Appendix A. Exercise Solutions
Chapter 1: Introduction to Artificial Neural Networks
-
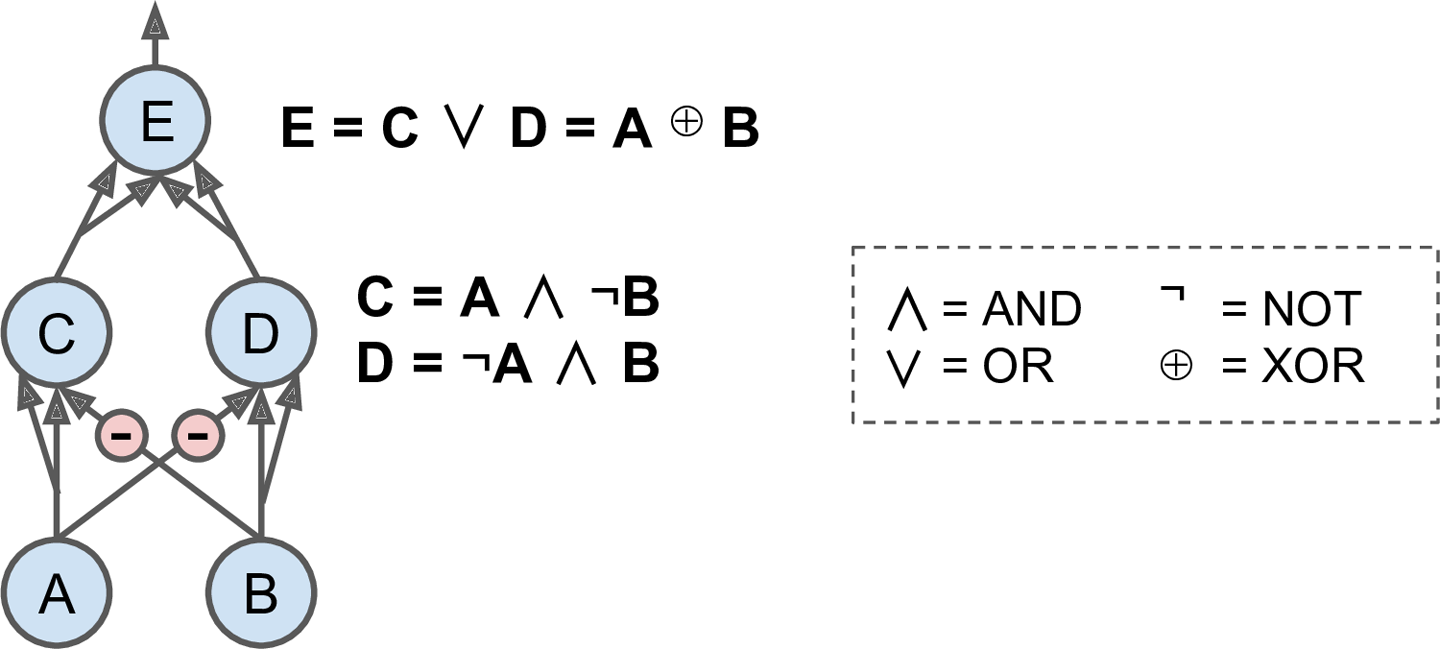
Here is a neural network based on the original artificial neurons that computes A â B (where â represents the exclusive OR), using the fact that A â B = (A ⧠¬ B) ⨠(¬ A ⧠B). There are other solutionsâfor example, using the fact that A â B = (A ⨠B) ⧠¬(A ⧠B), or the fact that A â B = (A ⨠B) ⧠(¬ A ⨠⧠B), and so on.
-
A classical Perceptron will converge only if the dataset is linearly separable, and it wonât be able to estimate class probabilities. In contrast, a Logistic Regression classifier will converge to a good solution even if the dataset is not linearly separable, and it will output class probabilities. If you change the Perceptronâs activation function to the logistic activation function (or the softmax activation function if there are multiple neurons), and if you train it using Gradient Descent (or some other optimization algorithm minimizing the cost function, typically cross entropy), then it becomes equivalent to a Logistic Regression classifier.
-
The logistic activation function was a key ingredient in training the first MLPs because its derivative is always nonzero, so Gradient Descent can always roll down the slope. When the activation function is a step function, Gradient Descent cannot move, as there is no slope at all.
Get Neural networks and deep learning now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

