Chapter 4. Serverless Operations Field Guide
This chapter is meant as a guide to help you decide when and where to use serverless computing. We will talk about application areas and review concrete use cases for it. Then we’ll turn our attention to the limitations of serverless computing, potential gotchas, and a migration guide from a monolithic application. Last but not least, we will have a look at a simple walkthrough example to discuss the implications for operations as outlined in the previous chapter.
Latency Versus Access Frequency
Before you embark on the serverless journey, you might want to ask yourself how applicable the serverless paradigm is for the use case at hand. There may be an array of deciding factors for your use case, which can be summed up in two categories: technical and economic. Technical requirements could be supported programming languages, available triggers, or integration points supported by a certain offering. On the other hand, you or the budget holder are probably also interested in the costs of using the service (at least in the context of a public cloud offering, where these are often more transparent).
Figure 4-1 provides a rough guide for the applicability of serverless computing along two dimensions: latency and access frequency.
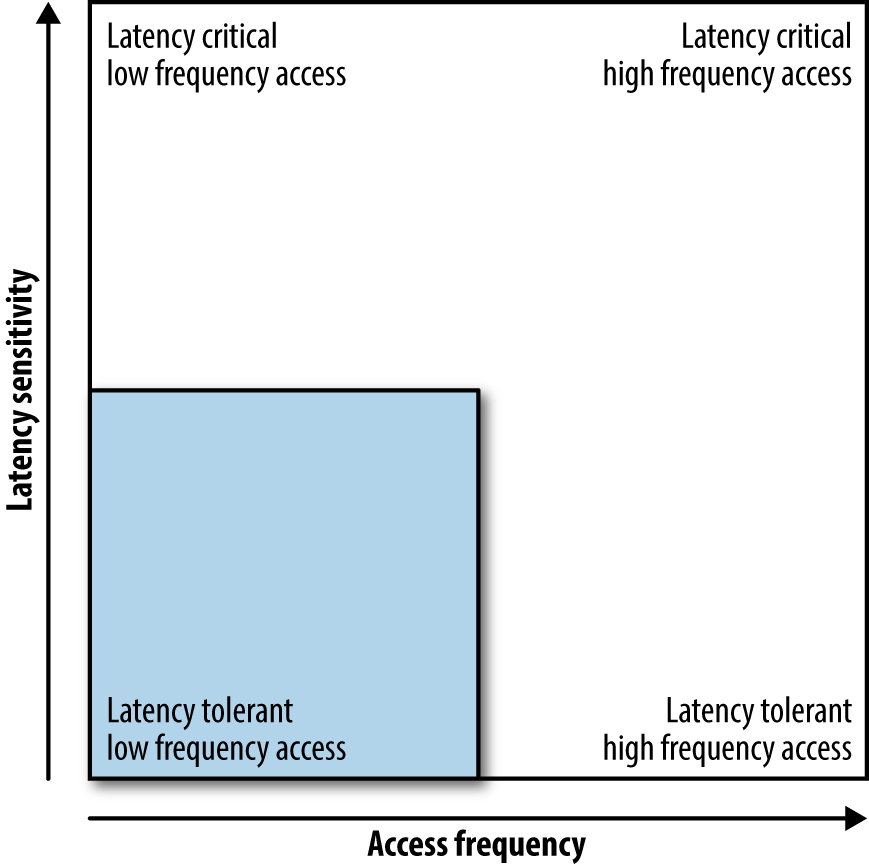
Figure 4-1. Latency sensitivity versus access frequency
By latency, I mean how much time can acceptably elapse between function invocation and termination. It might be important for your use case that you have guarantees around latency—for example, that the 90th percentile cannot exceed 100 ms. It might also be the case that your use case requires an overall low latency. For example, when creating a resized version of a user’s profile image, you might not care if it takes 1 second or 5 seconds; on the other hand, when a user wants to check out a shopping basket, you don’t want to risk any delays as these might lead to abandonment and loss of revenue.
Independent from the latency and determined by the workload is the access frequency. A certain functionality might only be used once per hour, whereas in another case you’re dealing with many concurrent requests, effectively establishing a permanent access pattern. Think of a user checking in at a certain location, triggering an update of a score, versus the case of an online chat environment.
To sum up the guidance that one can derive from the latency-versus-frequency graph, serverless computing is potentially a great fit for workloads that are in the lower-left quadrant of Figure 4-1—that is, use cases that are latency tolerant with a relatively low access frequency. The higher the access frequency and the higher the expectations around latency, the more it usually pays off to have a dedicated machine or container processing the requests. Granted, I don’t provide you with absolute numbers here, and the boundaries will likely be pushed in the future; however, this should provide you with a litmus test to check the general applicability of the paradigm. In addition, if you already have a serverless deployment, the infrastructure team might be able to supply you with data concerning the overall usage and costs. Equipped with this, you’ll be in a better position to decide if serverless computing continues to make sense from an economic point of view.
When (Not) to Go Serverless
There are a number of cases where serverless computing is a great fit, mainly centered around rather short-running, stateless jobs in an event-driven setup. These are usually found in mobile apps or IoT applications, such as a sensor updating its value once per day. The reason the paradigm works in this context is that you’re dealing with relatively simple operations executing for a short period of time. Let’s now have a look at some concrete application areas and use cases.
Application Areas and Use Cases
Typical application areas of serverless computing are:
-
Infrastructure and glue tasks, such as reacting to an event triggered from cloud storage or a database
-
Mobile and IoT apps to process events, such as user check-in or aggregation functions
-
Image processing, for example to create preview versions of an image or extract key frames from a video
-
Data processing, like simple extract, transform, load (ETL) pipelines to preprocess datasets
Let’s now have a closer look at a concrete example of how the paradigm is applied. LambCI is a serverless continuous integration (CI) system. Michael Hart, the creator of LambCI, was motivated to develop LambCI out of frustration with existing CI systems; in his own words:
You’ll be under- or overutilized, waiting for servers to free up or paying for server power you’re not using. And this, for me, is where the advantage of a serverless architecture really comes to light: 100% utilization, coupled with instant invocations.
Introducing LambCI—a serverless build system,, July 2016
The architecture of LambCI is shown in Figure 4-2: it is essentially utilizing the Amazon Simple Notification Service (SNS) to listen to GitHub events and triggering a Lambda function that carries out the actual build, with the resulting build artifacts stored in S3 and build configuration and metadata kept in DynamoDB.
