December 2022
Beginner to intermediate
588 pages
13h 43m
English
Up until now, we have been looking in depth at supervised learning estimators: those estimators that predict labels based on labeled training data. Here we begin looking at several unsupervised estimators, which can highlight interesting aspects of the data without reference to any known labels.
In this chapter we will explore what is perhaps one of the most broadly used unsupervised algorithms, principal component analysis (PCA). PCA is fundamentally a dimensionality reduction algorithm, but it can also be useful as a tool for visualization, noise filtering, feature extraction and engineering, and much more. After a brief conceptual discussion of the PCA algorithm, we will explore a couple examples of these further applications.
We begin with the standard imports:
In[1]:%matplotlibinlineimportnumpyasnpimportmatplotlib.pyplotaspltplt.style.use('seaborn-whitegrid')
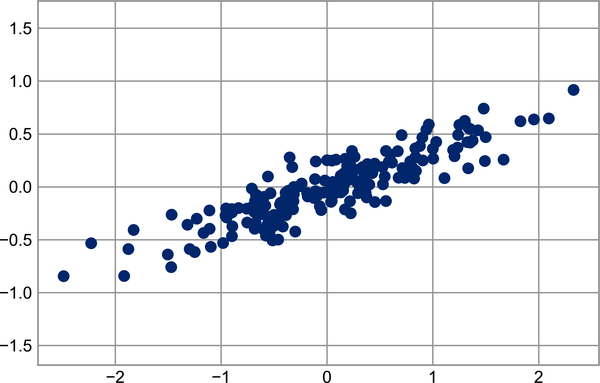
Principal component analysis is a fast and flexible unsupervised method for dimensionality reduction in data, which we saw briefly in Chapter 38. Its behavior is easiest to visualize by looking at a two-dimensional dataset. Consider these 200 points (see Figure 45-1).
In[2]:rng=np.random.RandomState(1)X=np.dot(rng.rand(2,2),rng.randn(2,200)).Tplt.scatter(X[:,0],X[:,1])plt.axis('equal');
Read now
Unlock full access






