CHAPTER FOUR
Predicting Trends
We assume that you have made a few passes through Chapter 3 and have just deployed a monitoring, trending, graphing, and measurement system. Now you can use this data (excluding the barking statistics) like a crystal ball and predict the future like Nostradamus. But, let’s stop here for a moment to remember an irritating little detail: it’s impossible to accurately predict the future.

Forecasting capacity needs is part context and part math. It’s also the art of slicing and dicing of historical data and making educated guesses about the future. Outside of those rare bursts and spikes of load on the system, the long-term view is hopefully one of steadily increasing usage. By putting all of this historical data into perspective, you can generate estimates for what your organization would need to sustain the growth of a website. As we’ll see later, the key to making robust forecasts is to have an adjustable process. In the cloud context, the forecasts guide the design of the autoscaling policies (the topic of autoscaling is discussed in detail in Chapter 6).
Riding the Waves
A good capacity plan depends on knowing your enterprise’s needs for the most important resources and how those needs change over time. After the historical data on capacity has been gathered, you can begin analyzing it with an eye toward recognizing any trends and recurring patterns. Recall the example from Chapter 3 when we were both working at Flickr, and we discovered that Sunday had been historically the highest photo upload day of the week. This is interesting for many reasons. It also can lead one to other questions: has that Sunday peak changed over time and, if so, how has it changed with respect to the other days of the week? Has the highest upload day always been Sunday? Does that change with addition of new members residing on the other side of the International Date Line? Is Sunday still the highest upload day on holiday weekends? These questions can all be answered when the data is available and the answers in turn can provide a wealth of insight with respect to planning new feature launches, operational outages, or maintenance windows.
Recognizing trends is valuable for many reasons, not just for capacity planning. When we looked at disk space consumption in Chapter 3, we stumbled upon some weekly upload patterns. Being aware of any recurring patterns can be invaluable when making decisions later on. Trends also can inform community management, customer care and support, and product management and finance. Following are some examples of how metrics measurement can be useful:
-
An operations group can avoid scheduling maintenance on a Sunday because it could affect machines that are tasked with image processing. Instead, opting to perform maintenance on Friday can potentially minimize any adverse effects on users.
-
If new code that touches the upload processing infrastructure is deployed, you might want to pay particular attention the following Sunday to see whether everything is holding up well when the system experiences its highest load.
-
Making customer support aware of these peak patterns allows them to gauge the effect of any user feedback regarding uploads.
-
Product management might want to launch new features based on the low or high traffic periods of the day. A good practice is to ensure that everyone on the team knows where these metrics are located and what they mean.
-
The finance department also might want to know about these trends because it can help it plan for capital expenditure (capex) costs.
Trends, Curves, and Time
Let’s take a look back at the daily storage consumption data from Chapter 3 and forecast the future storage needs. We already know the defining metric: total available disk space. Graphing the cumulative total of this data provides the right perspective from which to predict future needs. Taking a look at Figure 4-2, we can see where consumption is headed, how it’s changing over time, and when storage is likely to be exhausted.
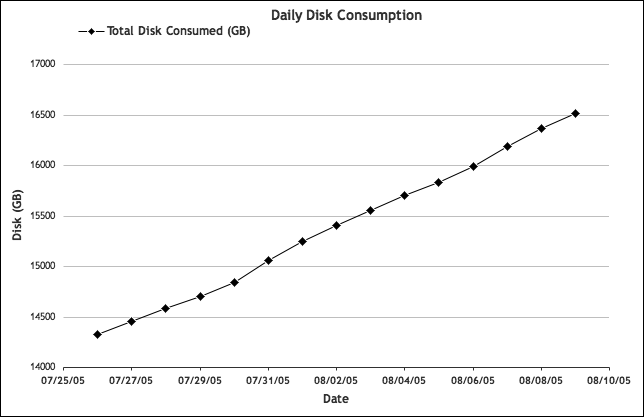
Figure 4-2. Total disk consumption: cumulative view
Now, let’s add another constraint: the total currently available disk space. Let’s assume for this example that there’s a total of 20 TB (or 20,480 GB) installed capacity. From the graph, we note that about 16 TB of storage has been consumed. Adding a solid line extending into the future to represent the total installed space, we obtain the graph shown in Figure 4-3. This illustration demonstrates a fundamental principle of capacity planning: predictions require two essential bits of information—the ceilings and the historical data.
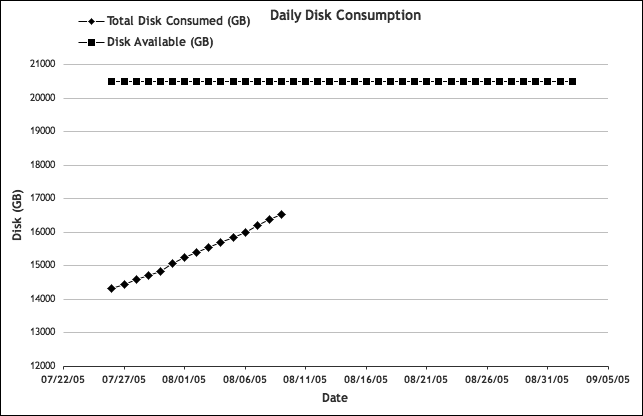
Figure 4-3. Cumulative disk consumption and available space
Determining when the space limitation would be reached is the next step. As just suggested, we could simply draw a straight line that extends from our measured data to the point at which it intersects the current limit line. But is the growth actually linear? It might not be.
Excel calls this next step “adding a trend line,” but some readers might know this process as curve fitting. This is the process by which you attempt to find a mathematical equation that mimics the data at hand. You then can use that equation to make educated guesses about missing values within the data. In this case, because the data is on a timeline, the missing values of interest are in the future. Finding a good equation to fit the data can be just as much art as science. Fortunately, Excel is one of many programs that offers curve fitting.
To display the trend using a more mathematical appearance, let’s change the Chart Type in Excel from Line to XY (Scatter). XY (Scatter) changes the date values to just single data points. We then can use the trending feature of Excel to show us how this trend looks at some point in the future. Right-click the data on the graph to open a drop-down menu. On that menu, select Add Trendline. A dialog box opens, as shown in Figure 4-4.
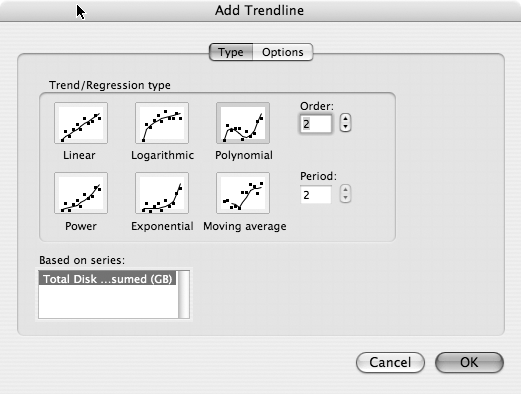
Figure 4-4. Add Trendline Type dialog box
Next, select a trend line type. For the time being, let’s choose Polynomial, and set Order to 2. There might be good reasons to choose another trend type, depending on how variable the data is, how much data you have, and how far into the future you want to forecast. (For more information, see the upcoming sidebar, “FITTING CURVES”)
In this example, the data appears about as linear. However, based on domain knowledge, we already know that this data isn’t linear over a longer period of time (it’s accelerating). Therefore, let’s pick a trend type that can capture the acceleration.
