Chapter 1. Introducing Trino
So you heard of Trino and found this book. Or maybe you are just browsing this first section and wondering whether you should dive in. In this introductory chapter, we discuss the problems you may be encountering with the massive growth of data creation, and the value locked away within that data. Trino is a key enabler to working with all the data and providing access to it with proven successful tools around Structured Query Language (SQL).
The design and features of Trino enable you to get better insights, beyond those accessible to you now. You can gain these insights faster, as well as get information that you could not get in the past because it cost too much or took too long to obtain. And for all that, you end up using fewer resources and therefore spending less of your budget, which you can then use to learn even more!
We also point you to more resources beyond this book but, of course, we hope you join us here first.
The Problems with Big Data
Everybody is capturing more and more data from device metrics, user behavior tracking, business transactions, location data, software and system testing procedures and workflows, and much more. The insights gained from understanding that data and working with it can make or break the success of any initiative, or even a company.
At the same time, the diversity of storage mechanisms available for data has exploded: relational databases, NoSQL databases, document databases, key-value stores, object storage systems, and so on. Many of them are necessary in today’s organizations, and it is no longer possible to use just one of them. As you can see in Figure 1-1, dealing with this can be a daunting task that feels overwhelming.
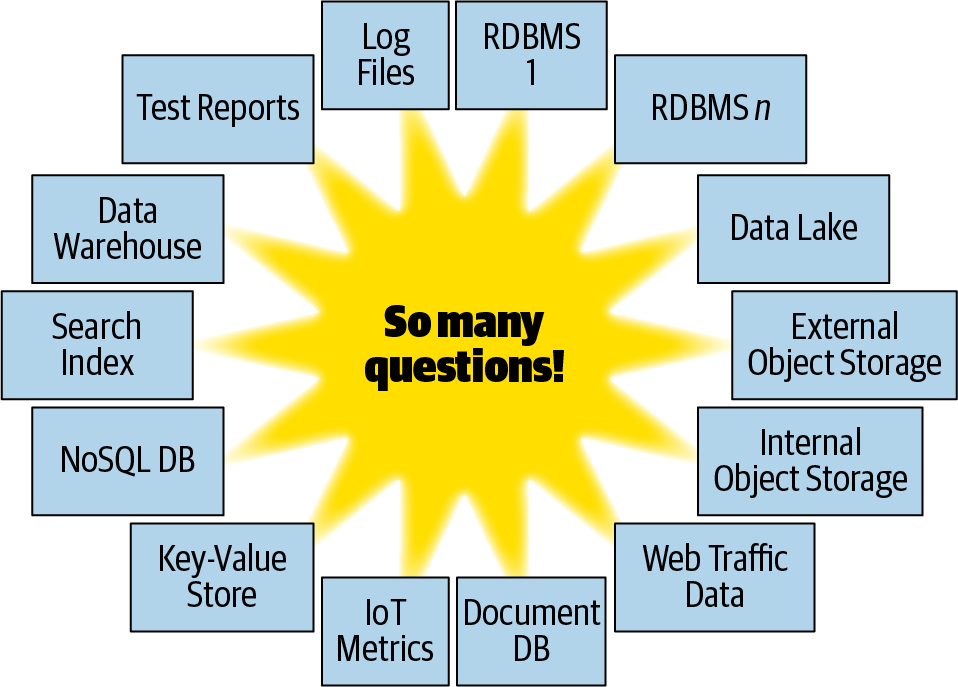
Figure 1-1. Big data can be overwhelming
In addition, all these different systems do not allow you to query and inspect the data with standard tools. Different query languages and analysis tools for niche systems are everywhere. Meanwhile, your business analysts are used to the industry standard, SQL. A myriad of powerful tools rely on SQL for analytics, dashboard creation, rich reporting, and other business intelligence work.
The data is distributed across various silos, and some of them can not even be queried at the necessary performance for your analytics needs. Other systems, unlike modern cloud applications, store data in monolithic systems that cannot scale horizontally. Without these capabilities, you are narrowing the number of potential use cases and users, and therefore the usefulness of the data.
The traditional approach of creating and maintaining large, dedicated data warehouses has proven to be very expensive in organizations across the globe. Most often, this approach is also found to be too slow and cumbersome for many users and usage patterns.
You can see the tremendous opportunity for a system to unlock all this value.
Trino to the Rescue
Trino is capable of solving all these problems, and of unlocking new opportunities with federated queries to disparate systems, parallel queries, horizontal cluster scaling, and much more. You can see the Trino project logo in Figure 1-2.

Figure 1-2. Trino logo with the mascot “Commander Bun Bun”
Trino is an open source, distributed SQL query engine. It was designed and written from the ground up to efficiently query data against disparate data sources of all sizes, ranging from gigabytes to petabytes. Trino breaks the false choice between having fast analytics using an expensive commercial solution, or using a slow “free” solution that requires excessive hardware.
