Chapter 1. The 11 Deadly Sins of Product Development
Thomas Edison famously said that genius is “1% inspiration, 99% perspiration,” and his observation holds true for product development. Developing “genius-level” (or even mundane) products certainly requires inspiration, but the bulk of the effort is more like perspiration: work that benefits from insight and cleverness but is also largely about not screwing up. Things like ensuring that software doesn’t leak memory and that the right capacitors are used to decouple power supplies. Dotting the i’s and crossing the t’s.
As we noted in the Preface, most product development efforts fail. It’s been my observation that after detailed product design and development begins, failures are not usually due to a lack of inspiration (i.e., poor product ideas) but rather from mistakes made during the “perspiration” part. In other words, most product development failures are good product concepts that fail during the process of turning concept into product.
This chapter is a catalog of the most popular ways to wound or kill product development projects. Most efforts that get derailed do so by stumbling into one or more of a small set of fundamental traps that are easy to fall into—but also fairly avoidable. We’ll briefly review these traps to give an overall feel for the hazards, but not dive into too much detail yet. As you’ll see, much of the rest of this book provides details of strategies and tactics for avoiding them.
Note
A note on organization: my goal is to point out the specific traps that projects run into most often, but these specific traps have base causes that are more fundamental and which should also be avoided. For example, two common traps (new-feature-itis and not knowing when to quit polishing) stem from the general fault of perfectionism. As an organizational construct, in this chapter I refer to the specific traps as sins and the more general negative impulses behind the sins as vices. And because sins are often fatal, I call them deadly sins to remind us of their degree of danger.
Before we get into specific vices and sins, let’s start off with the fundamental principle that lies behind all of these, which is a basic truth that largely determines success or failure.
The Fundamental Principle of Product Development
It’s often the case that complex subjects come from simple truths. For example, the Golden Rule (treat others the way you want to be treated) underpins much or most of religious law. In Physics, we only know of four fundamental forces, but those four forces appear to govern everything taking place in our universe, and have kept many scientists busy for many years filling an untold number of pages.
Similarly, there is a basic truth that applies to product development—really a Fundamental Principle: surprises only get more expensive if discovered later. Putting it another way: product development is largely an exercise in uncovering surprises as soon as possible.
My personal observation is that most of what determines product development success or failure springs from this Fundamental Principle, and much of the rest of this book consists of strategies and tactics for respecting it.
Happy surprises can happen, but surprises that arise during product development are almost always bad, generally along the lines of “You know that nifty power supply chip we’re using in our design? It’s being discontinued.” Or, “It turns out that no vendor can actually mold the enclosure we designed.”
Surprises usually lead to change; e.g., redesigning to use a new power supply chip or to have a moldable enclosure. And change is always easier at the beginning of the development cycle than it is later on.
Many analyses have been performed to find the cost of implementing a product change (either fixing a problem or adding a new feature) versus the stage of the product’s life cycle at which the change is initiated. The results all look something like Figure 1-1, which shows the relative average cost of a fixing an error versus the phase in which the error was caught during development of a major commercial aircraft (taken from a NASA paper). The figure’s dashed blue line shows an exponential curve fitted to the data. As you can see, once development starts in earnest, the cost of making a change typically rises exponentially as development proceeds.
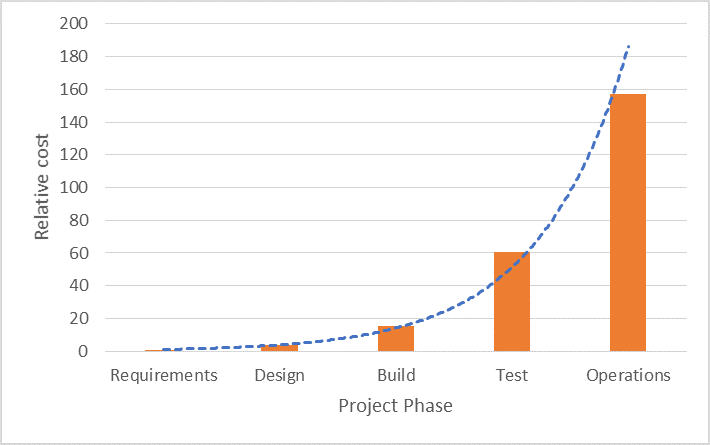
Figure 1-1. Cost of changing a product (due to finding an error) versus time when change is made
To illustrate why this happens, let’s consider the hypothetical case of a robot that performs surgery. The robot’s software will have algorithms that determine the correct ways to drive various actuators (motors) based on the procedure it’s performing. But sometimes algorithms or actuators fail; for example, in certain cases, an algorithm might determine the wrong angle for a scalpel to move, or an actuator might malfunction and not move in the way that’s expected.