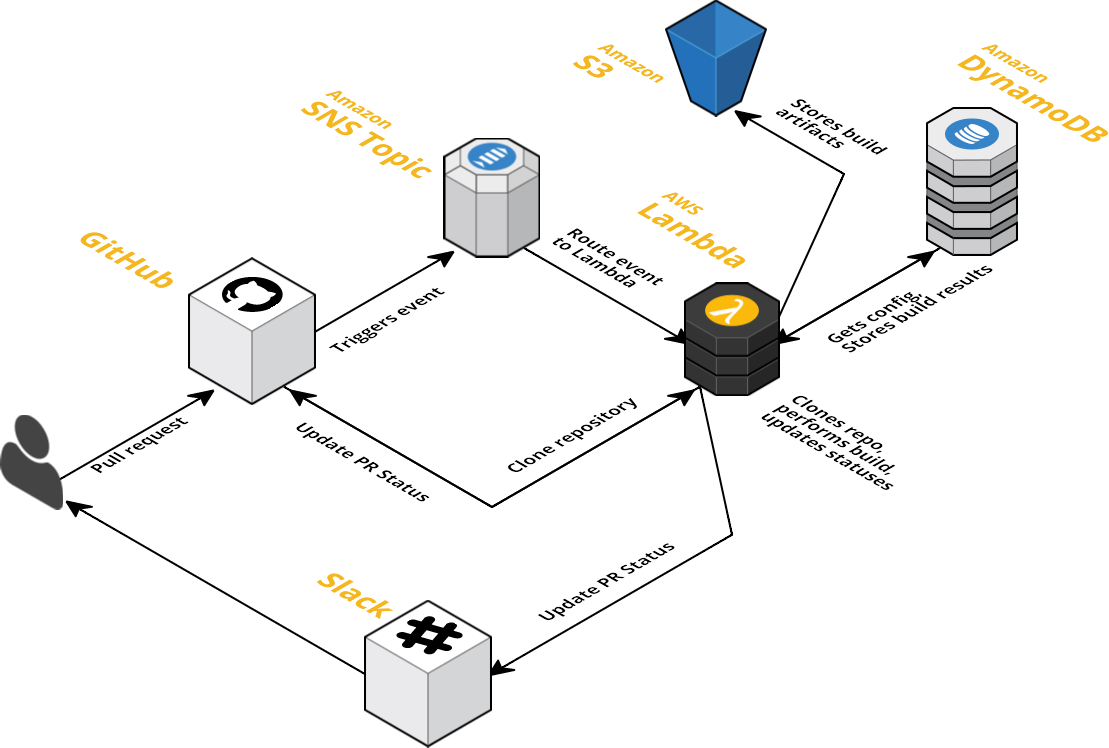
Figure 4-2. LambCI architecture
Limitations of LambCI at the moment are that there is no HTTP interface available (i.e., one has to interface with SNS), no root access can be provided (that is, it’s not suitable for building Docker images), and the build time is capped at five minutes. Nevertheless, since LambCI can be deployed based on a CloudFormation stack, using it can save a lot of money, especially for many shorter-running builds.
Other exemplary use cases for serverless architectures include but are not limited to the following:
-
Forwarding AWS alerts to Slack to support chatops
-
Blocking abusive IP addresses in CloudFlare
-
Migrating an email marketing tool for small business
-
Providing IRC notifications, as in IRC Hooky
-
Powering Slackbots
-
Calculating lineups for a fantasy game, as reported in “30K Page Views for $0.21: A Serverless Story”
-
Carrying out continuous deployments
-
Implementing a ticketing system
-
Realizing an IoT service, as in iRobots
-
Doing video processing
-
Replacing cron jobs
-
Fetching nearby Pokemon Go data
-
Integrating Keen.io with CloudWatch
Serverless computing is growing in popularity, and as we saw in Chapter 2, the number of offerings is increasing. Does this mean that in the future we will eventually migrate everything to serverless? I don’t think so, and next we will have a look at challenges with the serverless paradigm that might help clarify why I don’t think this will be the case.
Challenges
While the serverless paradigm without doubt has its use cases and can help simplify certain workloads, there are naturally limitations and challenges. From most pressing to mildly annoying, these include:
-
Stateful services are best implemented outside of serverless functions. Integration points with other platform services such as databases, message queues, or storage are therefore extremely important.
-
Long-running jobs (in the high minutes to hours range) are usually not a good fit; typically you’ll find timeouts in the (high) seconds range.
-
Logging and monitoring are a challenge: the current offerings provide little support for these operational necessities, and on top of that, the expectations are quite different than in traditional environments due to the short lifecycle.
-
Local development can be challenging: usually developers need to develop and test within the online environment.
-
Language support is limited: most serverless offerings support only a handful of programming languages.
Another criticism of serverless computing is the lock-in aspect, as discussed in “Cloud or on-Premises?”.
In addition to these points, a range of opinions have been voiced on the overall concept and the positioning of the serverless approach (for example, on Hacker News). This can serve as a baseline in terms of expectation management as well as a reminder of how young and fluent the ecosystem is.
Migration Guide
The process of migrating a monolithic application to a serverless architecture is by and large comparable with that of migrating to a microservices architecture, leaving stateful aspects aside. Probably the most important question to ask is: does it make sense? As discussed in “Latency Versus Access Frequency” and “Challenges”, not all parts of a monolith are a good match for the stateless, event-driven, and batch-oriented nature of serverless functions. Furthermore, in comparison to breaking down a monolith into, say, 50 microservices, you might find yourself with hundreds of functions. In this situation, a migration of the whole system can be hard to manage and troubleshoot. A better approach might be to identify the workloads that are a good fit and migrate only this functionality.
Walkthrough Example
In this section, we will be using AWS Lambda for a simple walkthrough example to demonstrate the implications for operations, as outlined in Chapter 3. Note that the goal of the exercise is not to provide you with an in-depth explanation of Lambda but to discuss typical workflows and potential challenges or limitations you might experience. The hope is that, equipped with this knowledge, you’ll be better prepared when you decide to apply the serverless paradigm in your own organization or project.
Preparation
For the walkthrough example, I’ll be using a blueprint: s3-get-object-python. This blueprint, as shown in Figure 4-3, is written in Python and employs an S3 trigger to retrieve metadata for that S3 object when it is updated.