Designed for Performance and Scale
Trino is a tool designed to efficiently query vast amounts of data by using distributed execution. If you have terabytes or even petabytes of data to query, you are likely using tools such as Apache Hive that interact with Hadoop and its Hadoop Distributed File System (HDFS). Trino is designed as an alternative to these tools to more efficiently query that data.
Analysts, who expect SQL response times from milliseconds for real-time analysis to seconds and minutes, should use Trino. Trino supports SQL, commonly used in data warehousing and analytics for analyzing data, aggregating large amounts of data, and producing reports. These workloads are often classified as online analytical processing (OLAP).
Even though Trino understands and can efficiently execute SQL, Trino is not a database, as it does not include its own data storage system. It is not meant to be a general-purpose relational database that serves to replace Microsoft SQL Server, Oracle Database, MySQL, or PostgreSQL. Further, Trino is not designed to handle online transaction processing (OLTP). This is also true of other databases designed and optimized for data warehousing or analytics, such as Teradata, Netezza, Vertica, and Amazon Redshift.
Trino leverages both well-known and novel techniques for distributed query processing. These techniques include in-memory parallel processing, pipelined execution across nodes in the cluster, a multithreaded execution model to keep all the CPU cores busy, efficient flat-memory data structures to minimize Java garbage collection, and Java bytecode generation. A detailed description of these complex Trino internals is beyond the scope of this book. For Trino users, these techniques translate into faster insights into your data at a fraction of the cost of other solutions.
SQL-on-Anything
Trino was initially designed to query data from HDFS. And it can do that very efficiently, as you learn later. But that is not where it ends. On the contrary, Trino is a query engine that can query data from object storage, relational database management systems (RDBMSs), NoSQL databases, and other systems, as shown in Figure 1-3.
Trino queries data where it lives and does not require a migration of data to a single location. So Trino allows you to query data in HDFS and other distributed object storage systems. It allows you to query RDBMSs and other data sources. As such, it can really query data wherever it lives and therefore be a replacement to the traditional, expensive, and heavy extract, transform, and load (ETL) processes. Or at a minimum, it can help you with them and lighten the load. So Trino is clearly not just another SQL-on-Hadoop solution.
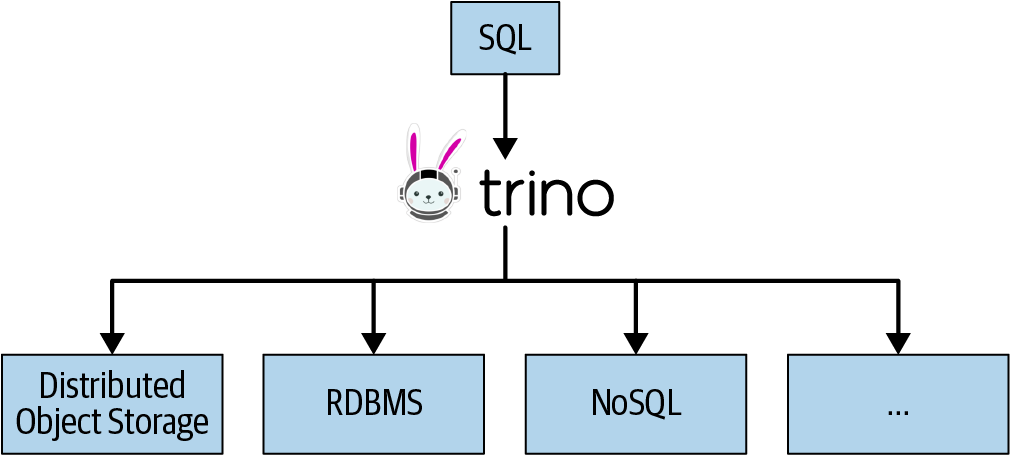
Figure 1-3. SQL support for a variety of data sources with Trino
Object storage systems include Amazon Web Services (AWS) Simple Storage Service (S3), Microsoft Azure Blob Storage, Google Cloud Storage, and S3-compatible storage such as MinIO and Ceph. Trino can query traditional RDBMSs such as Microsoft SQL Server, PostgreSQL, MySQL, Oracle, Teradata, and Amazon Redshift. Trino can also query NoSQL systems such as Apache Cassandra, Apache Kafka, MongoDB, or Elasticsearch. Trino can query virtually anything and is truly a SQL-on-Anything system.
For users, this means that suddenly they no longer have to rely on specific query languages or tools to interact with the data in those specific systems. They can simply leverage Trino and their existing SQL skills and their well-understood analytics, dashboarding, and reporting tools. These tools, built on top of using SQL, allow analysis of those additional data sets, which are otherwise locked in separate systems. Users can even use Trino to query across different systems with the SQL they know.