To reduce the possibility of injury if such a failure occurs, it might be good to add an independent system of hardware and software to monitor the robot’s actions; in effect, a second set of eyes to make sure that all is working as expected and call for help or halt the procedure if something’s going wrong.
Table 1-1 lays out the relative cost of adding this safety monitoring system, depending on where in the product’s life cycle we initiate the effort:
| Scenario # | When Added | Cost Of Adding |
|---|---|---|
| 1 | During initial specification | Just the cost of implementing and testing the feature. |
| 2 | While initial development is underway | Scenario #1, plus updating already-existing documentation and revising cost estimates; possible redesign of other hardware and code that interfaces with the new hardware and code |
| 3 | After discovering a problem during “final” test, but before product is released. | Scenario #2, plus possibly significant increases in time and cost due to need for an additional cycle of development and testing |
| 4 | After product is released and in use | Scenario #3, plus getting new hardware/software into the field (deployment); possible retrofit of existing customer hardware and software; possible revisions to marketing literature; potential customer frustration because device might be unavailable during upgrade. Wounded company reputation. If devices actually failed in the field because of lack of added safety system, then potential injury, anger, and litigation. |
It’s obvious that the earlier we realize the need for a safety monitor, the less it will ultimately cost to implement. What would have been a relatively modest effort if captured during the specification stage can become very expensive (and make headline news) if realized only after field failures. Discovering surprises late doesn’t just make things a little worse—it makes things exponentially worse.
All changes to products follow the same basic pattern of getting much more expensive with time. An electronics component becoming unavailable after design is completed, for example, requires that we redesign and retest circuitry, and possibly some related mechanical and software changes to address differences in component size, heating, communications protocols, and so forth. Rather than getting surprised down the line, it’s far better to do some legwork during design/development to ensure that we select components that are likely to be available for a long time.
The conundrum here is that no matter how hard we try, we’re unlikely to discover all problems through specification and design—some problems will always rear their heads during build, test, and even (ugh!) once our product is shipping. As we’ll discuss throughout the book (and particularly in Chapter 5 and Chapter 6), many of these types of issues can be resolved through thoughtful iteration back and forth between the various development phases, particularly for those parts of our product that are most likely to generate surprises for us.
Now, with the Fundamental Principle for context, let’s begin our exploration of specific vices and sins that commonly undermine product development.
The Vice of Laziness
Given the Fundamental Principle, it’s pretty obvious that putting off until tomorrow what we can do today is a bad idea, particularly for activities that are likely to uncover surprises. One of the most direct, concrete, and common examples of this vice applies to testing.
Deadly Sin #1: Putting Off “Serious” Testing Until the End of Development
An obvious decision that delays unearthing surprises (and making appropriate changes) is holding off on serious testing until after prototypes are largely developed. By serious testing, I mean the higher-level testing that looks at how usable the product is for our customers (sometimes called product validation), and at how the hardware, software, and mechanical subsystems work together, often called integration test and system test. When neophytes think about product development, they tend to think in terms of “first we’ll build it, then we’ll do all of that high-level testing stuff.” This seems reasonable at first glance, particularly since some high-level testing can be difficult to do until all the pieces are put together. However, this approach delays our finding issues and making needed changes, sometimes big changes, which can be costly.
