April 2017
Intermediate to advanced
406 pages
10h 15m
English
Imagine that we have an agent who will be moving through a maze environment, somewhere in which is a reward. The task we have is to find the best path for getting to the reward as quickly as possible. To help us think about this, let's start with a very simple maze environment:
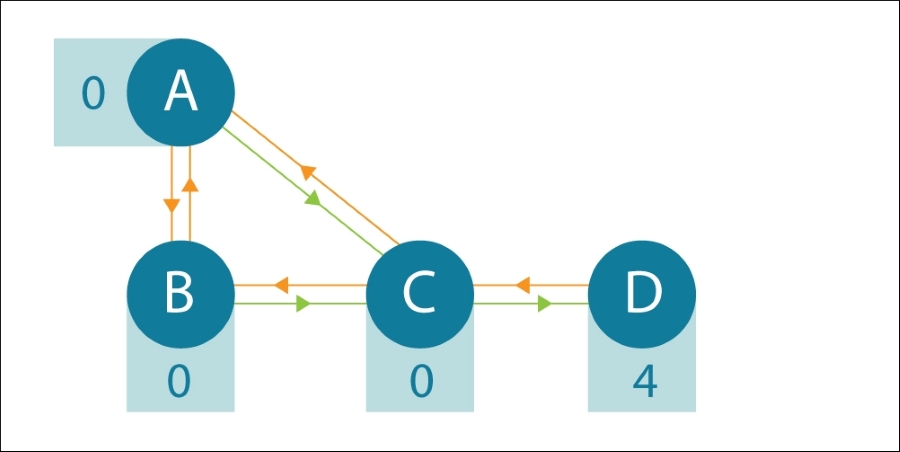
Figure 2: A simple maze, the agent can move along the lines to go from one state to another. A reward of 4 is received if the agent gets to state D.
In the maze pictured, the agent can move between any of the nodes, in both directions, by following the lines. The node the agent is in is its state; moving along a line to a different node is an action. There is a reward ...