Separation of Data Storage and Query Compute Resources
Trino is not a database with storage; rather, it simply queries data where it lives. When using Trino, storage and compute are decoupled and can be scaled independently. Trino represents the compute layer, whereas the underlying data sources represent the storage layer.
This allows Trino to scale up and down its compute resources for query processing, based on analytics demand to access this data. There is no need to move your data, and provision compute and storage to the exact needs of the current queries, or change that regularly, based on your changing query needs.
Trino can scale the query power by scaling the compute cluster dynamically, and the data can be queried right where it lives in the data source. This characteristic allows you to greatly optimize your hardware resource needs and therefore reduce cost.
Trino Use Cases
The flexibility and powerful features of Trino allow you to decide for yourself how exactly you are using Trino, and what benefits you value and want to take advantage of. You can start with only one small use for a particular problem. Most Trino users start like that.
Once you and other Trino users in your organization have gotten used to the benefits and features, you’ll discover new situations. Word spreads, and soon you see a myriad of needs being satisfied by Trino accessing a variety of data sources.
In the following section, we discuss several of these use cases. Keep in mind that you can expand your use to cover them all. On the other hand, it is also perfectly fine to solve one particular problem with Trino. Just be prepared to like Trino and increase its use after all.
One SQL Analytics Access Point
RDBMSs and the use of SQL have been around a long time and have proven to be very useful. No organization runs without them. In fact, most companies run multiple systems. Large commercial databases like Oracle Database or IBM DB2 are probably backing your enterprise software. Open source systems like MariaDB or PostgreSQL may be used for other solutions and a couple of in-house applications.
As a consumer and analyst, you likely run into numerous problems:
-
Sometimes you do not know where data is even available for you to use, and only tribal knowledge in the company, or years of experience with internal setups, can help you find the right data.
-
Querying the various source databases requires you to use different connections, as well as different queries running different SQL dialects. They are similar enough to look the same, but they behave just differently enough to cause confusion and the need to learn the details.
-
You cannot combine the data from different systems in a query without using the data warehouse.
Trino allows you to get around these problems. You can expose all these databases in one location: Trino.
You can use one SQL standard to query all systems—standardized SQL, functions, and operators supported by Trino.
All your dashboarding and analytics tools, and other systems for your business intelligence needs, can point to one system, Trino, and have access to all data in your organization.
Access Point to Data Warehouse and Source Systems
When organizations find the need to better understand and analyze data in their numerous RDBMSs, the creation and maintenance of data warehouse systems comes into play. Select data from various systems is then going through complex ETL processes and, often via long-running batch jobs, ends up in a tightly controlled, massive data warehouse.
While this helps you a lot in many cases, as a data analyst, you now encounter new problems:
-
Now you have another entry point, in addition to all the databases themselves, for your tools and queries.
-
The data you specifically need today is not in the data warehouse. Getting the data added is a painful, expensive process full of hurdles.
Trino allows you to add any data warehouse database as a data source, just like any other relational database.
If you want to dive deeper into a data warehouse query, you can do it right there in the same system. You can access the data warehouse and the source database system in the same place and even write queries that combine them. Trino allows you to query any database in the same system, data warehouse, source database, and any other database.
Provide SQL-Based Access to Anything
The days of using only RDBMSs are long gone. Data is now stored in many disparate systems optimized for relevant use cases. Object-based storage, key-value stores, document databases, graph databases, event-streaming systems, and other so-called NoSQL systems all provide unique features and advantages.
At least some of these systems are in use in your organization, holding data that’s crucial for understanding and improving your business.
Of course, all of these systems also require you to use different tools and technologies to query and work with the data.
At a minimum, this is a complex task with a huge learning curve. More likely, however, you end up only scratching the surface of your data and not really gaining a complete understanding. You lack a good way to query the data. Tools to visualize and analyze in more detail are hard to find or simply don’t exist.
Trino, on the other hand, allows you to connect to all these systems as a data source. It exposes the data to query with standard American National Standards Institute (ANSI) SQL and all the tooling using SQL, as shown in Figure 1-4.