For example, suppose that usability testing on our “finished” product determines that our audible alert is too wimpy; when designing it, we didn’t realize that users are often in a different room from the product when an important alert sounds, and the audio system we’ve designed (speaker and associated circuitry) doesn’t have enough oomph to get the job done. The fix will likely involve switching to a new speaker and/or updating electronics. Switching to a new speaker might require changing the enclosure size, which can be a substantial effort requiring expensive tooling changes that take weeks. Changing circuitry means new PC boards, which also involve nontrivial costs and lead times. So our “finished” product is (surprise!) not actually very finished, and we find ourselves with weeks or months of unexpected work and delay.
In this instance, much time and expense could have been avoided by early testing of the proposed audio system in real-world settings well before we created enclosure designs, simply to confirm that it can do the job. Or even before going through the exercise of designing our audio system, we could:
-
Review competing products to see how loud their audio is; if they all have really loud speakers, there might be a reason
-
Visit some sites where our product might be used
-
Observe users going about their daily business, perhaps pretending to use our device that doesn’t yet exist
-
Simulate an audible alert using a smart phone and amplified speaker
-
Try some different tones and tone volumes (measured with a decibel meter) to see what’s truly needed to catch a user’s attention
Usability isn’t the only area where early testing helps: early rigorous testing of circuits, software, and mechanicals also ultimately lowers costs and shortens the path through product development.
Note that developing effective tests is not a trivial exercise. More information on this topic can be found in Chapter 5 and Chapter 6.
The Vice of Assumption
When developing a product, we’re assuming that we know the features needed to achieve market success. Until the product goes on sale and the orders pour in (or don’t), we don’t know for sure if our assumptions are good or bad.
There are two common deadly sins that fall under the vice of assumption:
-
Assuming that we know what users want
-
Assuming that users know what they want
Let’s take a short look at each.
Deadly Sin #2: Assuming That We Know What Users Want in a Product
It’s pretty typical for product designers/developers to assume that we know which product features are needed to make the average customer happy. After all, I know what I want—how could other people want something so much different?
This might not be a surprise, but if you’re reading this book, you’re pretty unusual. The odds are that you’re seriously interested in technology, so much so that you want to learn more about how to develop products. Being enthusiastic about technology is a great thing: without people like you and me, humanity would still be hunting and gathering. But, for better or worse, most people are not technophiles like us. To put this in perspective, as I write this, the best-selling “serious technology” book on Amazon is the Raspberry Pi User Guide, ranked at #583 on Amazon. Fully 582 books on Amazon are currently selling better than the best-selling “serious” technology book.
Among other things, we technologists tend to be atypical when it comes to what we want in a product. We like things that have more features and more customizations, and that we can fiddle with for hours. “Normal” folks are mostly interested in getting the job done with a tool that’s effective and attractive. Figure 1-2 illustrates the difference between the tools that these two groups might favor.

Figure 1-2. What technologists typically want (top) versus what “normal” people tend to want (bottom)
So while we have a reasonable shot at knowing what other technologists want in a product, we’re rarely very good at knowing what nontechnologists want, because their wiring is a bit different than ours. There are exceptions to this rule, most famously Apple products, which were developed based on what Steve Jobs and those around him thought their customers wanted. This worked, I think, for two reasons. First, their most notable successes were in developing products for categories that basically didn’t yet exist. Prior to the iPod, asking customers what they wanted in a new MP3 player would not have yielded great information, because almost nobody had one. Second, Steve Jobs was Steve Jobs—a rare person with a vision for human-centered design and great aesthetics, and who understood engineering and engineers.
Assuming that we don’t have a Steve Jobs working for us, there are tactics that we can use that are helpful for discovering what the world’s non-techies want, but they’re not as simple as one might think. This leads us to our next sin.
Deadly Sin #3: Assuming That Users Know What They Want in a Product
Well, if we techies don’t know what typical users want, surely we can just ask them what they want. They should know, right? Sadly, it turns out that users often don’t know what they want. They only know what they think they want.
My dad, a retired market researcher, says in his First Law of Market Research: “If you ask consumers what they want, you’ll get an answer. That answer might be right or it might be wrong, and you’d better find that out!”
I never understood Dad’s First Law until I started developing products. It was then that I found that it’s entirely possible to deliver what customers have asked for without satisfying their needs. This leads to nifty conversations like this:
User: “I can’t use this!”
