March 2012
Beginner to intermediate
83 pages
1h 52m
English
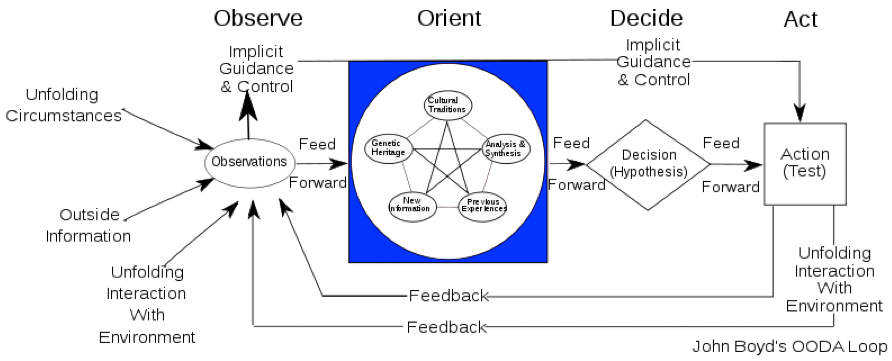
Military strategist John Boyd spent a lot of time understanding how to win battles. Building on his experience as a fighter pilot, he broke down the process of observing and reacting into something called an Observe, Orient, Decide, and Act (OODA) loop. Combat, he realized, consisted of observing your circumstances, orienting yourself to your enemy’s way of thinking and your environment, deciding on a course of action, and then acting on it.

The Observe, Orient, Decide, and Act (OODA) loop. Larger version available here..
The most important part of this loop isn’t included in the OODA acronym, however. It’s the fact that it’s a loop. The results of earlier actions feed back into later, hopefully wiser, ones. Over time, the fighter “gets inside” their opponent’s loop, outsmarting and outmaneuvering them. The system learns.
Boyd’s genius was to realize that winning requires two things: being able to collect and analyze information better, and being able to act on that information faster, incorporating what’s learned into the next iteration. Today, what Boyd learned in a cockpit applies to nearly everything we do.
In our always-on lives we’re flooded with cheap, abundant information. We need to capture and analyze it well, separating digital wheat from digital chaff, identifying meaningful undercurrents while ignoring ...
Read now
Unlock full access







{kind=link}