After selecting a trend type, click the Options tab, which opens the Add Trendline Options dialog box, as shown in Figure 4-5. To show the equation that will be used to mimic disk usage, select the checkbox for “Display equation on chart.” You also can look at the R2 value for this equation by selecting the “Display R-squared value on chart” checkbox. The R2 value is known in the world of statistics as the coefficient of determination. Without going into the details of how this is calculated, it’s basically an indicator of how well an equation matches a certain set of data. An R2 value of 1 indicates a mathematically perfect fit. With the data we’re using for this example, any value above 0.85 should be sufficient. The important thing to know is that as the R2 value decreases, so too should the confidence in the forecasts. Changing the trend type in the previous step affects the R2 values—sometimes for better, sometimes for worse—so some experimentation is needed here when looking at different sets of data.
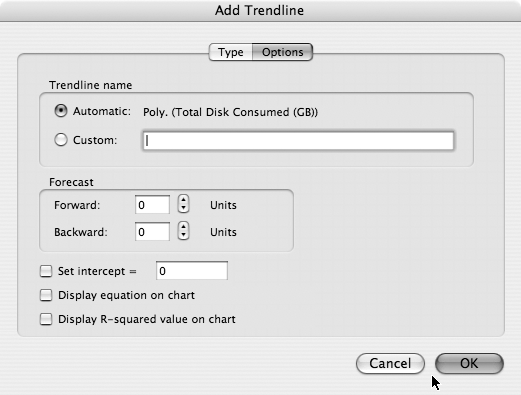
Figure 4-5. The Add Trendline Options dialog box
You would want to extend the trend line into the future, of course. The trend line should be extended far enough into the future such that it intersects the line corresponding to our total available space. This is the point at which you can predict that the space will run out. In the Forecast portion of the dialog box, type 25 units for a value. Our units in this case are days. After clicking OK, the forecast should look similar to Figure 4-6.
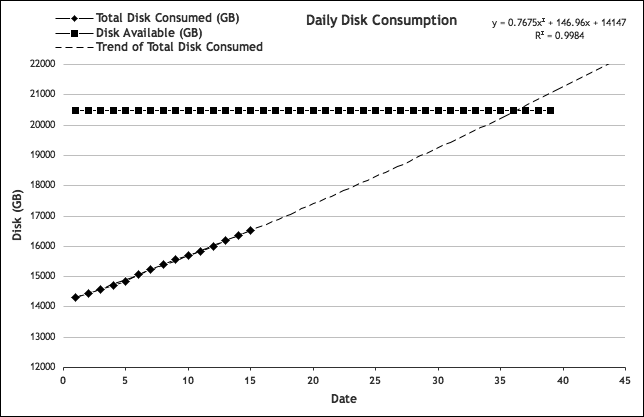
Figure 4-6. Extending the trend line
The graph indicates that somewhere around day 37, the disk space will run out. Luckily, you don’t need to squint at the graph to see the actual values; you have the equation used to plot that trend line. As detailed in Table 4-1, plugging the equation into Excel, and using the day units for the values of X, the last day when the disk usage is below the disk space limit is 8/30.
| Date | Disk available (GB) | Y = 0.7675 x 2 + 146.96x + 14147 | |
|---|---|---|---|
| 33 | 08/27 | 20480.00 | 19832.49 |
| 34 | 08/28 | 20480.00 | 20030.87 |
| 35 | 08/29 | 20480.00 | 20230.79 |
| 36 | 08/30 | 20480.00 | 20432.24 |
| 37 | 08/31 | 20480.00 | 20635.23 |
| 38 | 09/01 | 20480.00 | 20839.75 |
| 39 | 09/02 | 20480.00 | 21045.81 |
Now that it is known when more disk space will be needed, you can get on with ordering and deploying it.
This example of increasing disk space is about as simple as they come. But because the metric is consumption-driven, every day has a new value that contributes to the definition of our curve. You also need to factor in the peak-driven metrics that drive the capacity needs in other parts of a site. Peak-driven metrics involve resources that are continually regenerated, such as CPU time and network bandwidth. They fluctuate more dramatically and thus are more difficult to predict, so curve fitting requires more care.
Tying Application Level Metrics to System Statistics: Database Example
In Chapter 3, we went through an exercise of how to establish database ceiling values. To recap, 40 percent disk I/O wait was a critical value to avoid because at this threshold the database replication began experiencing disruptive lags. How do you know when this threshold will be reached? You need some indication that the ceiling is near. It appears the graphs don’t show a clear and smooth line just bumping over the 40 percent threshold. Instead, the disk I/O wait graph shows that the database is healthy until a 40 percent spike occurs. You might deem occasional (and recoverable) spikes to be acceptable, but you need to track how the average values change over time so that the spikes aren’t so close to the ceiling. Also, I/O wait times should be tied to database usage, and ultimately, what that means in terms of actual application usage.
To establish some control over this unruly data, let’s take a step back from the system statistics and look at the purpose this database is actually serving. In this example, we’re looking at a user database wherein the data and the metadata of the users is stored: their photos, their tags, the groups they belong to, and more. The two main drivers of load on this database are the number of photos and the number of users. Having said that, neither the number of users nor the number of photos is singularly responsible for how much work the database does. Taking only one of those variables into account means ignoring the effect of the other. Indeed, there might be many users who have few, or no photos; queries for their data would be quite fast and not at all taxing. On the flip side, there might be a handful of users who maintain enormous collections of photos. You can look at the metrics for clues for the critical values.
For the running example, let’s find out the single most important metric that can define the ceiling for each database server. To this end, we should analyze the disk I/O wait metric for each database server and determine whether there exists a high correlation between I/O wait and the number of users in the database. Referring back to our days at Flicker, it’s interesting to note that there were some servers with more than 450,000 users, but they had healthy levels of I/O wait. On the other hand, other servers with only 300,000 users experienced much higher levels of I/O wait. Looking at the number of photos wasn’t helpful either—disk I/O wait didn’t appear to be tied to photo population. As it turned out, the metric that directly indicated disk I/O wait was the ratio of photos-to-users on each of the databases.
Again, back at Flickr, as part of an application-level dashboard, the metrics—how many users are stored on each database along with the number of photos associated with each user—were measured on a daily basis (collected each night). The photos-per-user ratio is simply the total number of photos divided by the number of users. Although this could be thought of as an average photos-per-user, the range can be quite large, with some “power users” having many thousands of photos, whereas a majority have only tens or hundreds. By looking at how the peak disk I/O wait changes with respect to this photos-per-user ratio, we can get an idea of what sort of application-level metrics we can use to predict and control capacity utilization (see Figure 4-7).