Developer: “But it meets all of the requirements we agreed to!”
User: “But now that I’m actually using it, I’m finding that it doesn’t really get the job done.”
Very frustrating and disappointing to everyone involved!
It turns out that what potential users see in their minds’ eyes when envisioning a new product might be very different than the reality once a product is in their hands. Finding out what users really want is largely a function of letting them try things out (features, prototypes, etc.) and seeing if they’re happy; it follows that we should start giving them things to try as early as possible instead of waiting until the end and praying that our assumptions (or theirs) were correct.
The Vice of Fuzziness
Fuzziness, or lack of specificity in planning a product and its development effort, is a major source of project failure. There are two big challenges introduced by fuzziness:
-
Stakeholders have differing expectations as to what will be developed.
-
It’s rather difficult (OK, fairly impossible) to estimate the resources and time needed to complete development if we don’t know the product’s details, at least to some degree.
There are three deadly sins that fall under fuzziness:
-
Not having detailed requirements
-
Not having a detailed project plan
-
Not knowing who’s responsible for accomplishing what during development
Let’s examine these in a little detail.
Deadly Sin #4: Lack of Comprehensive Requirements
Product requirements are how we communicate our understanding of what a product will be. They ensure that all stakeholders have the same understanding of a product’s important attributes. When creating product requirements, we must work to capture everything that’s important to our customers and us; otherwise, the results might be different from what we wanted.
Here’s an example of the kind of thing that happens often: Marketing writes requirements along the lines of:
-
The product shall have four wheels
-
The product shall have a motor
-
The product shall be steerable
-
The product shall have an engine
-
The product’s engine shall use gasoline
-
The product shall be legally operable on all roads in the US, and in countries A, B, and C
-
The product shall be attractive
Being practical sorts who are attracted to quirky designs, the designers/developers go off and build something that they believe will efficiently meet these requirements. Unfortunately, Marketing had a somewhat different product in mind. The difference in the visions of these two groups is captured in Figure 1-3.

Figure 1-3. What Marketing wanted, versus the interpretation by designers/developers
Great interdepartmental entertainment ensues, rarely with a happy ending.
While this auto example is obviously an exaggeration, it underscores the basic issue: requirements are how we make sure that everyone’s on the same page with regard to what’s being produced. We must be careful to include everything that’s important to us or we’ll end up with (usually unwelcome) surprises. In this car example, some additional requirements from Marketing would have helped create a better outcome; for example, “greater than 80% of Target Market shall agree that the adjective ‘sexy’ applies to the product’s design.”
In addition to stakeholders being surprised/disappointed with the final product, a lack of comprehensive requirements also guarantees feature creep, another deadly sin (covered later), since we won’t have all the features defined before we develop our product. If we decide on and implement features as we develop, there can be a lot of reengineering of interdependent systems to accommodate our newly discovered needs.
Deadly Sin #5: Lack of a Good Project Plan
Project plans! I can hear your groans as I write this.
For most of us, creating a project plan is as much fun as filling out a tax return, and following them is as enjoyable as getting a root canal.
Adding insult to injury, product plans are also inevitably inaccurate at laying out how we’ll proceed on a project: things rarely go according to plan for very long. Even on projects that are relatively straightforward, stuff happens, and early assumptions turn out to be wrong. Key people leave the project temporarily or for good. A component vendor decides to withdraw from the US market. Designs turn out to be way trickier than anticipated. Management suddenly decides that the product is needed three months earlier. And so forth.
Project plans are painful and inaccurate. So why bother?
General Dwight Eisenhower got it right: “Plans are worthless, but planning is everything.” While specific plans are inevitably broken by the end of the first week of work, spending substantial time and effort in the planning process is indispensable. I find project planning to be as un-fun as anyone, yet I’m very uncomfortable working on projects of any significant size without a very detailed project plan, usually with hundreds of defined tasks, including resources (who, what), person-hours (how long), costs, and dependencies assigned to each line item. While I absolutely know that much of the plan will turn out to be wrong, having a detailed plan at least gives me a prayer of being in the right ballpark for estimates of time and effort, and tracking progress (are things going faster or slower than we thought?).