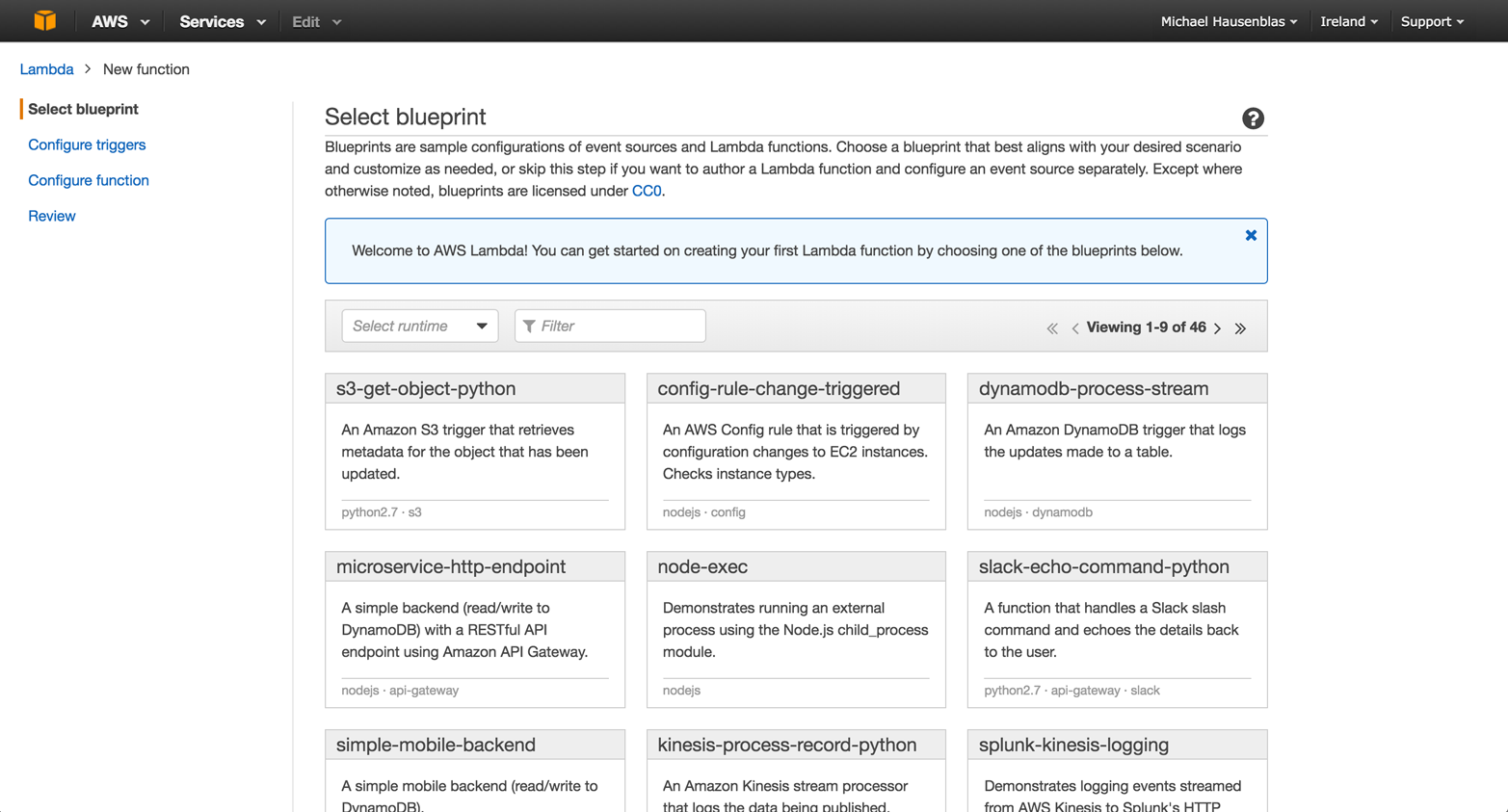
Figure 4-3. AWS Lambda dashboard: selecting a blueprint
Also, as a preparation step, I’ve created an S3 bucket called serops-we that we will be using shortly.
Trigger Configuration
In the first step, depicted in Figure 4-4, I configure and enable the trigger: every time a file is uploaded into the serops-we bucket, the trigger should fire. The necessary permissions for S3 to invoke the Lambda function are automatically added in this step.
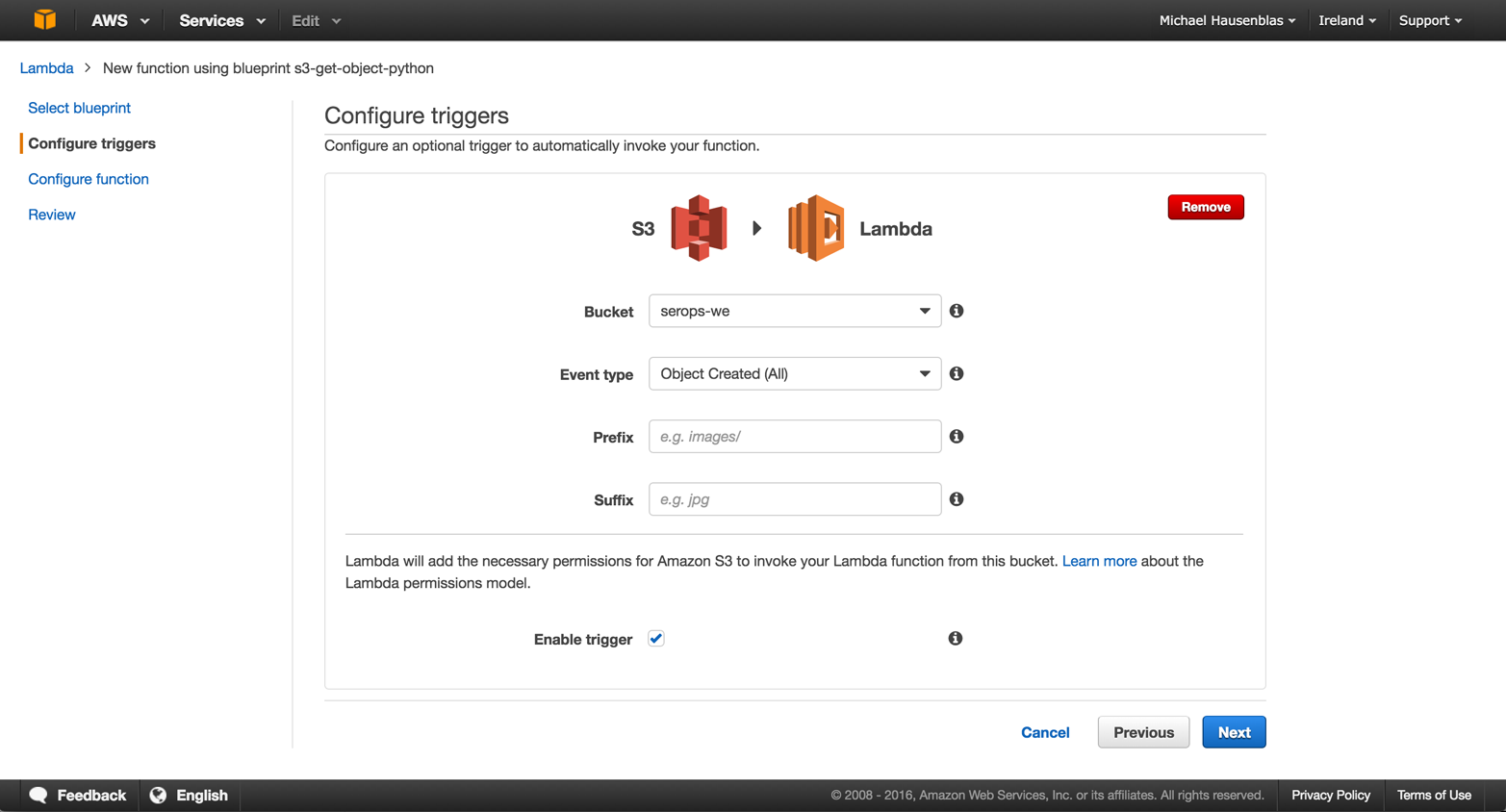
Figure 4-4. Configuring the S3 trigger
Note that in this step I could also have applied certain filters, using the Prefix and Suffix fields, for example, to only react to events from a certain file type.