The graph shown in Figure 4-7 was compiled from a number of databases at Flickr and displays the peak disk I/O wait values against the corresponding current photos-to-user ratios. With this graph, we can ascertain where disk I/O wait begins to jump up. There’s an elbow in the data around the 85–90 ratio when the amount of disk I/O wait jumps above the 30 percent range. Because the ceiling value is 40 percent, you would want to keep the photos-per-user ratio in the 80–100 range. We can control this ratio within the application by distributing photos for high-volume users across many databases.
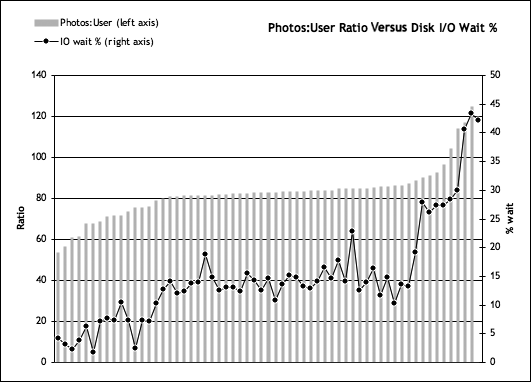
Figure 4-7. Database—photo:user ratio versus disk I/O wait percent
At Flickr, after reaching the limits of the more traditional Master/Slaves MySQL replication architecture (in which all writes go to the master and all reads go to the slaves), the database layout was redesigned to be federated, or sharded. This evolution in architecture exemplifies how architecture decisions can have a positive effect on capacity planning and deployment. By federating the data across many servers, the growth at Flickr was limited only by the amount of hardware that we could deploy, not by the limits imposed by any single machine.
Because we were federated, we could control how users (and their photos) are spread across many databases. This essentially meant that each server (or pair of servers, for redundancy) contained a unique set of data. This is in contrast to the more traditional monolithic database that contains every record on a single server.
NOTE
You can find more information about federated database architectures in Cal Henderson’s book Building Scalable Web Sites (O’Reilly).
OK, enough diversions—let’s get back to the database capacity example and summarize. Database replication lag is bad and should be avoided. Replication lag occurred at 40 percent disk I/O wait, which in turn was reached when the photos-per-user ratio reached 110. Based on the knowledge of how our photo uploads and user registrations grow (see Figure 4-8), we can make informed decisions regarding how much database hardware to buy, and when.
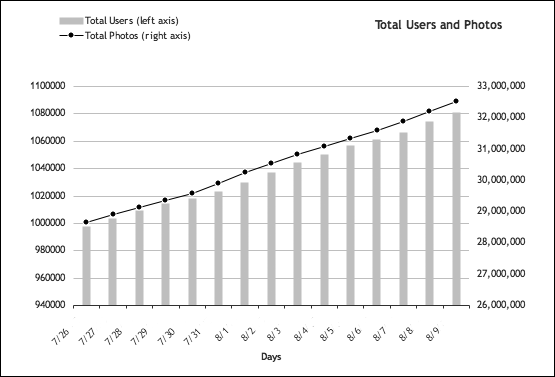
Figure 4-8. Photos uploaded and user registrations
We can extrapolate a trend based on this data to predict how many users and photos there will be for the foreseeable future, and then use that to gauge how the photos-per-user ratio will look on our databases, and whether there is a need to adjust the maximum amounts of users and photos to ensure an even balance across those databases.
Forecasting Peak-Driven Resource Usage: Web Server Example
When we forecast the capacity of a peak-driven resource, we need to track how the peaks change over time. From there, we can extrapolate from that data to predict future needs. Our web server example is a good opportunity to illustrate this process. In Chapter 3, we identified our web server ceilings as 85 percent CPU usage for this particular hardware platform. We also confirmed CPU usage is directly correlated to the amount of work Apache is doing to serve web pages. Also, as a result of our work in Chapter 3, we should be familiar with what a typical week looks like across Flickr’s entire web server cluster. Figure 4-9 illustrates the peaks and valleys over the course of one week.
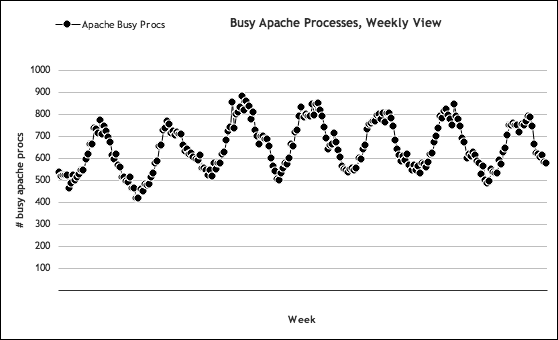
Figure 4-9. Busy Apache processes: weekly view
This data is extracted from a time in Flickr’s history when it had 15 web servers. Let’s suppose that this data is taken today, and we have no idea how our activity will look in the future. We can assume the observations we made in Chapter 3 are accurate with respect to how CPU usage and the number of busy apache processes relate—which turns out to be a simple multiplier: 1.1. If for some reason this assumption does change, we’ll know quickly because we’re tracking these metrics on a per-minute basis. According to the graph in Figure 4-9, we’re seeing about 900 busy concurrent Apache processes during peak periods, load-balanced across 15 web servers. That works out to about 60 processes per web server. Thus, each web server is using approximately 66 percent total CPU (we can look at our CPU graphs to confirm this assumption).
The peaks for this sample data are what we’re interested in the most. Figure 4-10 presents this data over a longer time frame, in which we see these patterns repeat.
It’s these weekly peaks that we want to track and use to predict our future needs. As it turns out, for Flickr, those weekly peaks almost always fall on a Monday. If we isolate those peak values and pull a trend line into the future as we did with our previous disk storage example, we’ll see something similar to Figure 4-11.
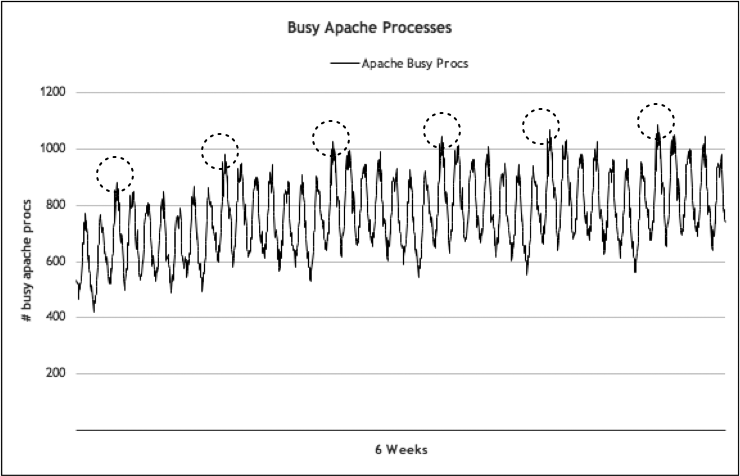
Figure 4-10. Weekly web server peaks across six weeks
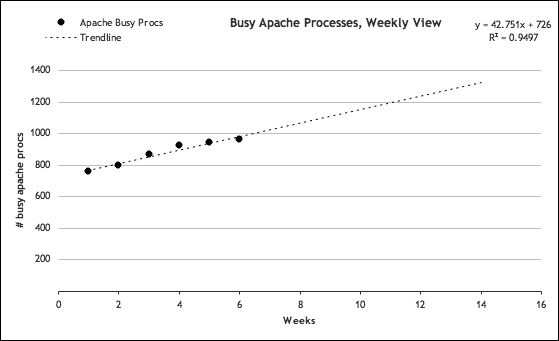
Figure 4-11. Web server peak trend
If our traffic continues to increase at the current pace, this graph predicts that in another eight weeks we can expect to experience roughly 1,300 busy Apache processes running at peak. With our 1.1 processes-to-CPU ratio, this translates to around 1,430 percent total CPU usage across our cluster. If we have defined 85 percent on each server as our upper limit, we would need 16.8 servers to handle the load. Of course, manufacturers are reluctant to sell servers in increments of tenths, so we’ll round that up to 17 servers. We currently have 15 servers, so we’ll need to add two more.