Creating a detailed project plan forces us to think through issues that are easy to miss when we’re planning by taking a rough stab. It helps us to remember important details we’d otherwise forget about (“Oh yeah, we should add a week for preliminary FCC certification testing and subsequent design tweaks before final prototype build.”), and to understand dependencies (“Looking at the plan, it seems we have a problem! It’ll take 10 weeks to have molds made, which pushes production until way after the trade show where Marketing wants to announce we’re on sale. We’d better figure out how to get the molds made in a shorter time, or how to be ready to start making the molds earlier.”)
Oh, that’s why it took so long!
Ever notice that most projects take twice as long and cost twice as much as projected? As compared to quick guesstimates, I’ve found that detailed initial project plans end up showing that projects will cost twice as much and take twice as long—and are much closer to being accurate. Being off by a factor of two is always big trouble and in a small company or startup with limited resources, it can spell doom.
Deadly Sin #6: Not Assigning Responsibility
Simply creating a task on a project plan with a due date and a budget doesn’t ensure that the task actually gets done by its due date and within budget. One common problem is that when the time comes to start a task, we find that a detail’s been missed in the project plan that prevents work from starting on time, and we now have a surprise that impacts budget and timeline. Then once a task begins, there can be confusion around who gets what part done, and how multiple parts come together.
Adding an owner to each task greatly increases the odds of success. The task owner is not necessarily the person who accomplishes the task, but rather is responsible for timeline, budget, communications, and making sure the thing gets done. This helps in a couple of ways, which we’ll explore here.
First, it guards against gaps in the project plan. One of the ubiquitous imperfections in project plans is simply missing some tasks and details: there’s a task that needs to get done but we forgot to add it to the project plan. Throughout the project, each task’s owner can (and should) keep an eye on that task’s prerequisites to make sure that everything’s falling into place for things to happen according to schedule and budget. Any issues discovered that could affect either schedule or budget should be communicated and worked out, and the project plan updated as necessary.
Second, there’s no confusion over who will make sure that a task gets completed—no “Wait, I thought you were going to take care of that!”
For example, when performing testing to gain FCC certification, it’s necessary (or at least extremely useful) to have a special test software application running in our product that sequences the hardware into different states, one by one, so the radio frequency (RF) emissions in each state can be measured with little or no futzing around with the product. The task to create this test application is easy to forget about, and is sometimes missing from the initial project plan. If we forget about the test app until we show up to our testing appointment, we might not be able to complete testing in time, and the project will slip a few days or even weeks while an app gets slapped together and we find the next available time slot for testing.
By contrast, if someone owns the FCC testing task, there’s a good opportunity to avoid the slip. For example, if Sue knows that she’s responsible for that task, she can call the test house months ahead of the scheduled testing, and ask what she needs to do to ensure that testing starts on the right date and proceeds smoothly. Among other things, the test house will tell her that they want a test app. “A-ha! We forgot that on the project plan!”, Sue tells the project manager, and the task is added, resources assigned, and the project plan updated.
The Vice of Cluelessness
The vice of cluelessness covers those things we have no inkling of. Since we don’t even know what to worry about, we’re in a state of blissful unawareness until we smack into a problem late in the game, sometimes even after product release, which can require product changes.
A great mitigation for cluelessness is to rely on people with experience in the technical and nontechnical areas that our product touches, either as employees or advisors. They’ve walked the walk and know where the potholes are located.
Another mitigation is to read this book: one of my primary goals in writing it is to flag issues that tend to blindside product development efforts.
Of course, there are all manner of things that we can potentially not know about. But there’s one area that tends to cause the most trouble, which I’ll touch on next: keeping governments happy.
Deadly Sin #7: Not Addressing Regulations
The classic and common example of getting stung by cluelessness is smacking into government regulations after design is complete, such as finding out that US Customs is holding up shipments to Europe because our product doesn’t meet relevant EU requirements, or merely because our CE mark labeling isn’t being displayed correctly.