Function Definition
The next step, configuring the Lambda function, comprises a number of substeps, so let’s take these one by one. First we need to provide a name for the function (I’m using s3-upload-meta here; see Figure 4-5), and we can enter a description as well as selecting a runtime (Python 2.7 in our case).

Figure 4-5. Configuring the Lambda function: setting global properties
Next comes the actual definition of the function code, as shown in Figure 4-6. For the purpose of this example, I opted for the most primitive option, defining the code inline. Other options are to upload a ZIP file from local storage or S3. In a production setup, you’d likely have your CI/CD pipeline putting the code on S3.
In this step, also note the function signature, lambda_handler(event, context): while the name of the handler can be arbitrarily chosen, the parameters are fixed in terms of order and type.
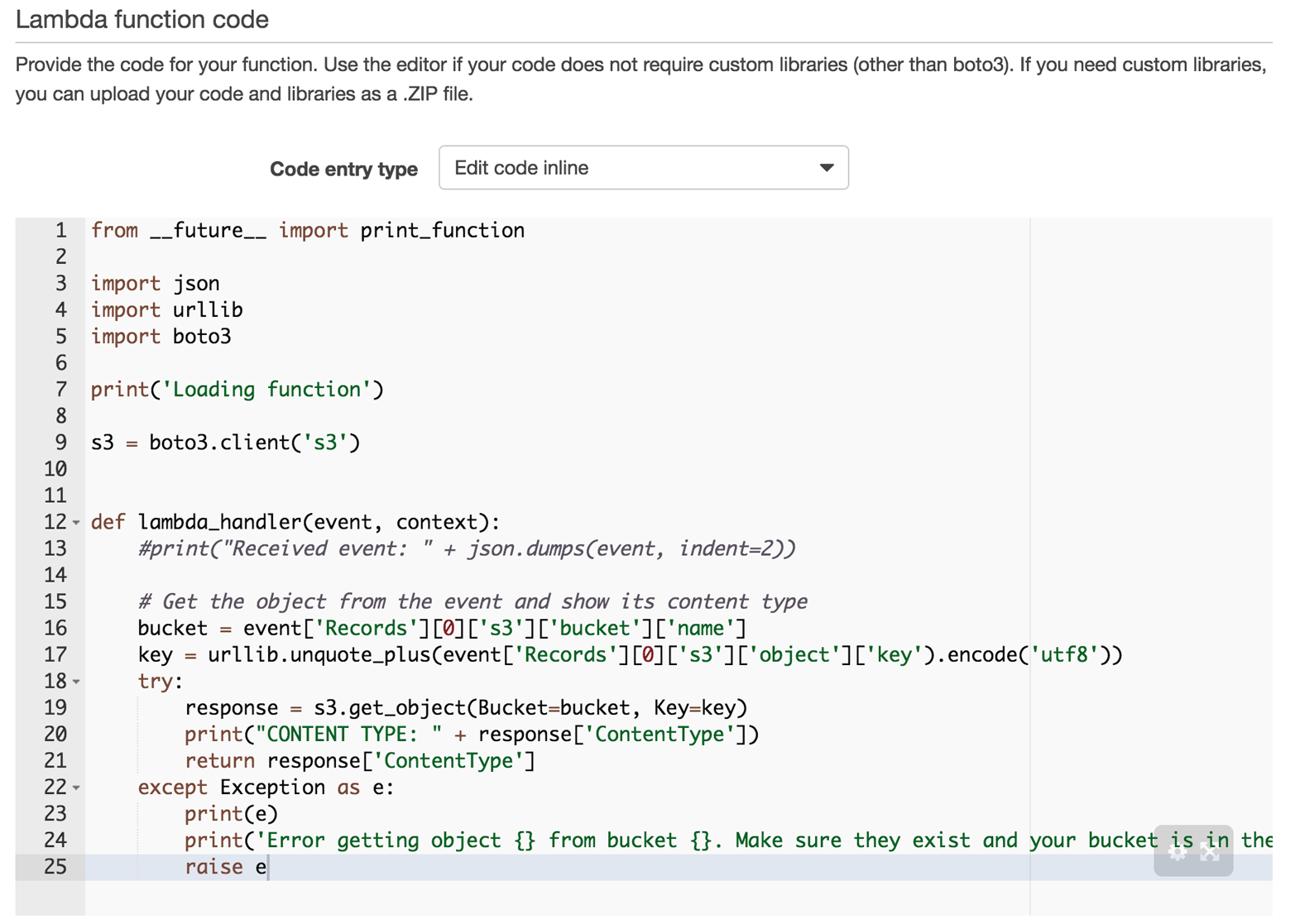
Figure 4-6. Providing the Lambda function code
Now we need to provide some wiring and access information. In this substep, depicted in Figure 4-7, I declare the handler name as chosen in the previous step (lambda_handler) as well as the necessary access permissions. For that, I create a new role called lambda-we using a template that defines a read-only access policy on the S3 bucket serops-we I prepared earlier. This allows the Lambda function to access the specified S3 bucket.
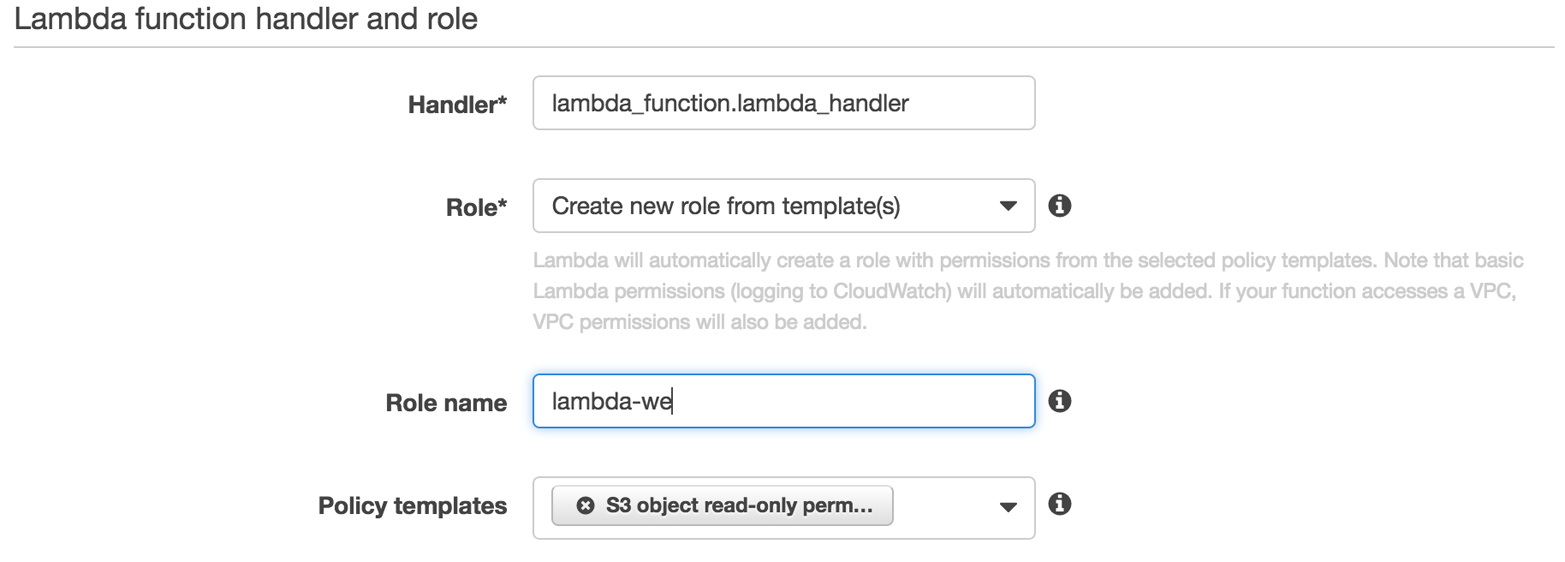
Figure 4-7. Defining the entry point and access control
The last substep to configure the Lambda function is to (optionally) specify the runtime resource consumption behavior (see Figure 4-8).