The next question is, when should we add them? As we explained in the earlier sidebar, we can waste a considerable amount of money if we add hardware too soon. Fortunately, we already have enough data to calculate when we’ll run out of web server capacity. We have 15 servers, each currently operating at 66 percent CPU usage at peak. Our upper limit on web servers is set at 85 percent, which would mean 1,275 percent CPU usage across the cluster. Applying our 1.1 multiplier factor, this in turn would mean 1,160 busy Apache processes at peak. If we trust the trend line shown in Figure 4-12, we can expect to run out of capacity sometime between the 9th and 10th week.
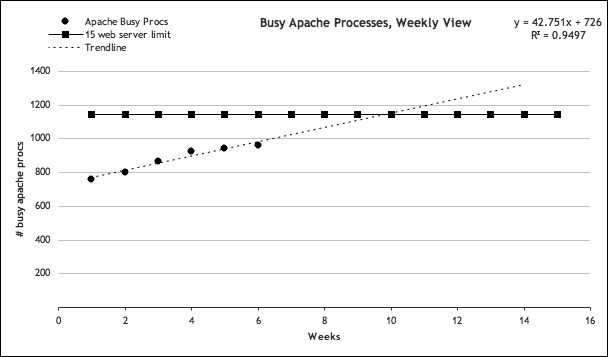
Figure 4-12. Capacity of 15 web servers
Therefore, the summary of our forecast can be presented succinctly:
-
We’ll run out of web server capacity three to four weeks from now.
-
We’ll need two more web servers to handle the load we expect to see in eight weeks.
Now we can begin our procurement process with detailed justifications based on hardware usage trends, not simply a wild guess. We’ll want to ensure that the new servers are in place before we need them, so we’ll need to find out how long it will take to purchase, deliver, and install them.
This is a simplified example. Adding two web servers in three to four weeks shouldn’t be too difficult or stressful. Ideally, we should have more than six data points for robust forecasting, and you would likely not be so close to a cluster’s ceiling as in our example. But no matter how much capacity you would need to add or how long the time frame actually is, the process should be the same.
Caveats Concerning Small Datasets
When you are forecasting with peak values as we’ve done, it’s important to remember that the more data you have to fit a curve, the more accurate the forecast will be. In our example, we based our hardware justifications on six weeks’ worth of data. Is that enough data to constitute a trend? Possibly, but the time period on which you are basing the forecasts is of great importance, as well. Maybe there is a seasonal lull or peak in traffic, and you are on the cusp of one. Maybe you are about to launch a new feature that will add extra load to the web servers within the time frame of this forecast. These are only a few considerations for which you might need to compensate when making justifications to buy new hardware. A lot of variables can come into play when predicting the future, and, as a result, we need to remember to treat our forecasts as what they really are: educated guesses that need constant refinement.
Automating the Forecasting
Our use of Excel in the previous examples was pretty straightforward. But you can automate that process by using Excel macros. And because you would most likely be doing the same process repeatedly as the metric collection system churns out new usage data, you can benefit greatly by introducing some automation into this curve-fitting business. Other benefits can include the ability to integrate these forecasts into a dashboard, plug them into other spreadsheets, or put them into a database.
An open source program called fityk does a great job of curve-fitting equations to arbitrary data and can handle the same range of equation types as Excel. For our purposes, the full curve-fitting abilities of fityk are a distinct overkill. It was created for analyzing scientific data that can represent wildly dynamic datasets, not just growing and decaying data. Although fityk is primarily a GUI-based application (see Figure 4-13), a command-line version is also available, called cfityk. This version accepts commands that mimic what would have been done with the GUI, so you can use it to automate the curve fitting and forecasting.
The command file used by cfityk is nothing more than a script of actions that you can write using the GUI version. After you choreograph the procedure in the GUI, you can replay the sequence with different data via the command-line tool.
If you have a carriage return–delimited file of x-y data, you can feed it into a command script that can be processed by cfityk. The syntax of the command file is relatively straightforward, particularly for our simple case. Let’s go back to our storage consumption data for an example.
Figure 4-13. The fityk curve-fitting GUI tool
In the code example that follows, we have disk consumption data for a 15-day period, presented in increments of one data point per day. This data is in a file called storage-consumption.xy and appears as displayed here:
1 14321.83119
2 14452.60193
3 14586.54003
4 14700.89417
5 14845.72223
6 15063.99681
7 15250.21164
8 15403.82607
9 15558.81815
10 15702.35007
11 15835.76298
12 15986.55395
13 16189.27423
14 16367.88211
15 16519.57105
The cfityk command file containing our sequence of actions to run a fit (generated by using the GUI) is called fit-storage.fit and appears as shown here:
# Fityk script. Fityk version: 0.8.2 @0 < '/home/jallspaw/storage-consumption.xy' guess Quadratic fit info formula in @0 quit
This script imports our x-y data file, sets the equation type to a second-order polynomial (quadratic equation), fits the data, and then returns back information about the fit, such as the formula used. Running the script gives us these results:
$cfityk ./fit-storage.fit 1> # Fityk script. Fityk version: 0.8.2 2> @0 < '/home/jallspaw/storage-consumption.xy' 15 points. No explicit std. dev. Set as sqrt(y) 3> guess Quadratic New function %_1 was created. 4> fit Initial values: lambda=0.001 WSSR=464.564 #1: WSSR=0.90162 lambda=0.0001 d(WSSR)=-463.663 (99.8059%) #2: WSSR=0.736787 lambda=1e-05 d(WSSR)=-0.164833 (18.2818%) #3: WSSR=0.736763 lambda=1e-06 d(WSSR)=-2.45151e-05 (0.00332729%) #4: WSSR=0.736763 lambda=1e-07 d(WSSR)=-3.84524e-11 (5.21909e-09%) Fit converged. Better fit found (WSSR = 0.736763, was 464.564, -99.8414%). 5> info formula in @0 # storage-consumption 14147.4+146.657*x+0.786854*x^2 6> quit bye...