Generally speaking, for most products sold in significant quantity, there are really two basic classes of requirements that our product must address. There are the “standard” requirements based on business needs, which are driven by what customers want (e.g., functionality, size, color) and by what our business wants (e.g., profitability, design language consistent with other devices we sell).
There’s also a second class of requirements (regulations, standards, and certifications) that are imposed upon us by external parties such as governments and sometimes others such as insurers. This second class of requirements, which we’ll call imposed requirements, generally addresses product safety but can also address product performance (e.g., a measuring cup sold in Europe might need to prove it achieves a certain level of accuracy). We’ll cover this class of requirements in some detail in Chapter 10.
These imposed requirements are easily missed during product development as many people aren’t even aware they exist. And even if we’re generally aware they exist, it can be a challenge to find the ones that apply to our specific product: different governments have different regulations, and different parts of the government have different regulations (hopefully not conflicting ones!). In some industries, products have standards effectively imposed on them by insurers and other groups, and these standards might require some research to identify.
Because unawareness of imposed requirements is so pervasive, and navigating them is not a trivial undertaking, this area gets a chapter of its own later on. But for now, some examples of common imposed requirements include:
-
Federal Communications Commission (FCC) regulations that must be met by virtually all electronic devices marketed in the US. In fact, most electronic devices must be tested and certified by a third-party lab prior to being sold in the US. Other countries have similar regulations.
-
Underwriters Laboratories (UL) marking. UL is an independent body that tests all sorts of devices to see if they are safe. Many devices that pose potential safety issues carry a UL Mark, earned by having UL test the product and the factory according to specific standards to ensure the product is safe for consumers. UL listing is quasi-voluntary: no law requires it, but some laws might be satisfied by it, and certain customers and insurers might require it.
-
Conformité Européenne (CE) marking. CE marking indicates that a product conforms to all relevant European Union (EU) regulations. Different types of products must conform to different sets of regulations. By law, the vast majority of products sold within the EU must have CE marking.
Figure 1-4 shows the product labeling associated with these three imposed requirements. Note, however, that most imposed requirements do not have associated product markings.

Figure 1-4. FCC, UL, and CE marks
The Vice of Perfectionism
Beyond the normal impulse that each of us has to do our job well, product development adds an extra incentive that pushes toward perfectionism: our work will be judged by many people, perhaps even millions in the case of successful consumer products. There’s the opportunity for much glory and wealth if we get it right, and conversely much embarrassment and the loss of money if our product disappoints. These are high stakes, which can lead to mistakes. Let’s take a look at some things that can go wrong when we become too obsessed with making the perfect product.
Deadly Sin #8: The Sin of New-Feature-Itis
New-feature-itis is the natural inclination to add cool new features as a project progresses. Obviously, this behavior directly violates the Fundamental Principle of Product Development, but this particular flavor of violation is worth reviewing because it illustrates some of the specific penalties we might pay.
“Hey! Wouldn’t it be cool if the product had [fill in cool feature here]?” is probably the most critical—and most dangerous—exclamation in product development. Whether it’s a positive or a negative is determined by how and when it’s spoken.
At the very beginning of a product development effort, during requirements definition, “Wouldn’t it be cool if...” is our best friend. At this stage, we’re trying to get as many cool ideas on the table as we can. This is the time when we should talk to prospective users, research similar products, and perform other activities to develop a list of as many potential features as possible. Once we have this list, we’ll ruthlessly cut it down to a “final” set of features (i.e., requirements) based on the value that each feature adds to the product versus the cost/risk of implementing that feature.
Once the requirements are locked down, we can create pretty good estimates for development timeline and budget, and get going with the fun part of development: making stuff.
As we know, adding new features once the requirements are locked down will obviously introduce additional time and cost to development. But beyond the obvious cost of “that’s a cool idea; I can add that to the firmware in a week” (which often turns into several months), adding features can (and will) cause additional work in ways that aren’t always obvious:
-
New features can inadvertently break other features.
-
New features often require changes to basic architecture, changes that can be kludgy because the new feature was not at all anticipated in the original architecture. As patches are added to support new functionality, the architecture can become brittle and easier to break.
