2Location and Scale
2.1 The location model
For a systematic treatment of the situations considered in Chapter 1, we need to represent them by probability‐based statistical models. We assume that the outcome ![]() of each observation depends on the “true value”
of each observation depends on the “true value” ![]() of the unknown parameter (in Example 1.1, the copper content of the whole flour batch) and also on some random error process. The simplest assumption is that the error acts additively:
of the unknown parameter (in Example 1.1, the copper content of the whole flour batch) and also on some random error process. The simplest assumption is that the error acts additively:
where the errors ![]() are random variables. This is called the location model.
are random variables. This is called the location model.
If the observations are independent replications of the same experiment under equal conditions, it may be assumed that
 have the same distribution function
have the same distribution function 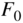
 are independent.
are independent.
It follows that are independent, with common distribution function
and we say that the are i.i.d ...
Get Robust Statistics, 2nd Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