We now have our formula to fit the data:
-
0.786854x2 + 146.657x + 14147.4
Note how the result looks almost exactly as Excel’s for the same type of curve. Treating the values for x as days and those for y as our increasing disk space, we can plug in our 25-day forecast, which yields the same results as the Excel exercise. Table 4-2 lists the results generated by cfityk.
| Date | Disk available (GB) | y = 0.786854x2 + 146.657x + 14147.4 | |
|---|---|---|---|
| 33 | 08/27 | 20480.00 | 19843.97 |
| 34 | 08/28 | 20480.00 | 20043.34 |
| 35 | 08/29 | 20480.00 | 20244.29 |
| 36 | 08/30 | 20480.00 | 20446.81 |
| 37 | 08/31 | 20480.00 | 20650.91 |
| 38 | 09/01 | 20480.00 | 20856.58 |
| 39 | 09/02 | 20480.00 | 21063.83 |
Being able to perform curve-fitting with a cfityk script makes it possible for you to carry out forecasting on a daily or weekly basis within a cron job, which can be an essential building block for a capacity planning dashboard.
Safety Factors
Web capacity planning can borrow a few useful strategies from the older and better-researched work of mechanical, manufacturing, and structural engineering. These disciplines also need to base design and management considerations around resources and immutable limits. The design and construction of buildings, bridges, and automobiles obviously requires some intimate knowledge of the strength and durability of materials, the loads each component is expected to bear, and what their ultimate failure points are. Does this sound familiar? It should, because capacity planning for web operations shares many of those same considerations and concepts.

Under load, materials such as steel and concrete undergo physical stresses. Some have elastic properties that allow them to recover under light amounts of load, but fail under higher strains. The same concerns exist in servers, networks, or storage. When their resources reach certain critical levels—100 percent CPU or disk usage, for example—they fail. To preempt this failure, engineers apply what is known as a factor of safety to their design. Defined briefly, a factor of safety indicates some margin of resource allocated beyond the theoretical capacity of that resource, to allow for uncertainty in the usage.
Whereas safety factors in the case of mechanical or structural engineering are usually part of the design phase, in web operations they should be considered as an amount of available resources that one leaves aside, with respect to the ceilings established for each class of resource. This will enable those resources to absorb some amount of unexpected increased usage. Resources by which you should calculate safety factors include all those discussed in Chapter 3: CPU, disk, memory, network bandwidth, even entire hosts (if your enterprise runs a very large site). For example, in Chapter 3 we stipulated 85 percent CPU usage as our upper limit for web servers in order to reserve “enough headroom to handle occasional spikes.” In this case, we’re allowing a 15 percent margin of “safety.” When making forecasts, we need to take these safety factors into account and adjust the ceiling values appropriately.
Why a 15 percent margin? Why not 10 or 20 percent? One safety factor is going to be somewhat of a slippery number or educated guess. Some resources, such as caching systems, can also tolerate spikes better than others, so you might want to be less conservative with a margin of safety. You should base the safety margins on “spikes” of usage that you have seen in the past. See Figure 4-14.
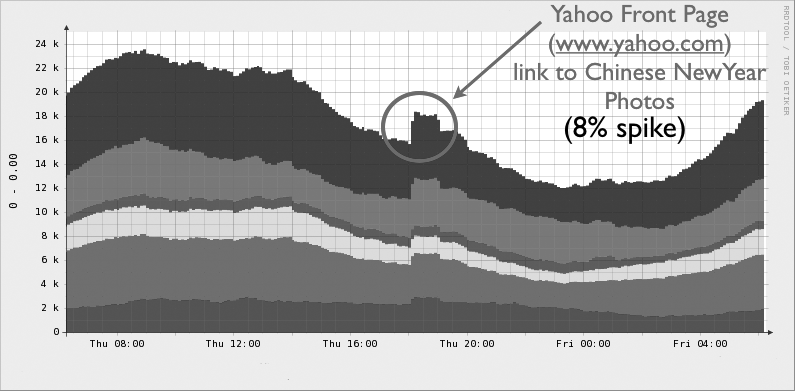
Figure 4-14. Spike in traffic from Yahoo Front Page
Figure 4-14 displays the effect of a typically sized traffic spike Flickr experiences on a regular basis. It’s by no means the largest. Spikes such as this one almost always occur when the front page of yahoo.com posts a prominent link to a group, a photo, or a tag search page on Flickr. This particular spike was fleeting; it lasted only about two hours while the link was up. It caused an eight percent bump in traffic to Flickr’s photo servers. Seeing a 5 to 15 percent increase in traffic like this is quite common, and confirms that our 15 percent margin of safety is adequate.
Procurement
As we’ve demonstrated, with our resource ceilings pinpointed, we can predict when we’ll need more of a particular resource. When we complete the task of predicting when we’ll need more, we can use that timeline to gauge when to trigger the procurement process.
The procurement pipeline is the process by which we obtain new capacity. It’s usually the time it takes to justify, order, purchase, install, test, and deploy any new capacity. Figure 4-15 illustrates the procurement pipeline.
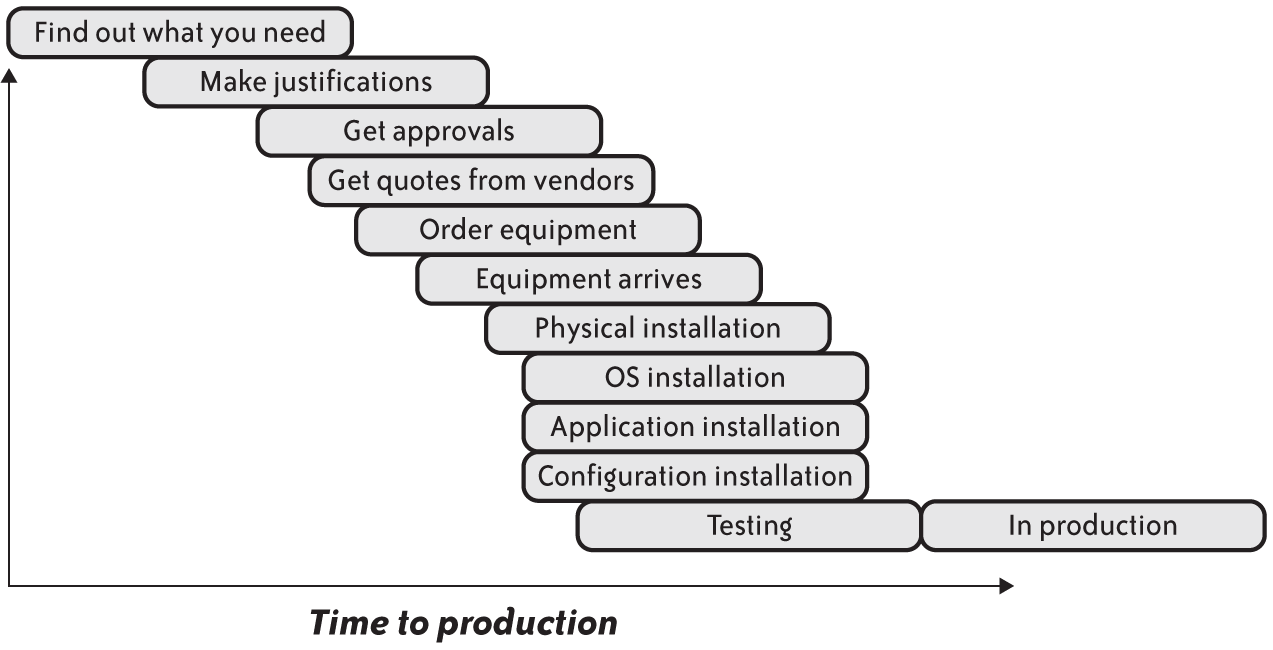
Figure 4-15. Typical procurement pipeline
The tasks outlined in Figure 4-15 vary from one organization to another. In some large organizations, it can take a long time to gain approvals to buy hardware, but delivery can happen quickly. In a startup, approvals might come quickly, but the installation likely proceeds more slowly. Each situation will be different, but the challenge will remain the same: estimate how long the entire process will take, and add some amount of comfortable buffer to account for unforeseen problems. After you have an idea of what that buffer timeline is, you then can work backward to plan capacity.
