Having developed our own k-means clustering model, we can now learn how to use scikit-learn for a quicker solution by performing the following steps:
- First, import the KMeans class and initialize a model with three clusters as follows:
>>> from sklearn.cluster import KMeans>>> kmeans_sk = KMeans(n_clusters=3, random_state=42)
The KMeans class takes in the following important parameters:
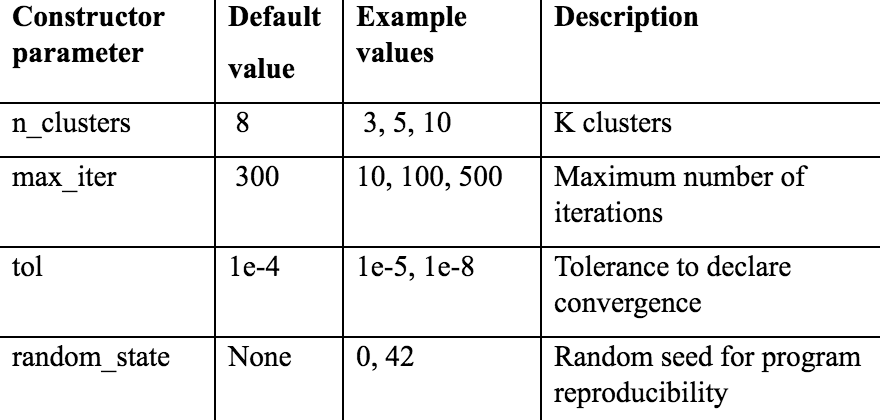
- We then fit the model on the data:
>>> kmeans_sk.fit(X)
- After that, we can obtain the clustering results, including the clusters for data samples and centroids of individual clusters:
>>> clusters_sk = kmeans_sk.labels_ ...

