At the beginning of this chapter, we discussed the concept of generic target function so as to optimize in order to solve a machine learning problem. More formally, in a supervised scenario, where we have finite datasets X and Y:
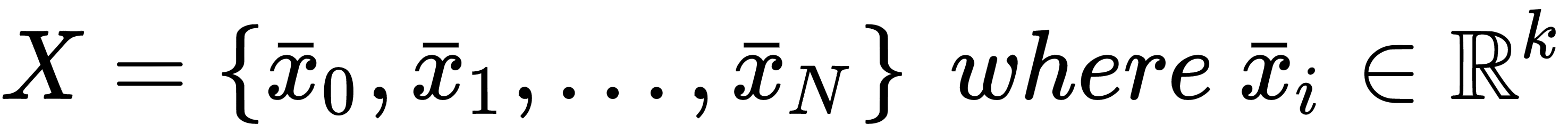
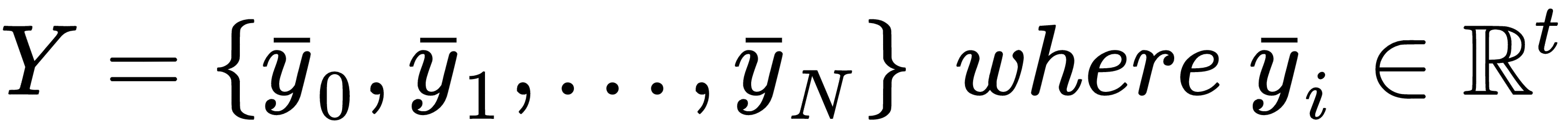
We can define the generic loss function for a single sample as:
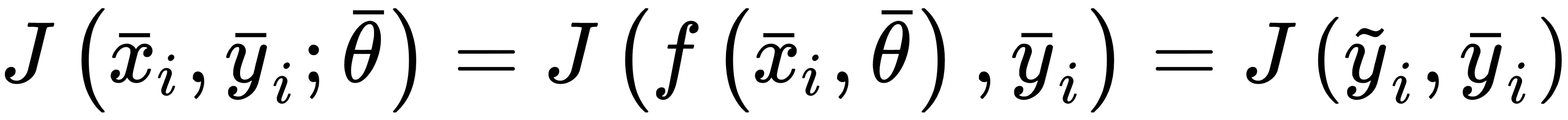
J is a function of the whole parameter set, and must be proportional to the error between the true label and the predicted. Another ...