-
Test effort usually increases exponentially with the number of features that a product supports due to interrelationships between features. Adding a few little features might result in a lot of extra testing.
All told, feature creep is a major contributor to delays and cost overruns.
Steve Jobs had a great quote that applies:
“People think focus means saying yes to the thing you’ve got to focus on. But that’s not what it means at all. It means saying no to the hundred other good ideas that there are. You have to pick carefully. I’m actually as proud of the things we haven’t done as the things I have done. Innovation is saying no to 1,000 things.”
It’s best to pick a limited feature set at the start of a project, be skeptical about adding new features during development, and focus on making those few features work really, really well. Compared to implementing more features with less polish per feature, we’ll get to market faster and cheaper, and most customers will like our product more.
Deadly Sin #9: Not Knowing When to Quit Polishing
The longer we polish a stone, the smoother it will become. There comes a time when we should declare that the stone is smooth enough and move on.
Similarly, we can always make products more polished; it just takes more time and effort. There are always workflows that are a bit awkward, screen layouts that look a bit off, ways to squeeze another few minutes of battery life if we just tweak things a bit, and so forth.
But while we’re spending that time and effort, other things are happening. End users are being deprived of a product that could be improving their lives, even if that product could be made a little better with a little more time. Budgets are being depleted, and revenues are not being generated. Competitors might be releasing products that will grab market share. Time is rarely our friend here.
So there comes a time when the product isn’t perfect—it never is—but it’s ready to release.
What about thoughts about how we can do things better? As long as our product sells well, we’ll use those thoughts to make our next-generation product even better for our customers. In the case of software, there can be an opportunity to issue updates to a product that’s already in the field.
That’s not to say that we should release crummy products as soon as possible, at least not to regular paying customers. A crummy product might help as a stopgap in the short term, but it can also unacceptably damage our reputation or brand in the process. Finding the line between good enough to ship and this might embarrass us is rarely a trivial task; if it doesn’t evoke some passion, anguish, and argument among the folks making this decision, then they’re probably not doing it right.
A little joke
Two guys are camping in the African Savanna when they spy a lion charging toward them from a distance. Frantically, one of the guys starts taking off his hiking boots and putting on his running shoes.
Surprised, the other man says, “What are you thinking? You can’t outrun a lion!”
“I don’t have to outrun the lion,” said the man lacing up his running shoes, “I just have to outrun you.”
Similarly, let’s remember that we don’t have to build the perfect product: just one that’s good, that’s more attractive to customers than the alternatives, and that supports our big-picture marketing strategy.
The Vice of Hubris
This vice has to do with believing that things will go according to plan.
It’s easy (and important) to be confident at the start of the project. We have a detailed project plan in hand that looks reasonable and has been reviewed by a number of smart people; what can go wrong?
Here’s my promise to you: we’ll find out what can go wrong once development begins. Boy, will we find out. Any bubble of pride that we hold for our ideas and project plans at the start of a project will be punctured quickly once “real” design/development commences. We will fail early, we will fail often, and the measure of a successful effort lies largely in how failures are dealt with.
Deadly Sin #10: Not Planning to Fail
In Deadly Sin #5, I argued the importance of a creating a detailed project plan. Compared to gut feel and rough guesses, a detailed project plan at the start of development is a much better predictor of what our effort will look like. But even a carefully crafted detailed project plan will be wrong, and it will be optimistic, and this should be accommodated realistically.
We must plan to fail.
Since we’re planning to deal with surprises, and since surprises are—by definition—unknown, it’s impossible to know for sure how much effort they’ll take to mitigate. In my experience, even detailed timelines and budgets prepared by highly experienced people should be padded by 20%–30% to account for the inevitable bad surprises. If the folks preparing the initial project plan are not very experienced, or there are seriously new technologies involved, it’s easy for a project to end up 100% or more over budget.
Unfortunately, padding a project plan and budget is often easier said than done, particularly when presenting estimates to inexperienced managers: “You want to add 25% for I-don’t-know-what?” In these instances, it’s good to have a list of significant project risks on hand to demonstrate why we should plan for the unknown. The list will probably not be short, and reviewing the specific concerns is usually more persuasive than padding with a percentage that seems to be pulled out of thin air.
