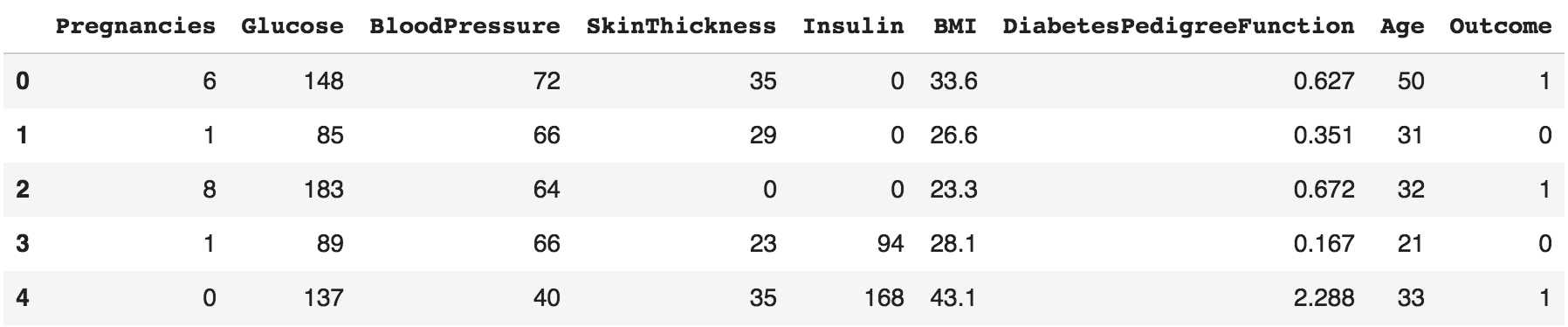
It looks like there are nine columns in the dataset, which are as follows:
Read now
Unlock full access






