August 2021
Intermediate to advanced
799 pages
17h 41m
English
Most likely, one of the first steps on your Scala 3 journey will involve working at the command line. For instance, after you install Scala as shown in “Installing Scala”, you might want to start the REPL—Scala’s Read/Eval/Print/Loop—by typing scala at your operating system command line. Or you may want to create a little one-file “Hello, world” project and then compile and run it. Because these command-line tasks are where many people will start working with Scala, they’re covered here first.
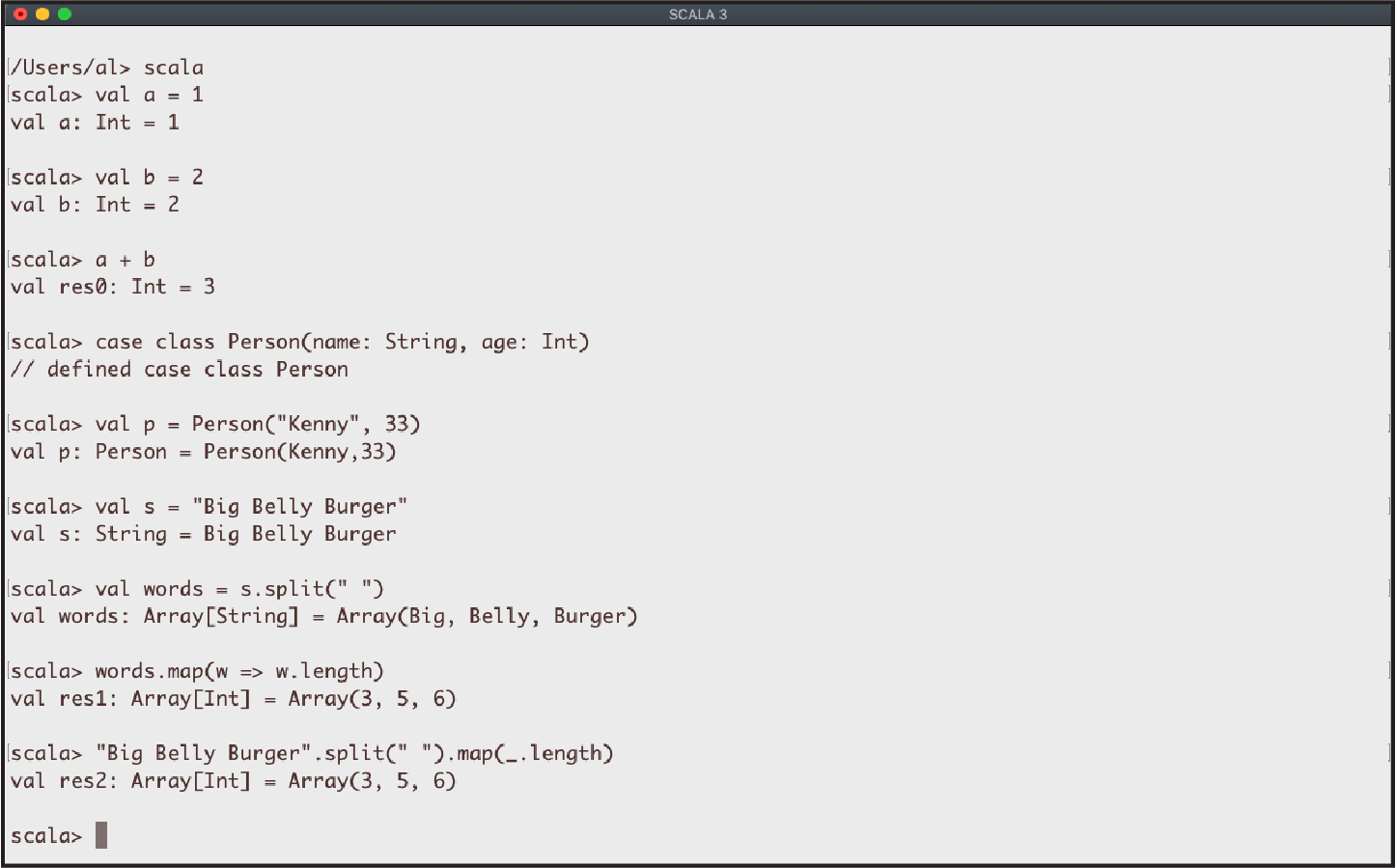
The REPL is a command-line shell. It’s a playground area where you can run small tests to see how Scala and its third-party libraries work. If you’re familiar with Java’s JShell, Ruby’s irb, the Python shell or IPython, or Haskell’s ghci, Scala’s REPL is similar to all of these. As shown in Figure 1-1, just start the REPL by typing scala at your operating system command line, then type in your Scala expressions, and they’ll be evaluated in the shell.
Any time you want to test some Scala code, the REPL is a terrific playground environment. There’s no need to create a full-blown project—just put your test code in the REPL and experiment with it until you know it works. Because the REPL is such an important tool, its most important features are demonstrated in the first two recipes of this chapter.
Read now
Unlock full access