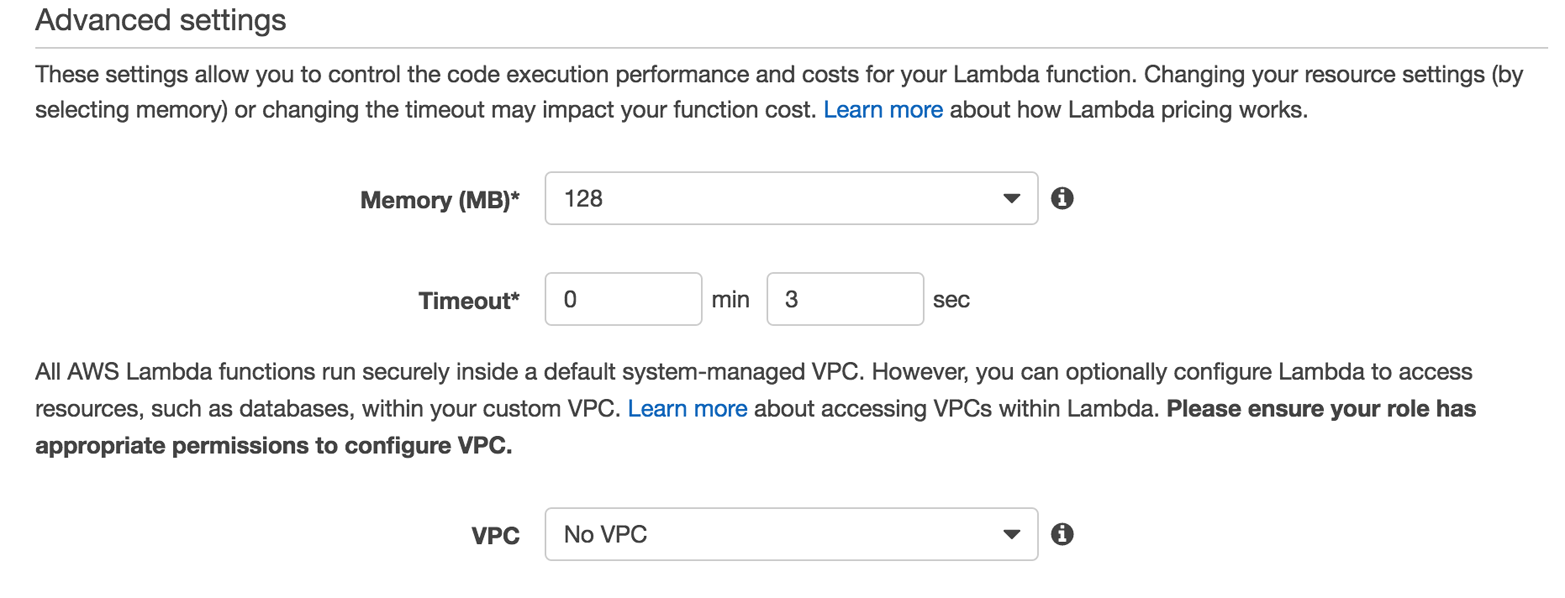
Figure 4-8. Setting the runtime resources
The main parameters here are the amount of available memory you want the function to consume and how long the function is allowed to execute. Both parameters influence the costs, and the (nonconfigurable) CPU share is determined by the amount of RAM you specify.
Review and Deploy
It’s now time to review the setup and deploy the function, as shown in Figure 4-9.
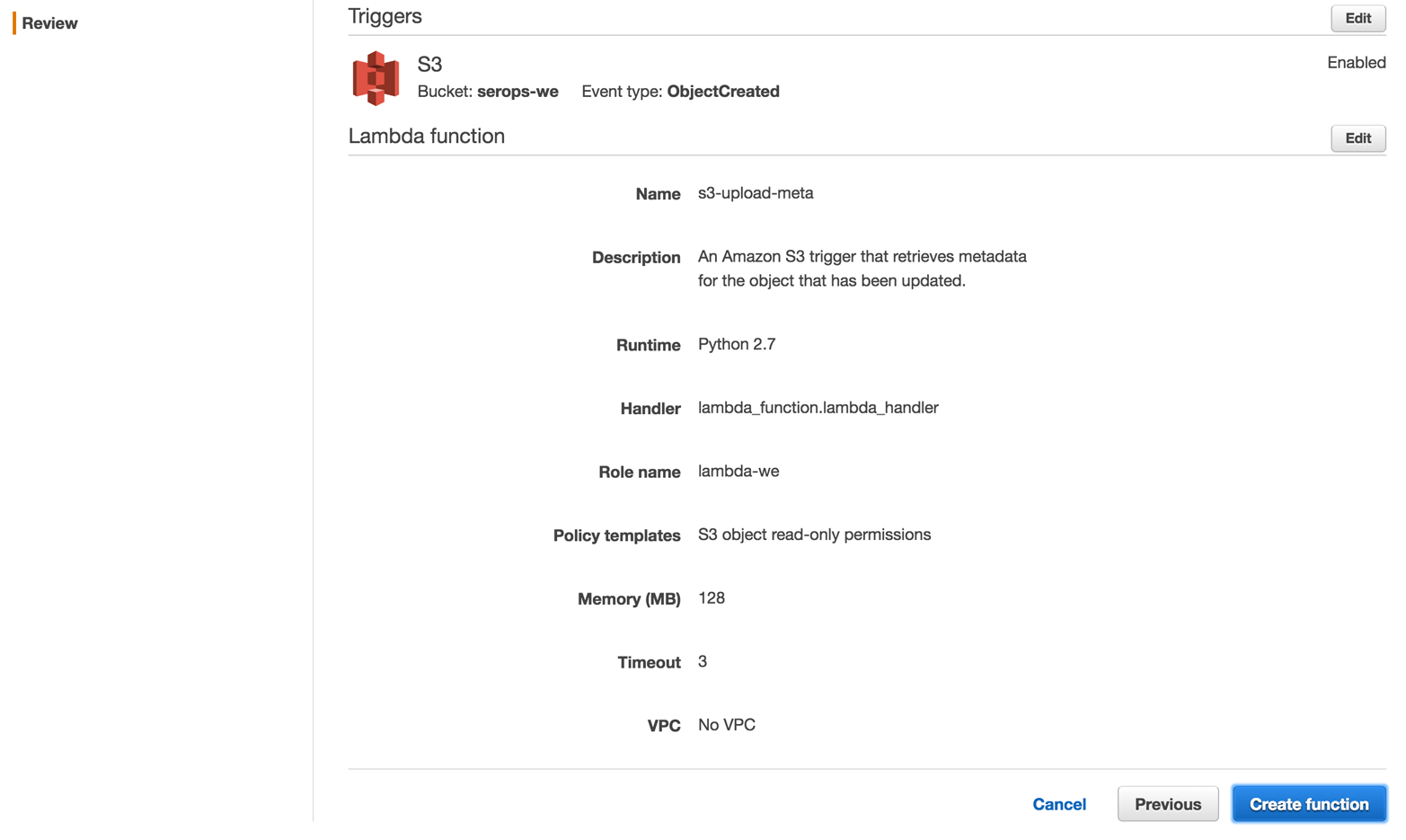
Figure 4-9. Reviewing and deploying the function
The result of the previous steps is a deployed Lambda function like the one in Figure 4-10.
