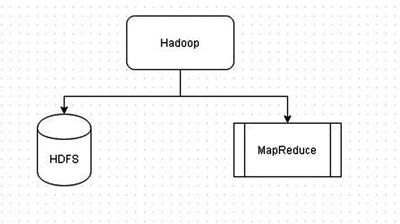
Apache Hadoop is a distributed framework for storing and processing large quantities of data. Going over each of the terms in the previous statement, “distributed” implies that Hadoop is distributed across several (tens, hundreds, or even thousands) of nodes in a cluster. For “storing and processing ” means that Hadoop uses two different frameworks: Hadoop Distributed Filesystem (HDFS) for storage and MapReduce for processing. This is illustrated in Figure 2-1.