Submitting jobs to the Spark cluster (local)
There are multiple components involved in running Spark in distributed mode. In the self-contained application mode (the main program that we have run throughout this book so far), all of these components run on a single JVM. The following diagram elaborates the various components and their functions in running the Scala program in distributed mode:
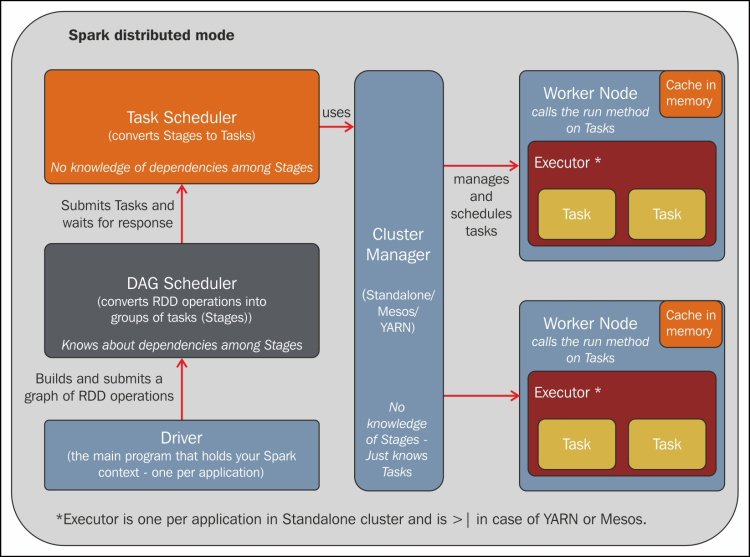
As a first step, the RDD graph that we construct using the various operations on our RDD (map, filter, join, and so on) is passed to the Directed Acyclic Graph (DAG) scheduler. The DAG scheduler optimizes the flow and converts all RDD operations into groups ...
Get Scala: Guide for Data Science Professionals now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