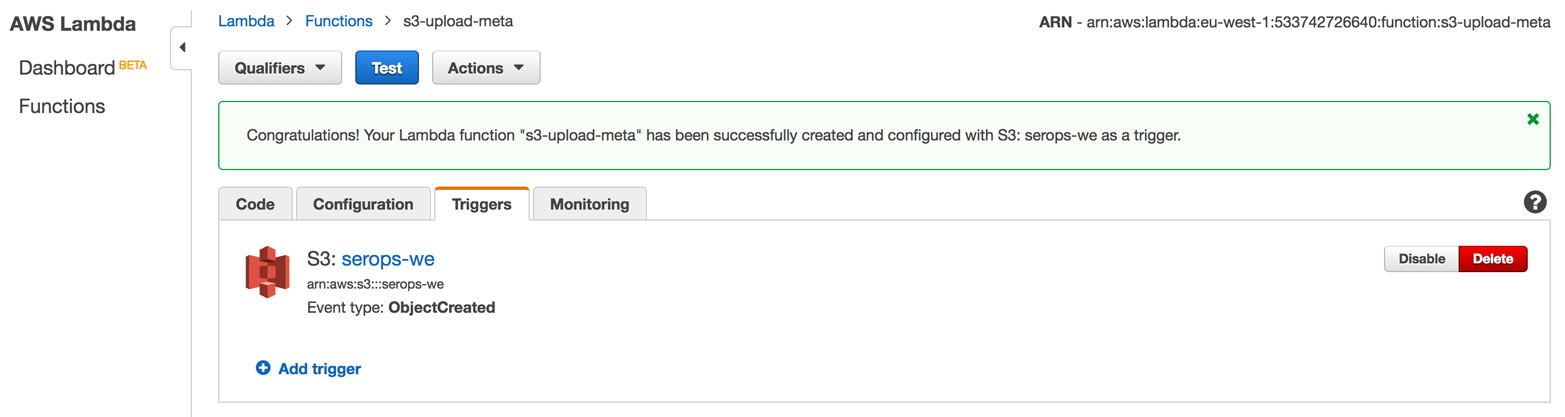
Figure 4-10. The deployed Lambda function
Note the trigger, the S3 bucket serops-we, and the available tabs, such as Monitoring.
Invoke
Now we want to invoke our function, s3-upload-meta: for this we need to switch to the S3 service dashboard and upload a file to the S3 bucket serops-we, as depicted in Figure 4-11.
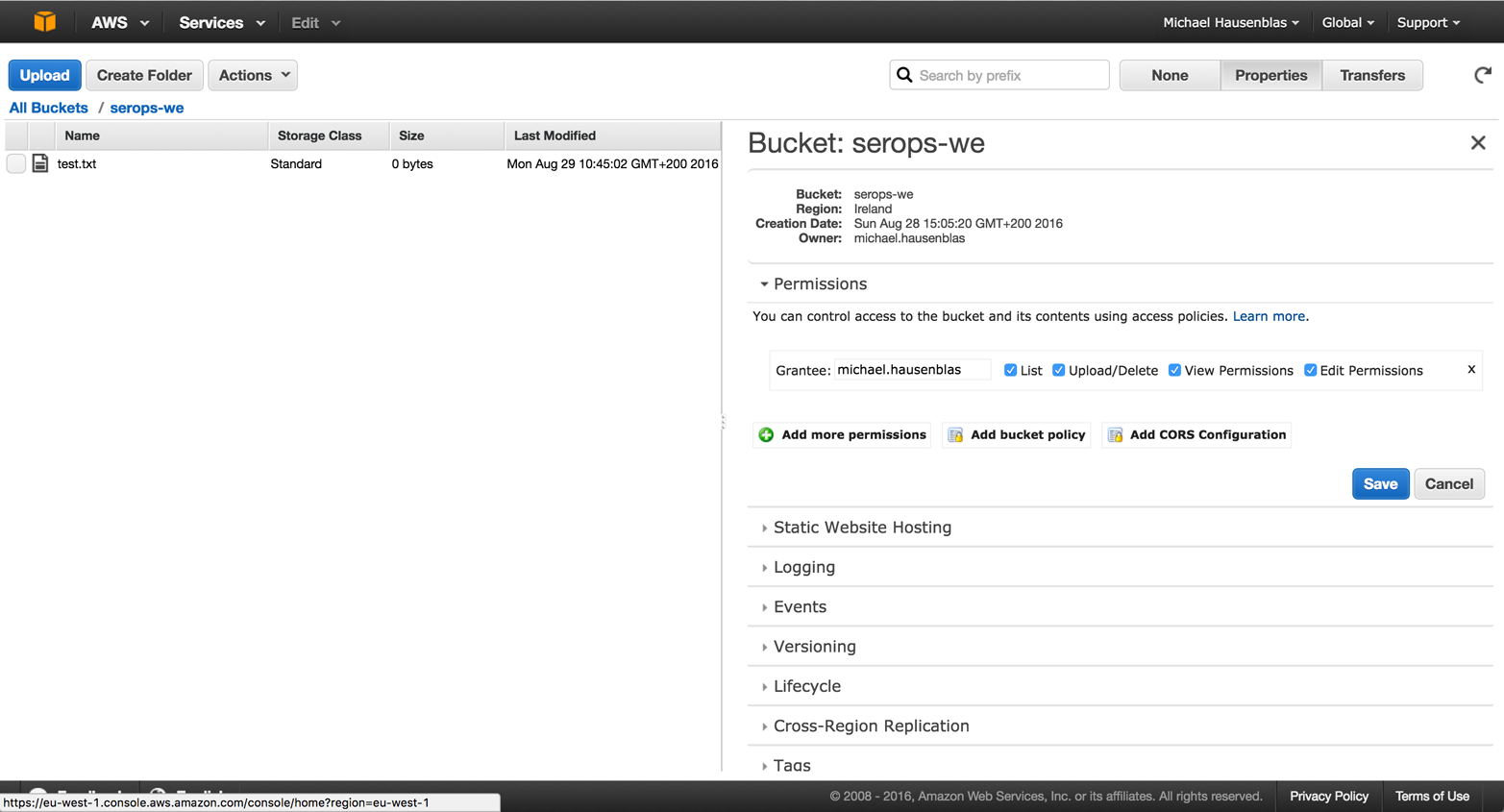
Figure 4-11. Triggering the Lambda function by uploading a file to S3
If we now take a look at the Monitoring tab back in the Lambda dashboard, we can see the function execution there (Figure 4-12). Also available from this tab is the “View logs in CloudWatch” link in the upper-right corner that takes you to the execution logs.
