November 2017
Beginner to intermediate
366 pages
7h 59m
English
This is the product of a term frequency and inverse document frequency:
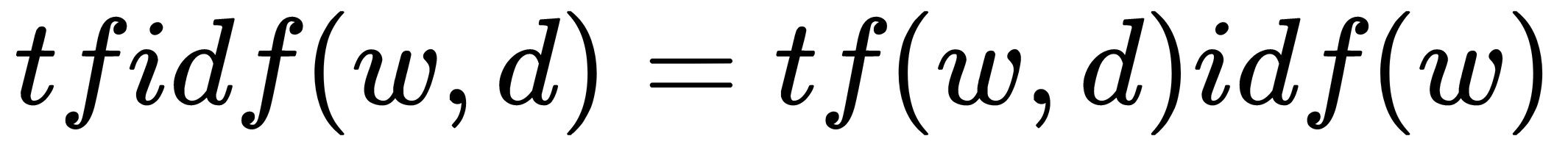
TFIDF is a very popular weighting metric used in text mining.
To begin with, we separate our data into two data frames:
> title.df <- data.subset[,c('ID','TITLE')]> others.df <- data.subset[,c('ID','PUBLISHER','CATEGORY')]
title.df stores the title and the article ID. others.df stores the article ID, publisher, and category.
We will be using the tm package in R to work with our text data:
library(tm)title.reader <- readTabular(mapping=list(content="TITLE", id="ID"))corpus <- Corpus(DataframeSource(title.df), readerControl=list(reader=title.reader))
We create a ...
Read now
Unlock full access