Recall in our disk storage consumption example, we have current data on our disk consumption up to 8/15/05, and we estimate we’ll run out of space on 8/30/05. Thus, there are exactly two weeks to justify, order, receive, install, and deploy new storage. If the timeline is not met, your storage capacity will run out and you will be forced to trim that consumption in some way. Ideally, this two-week deadline will be long enough to bring new capacity online.
Procurement Time: The Killer Metric
Obviously, the when of ordering equipment is just as important as the what and how much. Procurement timelines outlined earlier hint at how critical it is to keep an eye on how long it will take to get what is needed in production. Sometimes, external influences such as vendor delivery times and physical installation at the datacenter can ruin what started out to be a perfectly timed integration of new capacity.
Startups routinely order servers purely out of the fear that they’ll be needed. Most newly launched companies have developers to work on the product and don’t need to waste money on operations-focused engineers. The developers writing the code are most likely the same people setting up network switches, managing user accounts, installing software, and wearing whatever other hats are necessary to get their companies rolling. The last thing they want to worry about is running out of servers when they launch their new, awesome website. Ordering more servers as needed can be rightly justified in these cases because the hardware costs are more than offset by the costs of preparing a more streamlined and detailed capacity plan.
But as companies mature, optimizations begin to creep in. Code becomes more refined. The product becomes more defined. Marketing begins to realize who their users are. The same holds true for the capacity management process; it becomes more polished and accurate over time.
Just-in-Time Inventory
Toyota Motors developed the first implementations of a Just-in-Time (JIT) inventory practice. It knew there were large costs involved to organize, store, and track excess inventory of automobile parts, so it decided to reduce that “holding” inventory and determine exactly when it needed parts. Having inventory meant wasting money. Instead of maintaining a massive warehouse filled with the thousands of parts to make its cars, Toyota would order and stock only those parts as they were needed. This reduced costs tremendously and gave Toyota a competitive advantage in the 1950s. JIT inventory practice is now part of any modern manufacturing effort.

We can view the costs associated with having auto parts laying around in a warehouse as analogous to having servers installed before they are really needed. Rack space and power consumption in a datacenter cost money, as does the time spent installing and deploying code on the servers. More important, you risk suffering economically as a result of the aforementioned Moore’s Law, which if the forecasts allow it, should motivate you to buy equipment later, rather than sooner.
As soon as you know when the current capacity will top out and how much capacity will be needed to get through to the next cycle of procurement, you should take a few lessons from the JIT inventory playbook, whose sole purpose it is to eliminate wastes of time and money in a given process.
Here are some of the steps in our typical procurement process that you should pay attention to and streamline:
-
Determine the needs
By now, you should be able to assess how much load the current capacity can handle by following the advice given in Chapter 3 to find their ceilings, and you are measuring their usage constantly. Take these numbers to the curve-fitting table and begin making crystal ball predictions. This is fundamental to the capacity planning process.
-
Justify purchases
Add some color and use attention-grabbing fonts on the graphs made in the previous step because these will be shown to the people who will approve the hardware purchases. Spend as much time as needed to ensure that the money-handling audience understands why the enterprise needs additional capacity, why it is needed now, and why more capacity will be needed going forward. Be very clear in the presentations about the downsides of insufficient capacity.
-
Solicit quotes from vendors
Vendors want to sell servers and storage, and you want to buy servers and storage—all is balanced in the universe. On what basis should you choose vendor A over vendor B? Because vendor A might help alleviate some of the fear normally associated with ordering servers through such practices as quick turnarounds on quotes and replacements, discounts on servers ordered later, or discounts tied to delivery times.
-
Order equipment
Can an order be tracked online? Is there a phone number (gasp!) for customer service who can tell you where the order is at all times? Does the datacenter know the machines are coming, and has the staff there factored that into their schedule?
-
Physical installation
How long will it take for the machines to make the journey from a loading dock into a rack and be cabled-up to a working switch? Does the datacenter staff need to get involved or are you racking servers yourself? Are there enough rack screws? Power drill batteries? Crossover cables? How long is this entire process going to take?
-
OS/application/configuration installation
In Chapter 5, we talk about deployment scenarios that involve automatic operating system OS installation, software deployment, and configuration management. However, just because it’s automated doesn’t mean it doesn’t take time and that you shouldn’t be aware of any problems that can arise.
-
Testing
Is there a QA team? Is there a QA environment? Testing an application means having some process by which you can functionally test all the bits to make sure everything is in its right place. Entire books are written on this topic; we would like to just remind you that it’s a necessary step in the journey toward production life as a server.
-
Deploying new equipment
As the saying goes, it’s not over until the fat server sings. Putting a machine into production should be straightforward. When doing so, you should use the same process to measure the capacity of the new servers as outlined in Chapter 3. Maybe you would want to ramp up the production traffic the machine receives by increasing its weight in the load-balanced pool. If this new capacity relieves a bottleneck, you would want to watch any effect that has on the traffic.
The Effects of Increasing Capacity
All of the segments within an infrastructure interact in various ways. Clients make requests to the web servers, which in turn make requests to databases, caching servers, storage, and all sorts of miscellaneous components. Layers of infrastructure work together to respond to users by providing web pages, pieces of web pages, or confirmations that they’ve performed some action, such as uploading a photo.
When one or more of those layers encounters a bottleneck, you need to determine how much more capacity is needed and then deploy it. Depending on how bottlenecked that layer or cluster is, you might observe second-order effects of that new deployment and end up simply moving the traffic jam to yet another part of the architecture. For example, let’s assume that a website involves a web server and a database. One of the ways organizations can help scale their applications is to cache computationally expensive database results. Deploying something like memcached can facilitate this. In a nutshell, it means for certain database queries, you can consult an in-memory cache before accessing the database. This is done primarily for the dual purpose of speeding up the query and reducing load on the database server for results that are frequently returned.
The most noticeable benefit is that the queries that used to take seconds to process might take as little as a few milliseconds, which means a web server will be able to send the response to the client more quickly. Ironically, there’s a side effect to this; when users are not waiting for pages as long, they have a tendency to click links faster, causing more load on the web servers. It’s not uncommon to see memcached deployments turn into web server capacity issues rather quickly.