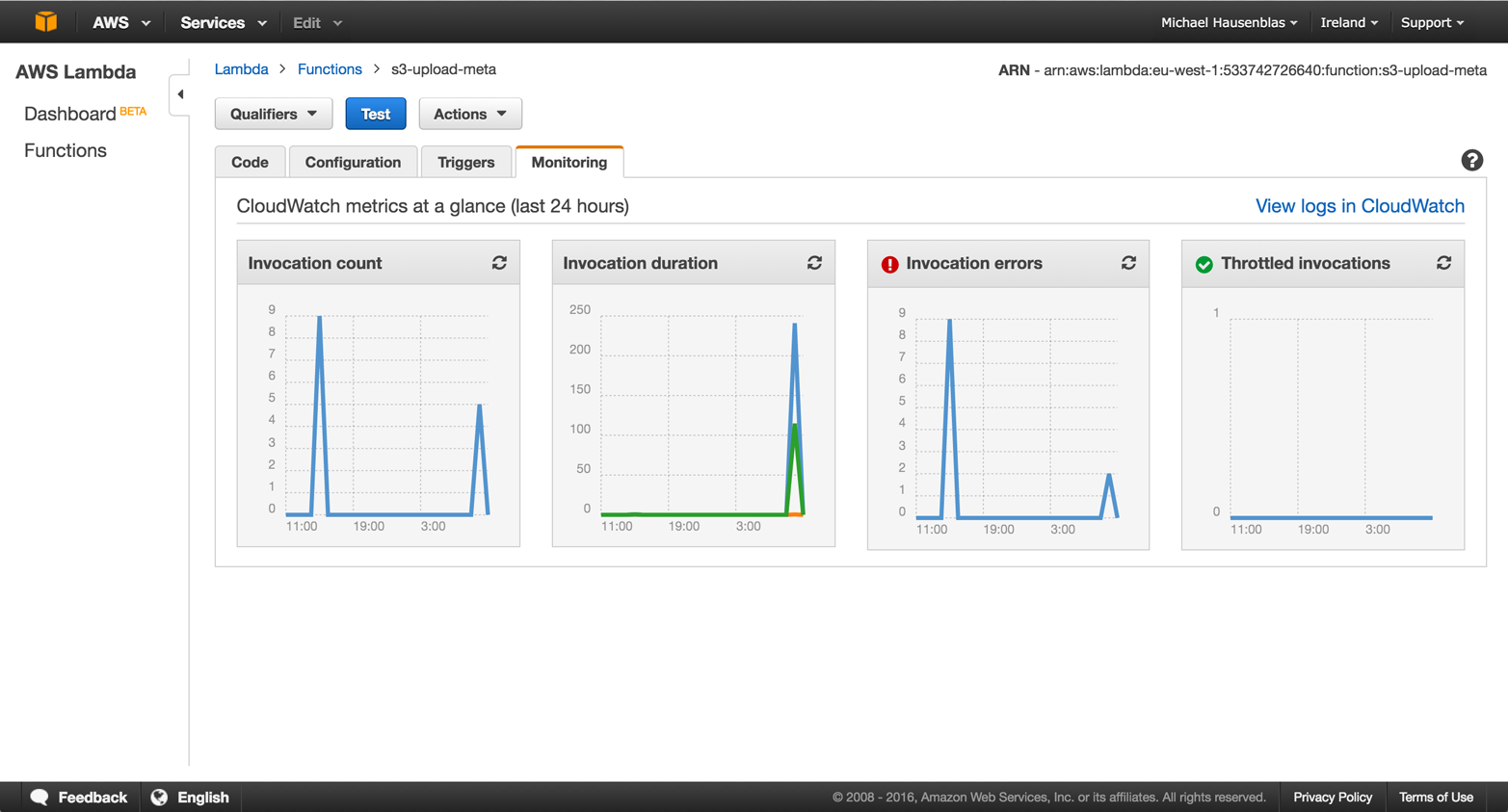
Figure 4-12. Monitoring the function execution
As we can see from the function execution logs in Figure 4-13, the function has executed as expected. Note that the logs are organized in so-called streams, and you can filter and search in them. This is especially relevant for troubleshooting.