The Vice of Ego
This vice is about valuing customer desires less than our own. Other than “labors of love,” successful products, and successful product development efforts, are about what customers want. It’s not about what we personally want. Doing work in large amounts that we don’t enjoy is no good, of course, so the trick is to bring together people who’ll enjoy playing the roles that are needed to maximize customer satisfaction. Let’s look at a common trade-off that’s often made badly when what we enjoy competes with what’s best for the product and customer.
Deadly Sin #11: Developing Technology Rather Than Developing Products
Most technologists, particularly product developers, love to create new stuff. We tend to think of our jobs in terms of developing new technology. But developing technology and developing products are different things (although they certainly overlap). In particular, when developing products, developing technology is largely optional. We can choose to create technology for our product, or in many cases we can choose to integrate existing technologies. If the product can be developed quicker/cheaper/better by integrating existing technology (and it usually can be), then that’s the way to go.
Think for a moment about Apple and Microsoft, two companies that have been extraordinarily successful at developing products. It could be argued that neither has developed revolutionary technology; they’ve only developed revolutionary products. Both Apple and Microsoft snagged from Xerox the concept of an operating system that uses windows and a mouse. Apple’s current operating systems, Mac OS X and iOS, are both based on the open source FreeBSD. MS Windows originally ran on top of MS-DOS, which was originally QDOS licensed from Seattle Computer Products. Excel and Word started as knockoffs of Lotus 1-2-3 and WordPerfect, respectively, to a greater or lesser degree. Apple’s vaunted Siri was originally actually purchased from Siri, Inc. And so on.
Certainly, both Apple and Microsoft have plenty of resources to create new technology from scratch, and I’m sure they were tempted to do so in all these cases. What made Microsoft and Apple so successful, in large part, is that they focused on meeting the needs of their customers rather than on developing technology. They’re quite content to purchase or otherwise adopt existing technologies if that’s what will do the best job of getting great solutions to their customers.
To develop great products with reasonable effort, it’s important to adopt the Apple/Microsoft mindset: “What’s best for our customers?” And this mindset isn’t unique to these two companies; it’s ubiquitous across very successful companies that develop new products.
Final Thoughts
As mentioned in the Preface, only 1 in 20 new consumer products are a success. This chapter’s been a rogues’ gallery of some of the major gotchas, which in my experience can reliably turn fantastic product concepts into members of the failed 19-out-of-20.
The first step in winning the fight is to recognize the enemy, and I hope this chapter has served in this capacity. If you’re new to product development, perhaps it’s also served as an introduction to some of the higher-level issues that we face: product development is about great hardware and software, of course, but creating this hardware and software requires a good bit of planning, psychology, communications, compliance with regulations, and a host of details that we need to get right.
Of course, just knowing what can go wrong isn’t enough: we also need to know how to avoid, fix, or at least mitigate the problems that can arise, which is the goal of most of the rest of this book. In future chapters, we’ll be getting pointed and practical about charting the best way through the icebergs, so that our product has a much better shot at being one of the 1-in-20 product development successes.
Resources
This chapter’s been about fundamental truths and common ways to fail. Here are a few books on that theme that have been helpful to me—perhaps they’ll be useful to you as well:
-
The Lean Startup: How Today’s Entrepreneurs Use Continuous Innovation to Create Radically Successful Businesses by Eric Ries. The premise here is that we never quite know what will work when developing new products, so it’s best to fail early and often, learning from each iteration of failure (and success) to move in a better direction.
-
The Mythical Man-Month: Essays on Software Engineering by Frederick P. Brooks. A classic book published in 1975 but no less relevant today, it covers many of the basic truths of software development, most famously Brooks’ Law: adding manpower to a late software project makes it later.
-
Systemantics: How Systems Work and Especially How They Fail by John Gall. Great tongue-in-cheek coverage of what goes wrong when working with large systems, be they machinery or people. Older and out of print, but can be picked up used for short money.
Here’s a fun (and basically-true) illustration of the misunderstandings that can crop up in product development.
Get Prototype to Product now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.


{kind=link}