Long-Term Trends
By now, you should know how to apply the statistics collected in Chapter 3 to immediate needs. But you also might want to view a site from a more global perspective—both in the literal sense (as a site becomes popular internationally), and in a figurative sense, as you look at the issues surrounding the product and the site’s strategy.
Traffic Pattern Changes
As mentioned earlier, getting to know the peaks and valleys of the various resources and application usage is paramount to predicting the future. As you gain more and more history with the metrics, you might be able to perceive more subtle trends that will inform the long-term decisions. For example, let’s take a look at Figure 4-16, which illustrates a typical traffic pattern for a web server.
Figure 4-16 shows a pretty typical daily traffic pattern in the United States. The load rises slowly in the morning, East Coast time, as users begin browsing. These users go to lunch as West Coast users come online, keeping up the load, which finally drops off as people leave work. At this point, the load drops to only those users browsing overnight.
As usage grows, you can expect this graph to grow vertically as more users visit the site during the same peaks and valleys. But if the audience grows more internationally, the bump you would see every day will widen as the number of active user time zones increases. As illustrated in Figure 4-17, you even might see distinct bumps after the US drop-off if the site’s popularity grows in a region further away than Europe.
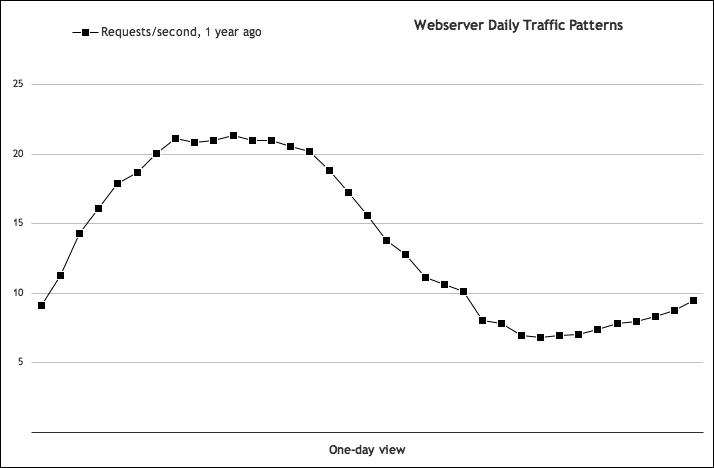
Figure 4-16. Typical daily web server traffic pattern
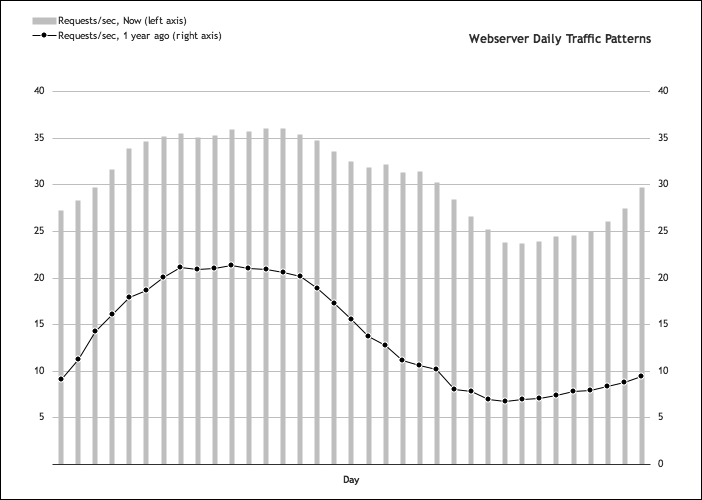
Figure 4-17. Daily traffic patterns grow wider with increasing international usage
Figure 4-17 displays two daily traffic patterns, taken one year apart, and superimposed one atop the other. What once was a smooth bump and decline has become a two-peak bump, due to the global effect of popularity.
Of course, the product and marketing people are probably very aware of the demographics and geographic distribution of the audience, but tying this data to a system’s resources can help you to predict the capacity needs.
Figure 4-17 also shows that the web servers must sustain their peak traffic for longer periods of time. This will indicate when any maintenance windows should be scheduled to minimize the effect of downtime or degraded service to the users. Notice the ratio between the peak and low period has changed, as well. This will affect how many servers you can tolerate losing to failure during those periods, which is effectively the ceiling of a cluster.
It’s important to watch the change in an application’s traffic pattern, not only for operational issues, but to drive capacity decisions, such as whether to deploy any capacity to international datacenters.
Application Usage Changes and Product Planning
A good capacity plan relies not only on system statistics such as peaks and valleys, but user behavior, as well. How users interact with the site is yet another valuable vein of data that you should mine for information to help keep the crystal ball as clear as possible.
If you run an online community, you might have discussion boards in which users create new topics, make comments, and upload media such as video and photos. In addition to the previously discussed system-related metrics such as storage consumption, video- and photo-processing CPU usage, and processing time, here are some other metrics you might want to track:
-
Discussion posts per minute
-
Posts per day, per user
-
Video uploads per day, per user
-
Photo uploads per day, per user
Application usage is just another way of saying user engagement, to borrow a term from the product and marketing folks.
Recall back to our database-planning example. In that example, we found our database ceiling by measuring our hardware’s resources (CPU, disk I/O, memory, etc.), relating them to the database’s resources (queries per second, replication lag), and tying those ceilings to something we can measure from the user interaction perspective (how many photos per user are on each database).
This is where capacity planning and product management tie together. Using system and application statistics histories, we can now predict with some (hopefully increasing) degree of accuracy what we would need to meet future demand. But, again, history is only part of the picture. If the product team is planning new features, you can bet that they’ll affect the capacity plan in some way.
Historically, corporate culture has isolated product development from engineering. Product people develop ideas and plans for the product, whereas engineering develops and maintains the product after it’s on the market. Both groups make forecasts for different ends, but the data used in those forecasts should tie together.
One of the best practices for a capacity planner is to develop an ongoing conversation with product management. Understanding the timeline for new features is critical to guaranteeing capacity needs don’t interfere with product improvements. Having enough capacity is an engineering requirement, in the same way development time and resources are.
Iteration and Calibration
Producing forecasts by curve-fitting the system and application data isn’t the end of capacity planning. To make it accurate, you need to revisit the plan, refit the data, and adjust accordingly.

Ideally, you should have periodic reviews of the forecasts. You should check how the capacity is doing against the predictions on a weekly, or even daily, basis. If you are nearing capacity on one or more resources and are awaiting delivery of new hardware, you might keep a much closer eye on it. The important thing to remember is that the plan will be accurate only if you consistently reexamine the trends and question the past predictions.
As an example, we can revisit our simple storage consumption data. We made a forecast based on data we gleaned for a 15-day period, from 7/26/05 to 8/09/05. We also discovered that on 8/30/05 (roughly two weeks later), we expected to run out of space if we didn’t deploy more storage. More accurately, we were slated to reach 20,446.81 GB of space, which would have exceeded our total available space, which is 20,480 GB. How accurate was that prediction? Figure 4-18 shows what actually happened.