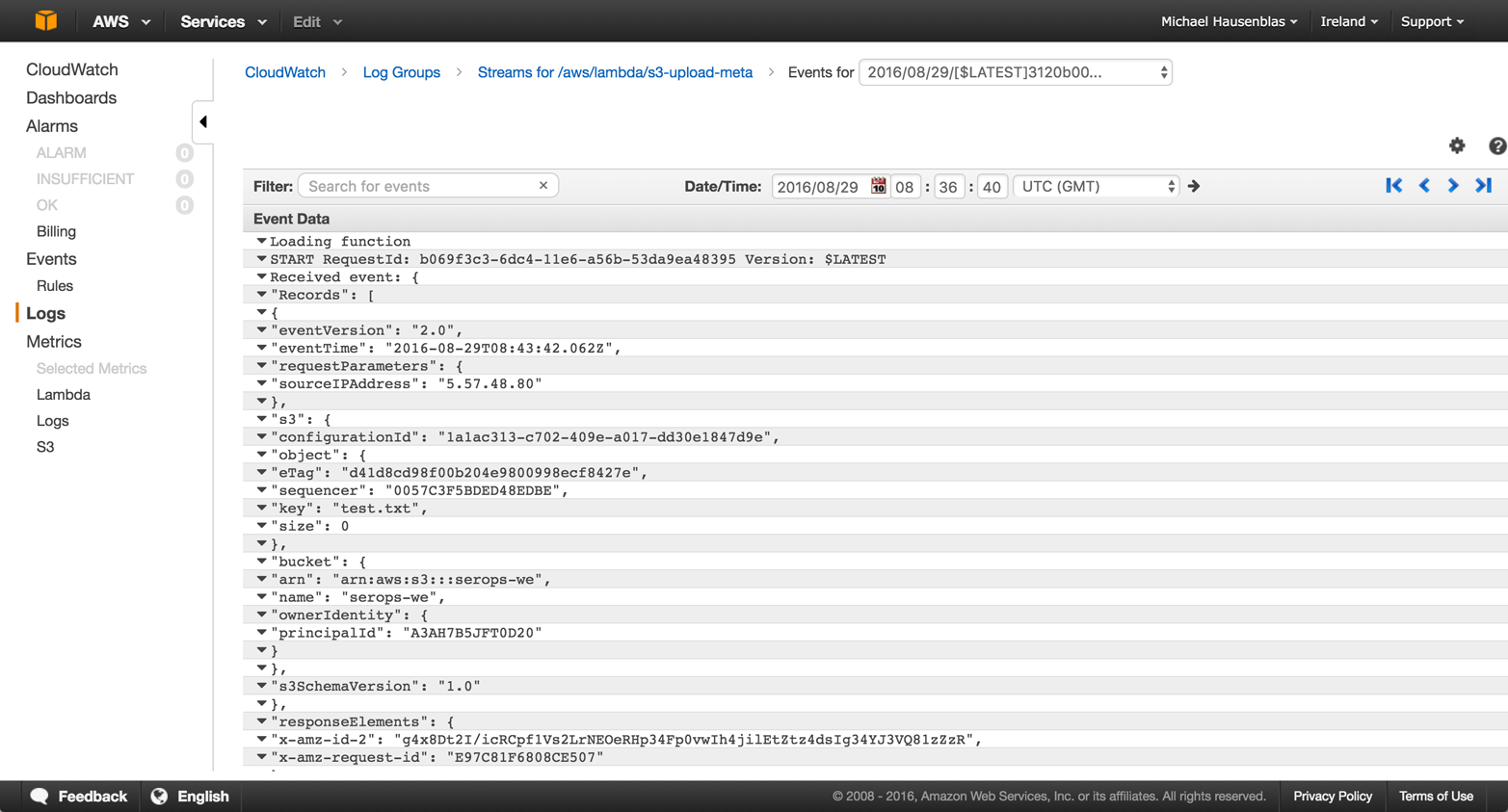
Figure 4-13. Accessing the function execution logs
That’s it. A few steps and you have a function deployed and running. But is it really that easy? When applying the serverless paradigm to real-world setups within existing environments or trying to migrate (parts of) an existing application to a serverless architecture, as discussed in “Migration Guide”, one will likely face a number of questions. Let’s now have a closer look at some of the steps from the walkthrough example from an AppOps and infrastructure team perspective to make this a bit more explicit.
Where Does the Code Come From?
At some point you’ll have to specify the source code for the function. No matter what interface you’re using to provision the code, be it the command-line interface or, as in Figure 4-6, a graphical user interface, the code comes from somewhere. Ideally this is a (distributed) version control system such as Git and the process to upload the function code is automated through a CI/CD pipeline such as Jenkins or using declarative, templated deployment options such as CloudFormation.
In Figure 4-14 you can see an exemplary setup (focus on the green labels 1 to 3) using Jenkins to deploy AWS Lambda functions. With this setup, you can tell who has introduced a certain change and when, and you can roll back to a previous version if you experience troubles with a newer version.
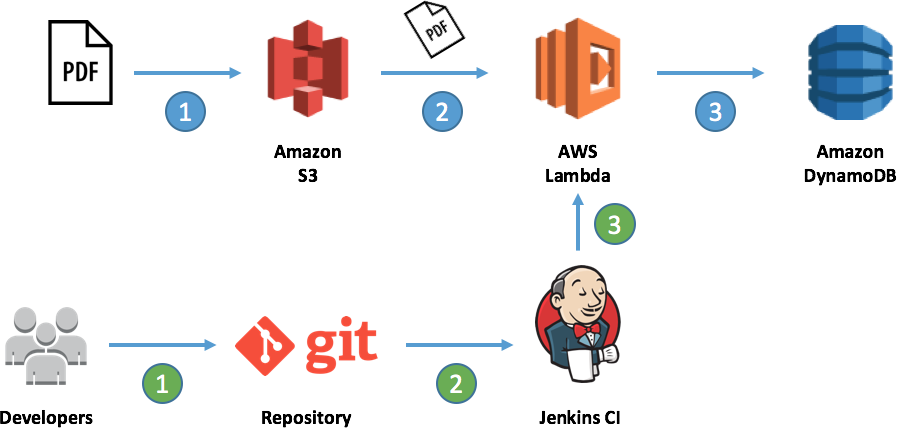
Figure 4-14. Automated deployment of Lambdas using Jenkins (kudos to AWS)
How Is Testing Performed?
If you’re using public cloud, fully managed offerings such as Azure Functions or AWS Lambda, you’ll typically find some for (automated) testing. Here, self-hosted offerings usually have a slight advantage: while in managed offerings certain things can be tested in a straightforward manner (on the unit test level), you typically don’t get to replicate the entire cloud environment, including the triggers and integration points. The consequence is that you typically end up doing some of the testing online.
Who Takes Care of Troubleshooting?
The current offerings provide you with integrations to monitoring and logging, as I showed you in Figure 4-12 and Figure 4-13. The upside is that, since you’re not provisioning machines, you have less to monitor and worry about; however, you’re also more restricted in what you get to monitor.
Multiple scenarios are possible: while still in the development phase, you might need to inspect the logs to figure out why a function didn’t work as expected; once deployed, your focus shifts more to why a function is performing badly (timing out) or has an increased error count. Oftentimes these runtime issues are due to changes in the triggers or integration points. Both of those scenarios are mainly relevant for someone with an AppOps role.
From the infrastructure team’s perspective, studying trends in the metrics might result in recommendations for the AppOps: for example, to split a certain function or to migrate a function out of the serverless implementation if the access patterns have changed drastically (see also the discussion in “Latency Versus Access Frequency”).
How Do You Handle Multiple Functions?
Using and managing a single function as a single person is fairly easy. Now consider the case where a monolith has been split up into hundreds of functions, if not more. You can imagine the challenges that come with this: you need to figure out a way to keep track of all the functions, potentially using tooling like Netflix Vizceral (originally called Flux).
Conclusion
This chapter covered application areas and use cases for serverless computing to provide guidance about when it’s appropriate (and when it’s not), highlighting implications for operations as well as potential challenges in the implementation phase through a walkthrough example.
With this chapter, we also conclude this report. The serverless paradigm is a powerful and exciting one, still in its early days but already establishing itself both in terms of support by major cloud players such as AWS, Microsoft, and Google and in the community.
At this juncture, you’re equipped with an understanding of the basic inner workings, the requirements, and expectations concerning the team (roles), as well as what offerings are available. I’d suggest that as a next step you check out the collection of resources—from learning material to in-use examples to community activities—in Appendix B. When you and your team feel ready to embark on the serverless journey, you might want to start with a small use case, such as moving an existing batch workload to your serverless platform of choice, to get some experience with it. If you’re interested in rolling your own solution, Appendix A gives an example of how this can be done. Just remember: while serverless computing brings a lot of advantages for certain workloads, it is just one tool in your toolbox—and as usual, one size does not fit all.
Get Serverless Ops now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