As it turned out, we had a little more time than we thought—about four days more. We made a guess based on the trend at the time, which ended up being inaccurate but at least in favor of allowing more time to integrate new capacity. Sometimes, forecasts can either widen the window of time (as in this case) or narrow it. This is why the process of revisiting the forecasts is critical; it’s the only way to adjust the capacity plan over time. Every time you update the capacity plan, you should go back and evaluate how the previous forecasts fared.
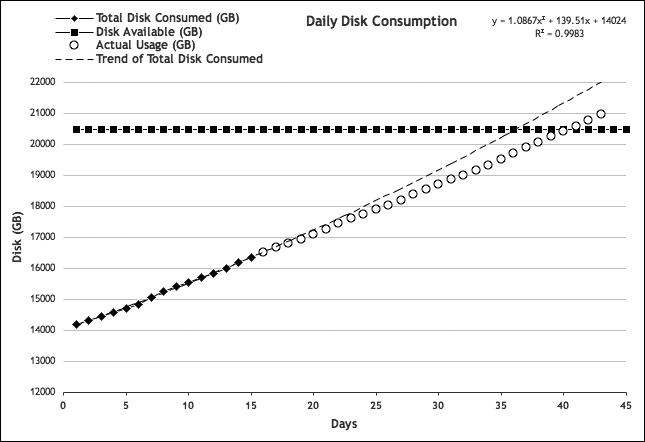
Figure 4-18. Disk consumption: predicted trend versus actual
Given that curve-fitting and trending results tend to improve as you add more data points, you should have a moving window to make forecasts. The width of that forecasting window will vary depending on how long the procurement process takes. For example, if you know that it’s going to take three months on average to order, install, and deploy capacity, you would want the forecast goal to be three months out, each time. As the months pass, you would want to add the influence of most recent events to the past data and to recompute the predictions, as is illustrated in Figure 4-19.

Figure 4-19. A moving window of forecasts
Best Guesses
This process of plotting, prediction, and iteration can provide a lot of confidence in how to manage the capacity. You would have accumulated a lot of data about how the current infrastructure is performing and how close each piece is to their respective ceilings, taking into account comfortable margins of safety. This confidence is important because the capacity planning process (as we’ve seen) is just as much about educated guessing and luck as it is about hard science and math. Hopefully, the iterations in the planning process will point out any flawed assumptions in the working data, but it should also be said that the ceilings you are using could become flawed or obsolete over time, as well.

Just as the ceilings can change depending on the hardware specifications of a server, so too can the actual metric that you are assuming as the ceiling. For example, the defining metric of a database might be disk I/O, but after upgrading to a newer and faster disk subsystem, you might find the limiting factor isn’t disk I/O anymore, but the single gigabit network card you’re using. It bears mentioning that picking the right metric to follow can be difficult because not all bottlenecks are obvious, and the metric you choose can change as the architecture and hardware limitations change.
During this process, you might notice seasonal variations. College starts in the fall, so there might be increased usage as students browse the site for materials related to their studies (or just to avoid going to class). As another example, the holiday season in November and December almost always witnesses a bump in traffic, especially for sites involving retail sales. At Flickr, we saw both of those seasonal effects.
Taking into account these seasonal or holiday variations should be yet another influence on how wide or narrow the forecasting window might be. Obviously, the more often you recalculate a forecast, the better prepared you would be, and the sooner you would notice unexpected variations.
Diagonal Scaling Opportunities
As we pointed out near the beginning of the chapter, predicting capacity requires two essential bits of information: the ceilings and the historical data. The historical data is etched in stone. The ceilings are not, because each ceiling is indicative of a particular hardware configuration. Performance tuning can hopefully change those ceilings for the better, but upgrading the hardware to newer and better technology is also an option.
As we mentioned at the beginning of the book, new technology can dramatically change how much horsepower you can squeeze from a single server. The forecasting process shown in this chapter allows you to not only track where you’re headed on a per-node basis, but also to think about which segments of the architecture you might possibly move to new hardware options.
Summary
Predicting capacity is an ongoing process that requires as much intuition as it does math to help one make accurate forecasts. Even simple web applications need to be attended, and some of this crystal-ball work can be tedious. Automating as much of the process as you can will help you to stay ahead of the procurement process. Taking the time to connect the metric collection systems to trending software, such as cfityk, will prove to be invaluable as you develop a capacity plan that is easily adaptable. Ideally, you would want some sort of a capacity dashboard that can be referred to at any point in time to inform purchasing, development, and operational decisions.
The overall process in making capacity forecasts is pretty simple:
-
Determine, measure, and graph the defining metric for each resource.
Example: disk consumption
-
Apply the constraints to each resource.
Example: total available disk space
-
Use trending analysis (curve-fitting) to illustrate when the usage will exceed the constraint.
Example: find the day when you will run out of disk space
Readings
-
G. E. Moore. (1965). Cramming More Components onto Integrated Circuits.
-
M. A. Cusumano and D. B. Yoffie. (2016). Extrapolating from Moore’s Law.
-
P. E. Denning and T. G. Lewis. (2017). Exponential Laws of Computing Growth.
Buy or Lease
-
R. F. Vancil. (1961). Lease or Borrow: New Method of Analysis.
-
K. D. Ripley. (1962). Leasing: a means of financing that business should not overlook.
-
R. W. Johnson. (1972). Analysis of the Lease-or-Buy Decision.
-
W. L. Sartoris and R. S. Paul. (1973). Lease Evaluation: Another Capital Budgeting Decision.
-
G. B. Harwood and R. H. Hermanson. (1976). Lease-or-Buy Decisions.
-
A. Sykes. (1976). The Lease-Buy Decision - A Survey of Current Practice in 202 Companies.
-
Jack E. Gaumnitz and Allen Ford. (1978). The Lease or Sell Decision.
-
A. C. C. Herst. (1984). Lease or Purchase: Theory and Practice.
-
B. H. Nunnally, J. R. and D. A. Plath. (1989). Leasing Versus Borrowing: Evaluating Alternative Forms of Consumer Credit.
-
F. J. Fabozzi. (2008). Lease versus Borrow-to-Buy Analysis.
-
E. Walker. (2009). The Real Cost of a CPU Hour.
-
E. Walker et al. (2010). To Lease or Not to Lease from Storage Clouds.
Time–Series Forecasting
-
G. E. P. Box, et al. (2015). Time–Series Analysis: Forecasting and Control (5th ed.).
-
P. J. Brockwell and R. A. Davis. (2002). Introduction to Time Series and Forecasting (2nd ed.).
Measurement
-
Y. Zhang, et al. (2016). Treadmill: Attributing the Source of Tail Latency through Precise Load Testing and Statistical Inference.
Resources
-
“Moore’s Law Is Dead. Now What?” (2016) http://bit.ly/moores-law-dead.
-
L. Muehlhauser. (2014). Exponential and non-exponential trends in information technology.
Get The Art of Capacity Planning, 2nd Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