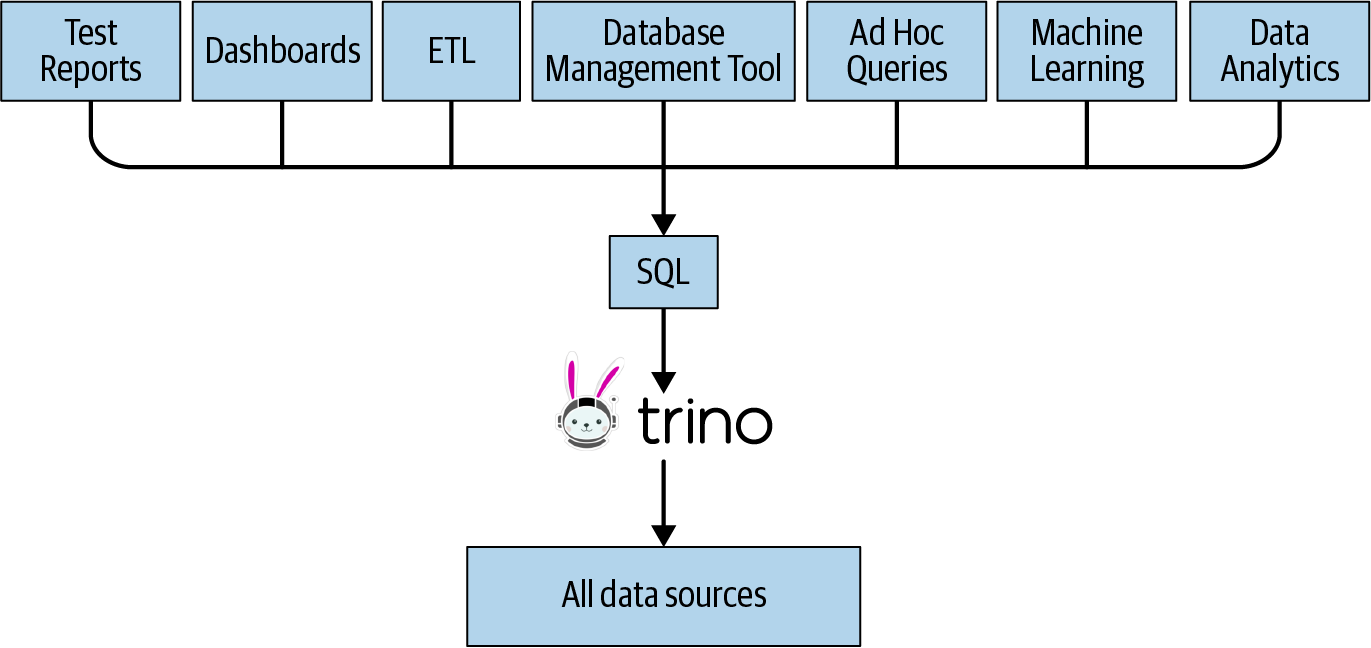
Figure 1-4. One SQL access point for many use cases to all data sources
So with Trino, understanding the data in all these vastly different systems becomes much simpler, or even possible, for the first time.
Federated Queries
Exposing all the data silos in Trino is a large step toward understanding your data. You can use SQL and standard tools to query them all. However, often the questions you want answered require you to reach into the data silos, pull aspects out of them, and then combine them in a local manner.
Trino allows you to do that by using federated queries. A federated query is a SQL query that references and uses different databases and schemas from entirely different systems in the same statement. All the data sources in Trino are available for you to query at the same time, with the same SQL in the same query.
You can define the relationships between the user-tracking information from your object storage with the customer data in your RDBMS. If your key-value store contains more related information, you can hook it into your query as well.
Using federated queries with Trino allows you to gain insights that you could not learn about otherwise.
Semantic Layer for a Virtual Data Warehouse
Data warehouse systems have created not only huge benefits for users but also a burden on organizations:
-
Running and maintaining the data warehouse is a large, expensive project.
-
Dedicated teams run and manage the data warehouse and the associated ETL processes.
-
Getting the data into the warehouse requires users to break through red tape and typically takes too much time.
Trino, on the other hand, can be used as a virtual data warehouse. It can be used to define your semantic layer by using one tool and standard ANSI SQL. Once all the databases are configured as data sources in Trino, you can query them. Trino provides the necessary compute power to query the storage in the databases. Using SQL and the supported functions and operators, Trino can provide you the desired data straight from the source. There is no need to copy, move, or transform the data before you can use it for your analysis.
Thanks to the standard SQL support against all connected data sources, you can create the desired semantic layer for querying from tools and end users in a simpler fashion. And that layer can encompass all underlying data sources without the need to migrate any data. Trino can query the data at the source and storage level.
Using Trino as this “on-the-fly data warehouse” provides organizations the potential to enhance their existing data warehouse with additional capabilities, or even to avoid building and maintaining a warehouse altogether.
Data Lake Query Engine
The term data lake is often used for a large HDFS or similar distributed object storage system into which all sorts of data is dumped without much thought about accessing it. Trino unlocks this to become a useful data warehouse. In fact, Trino emerged from Facebook as a way to tackle faster and more powerful querying of a very large Hadoop data warehouse than what Hive and other tools could provide. This led to the Trino Hive connector, discussed in “Hive Connector for Distributed Storage Data Sources”.
Modern data lakes now often use other object storage systems beyond HDFS from cloud providers or other open source projects. Trino is able to use the Hive connector against any of them and hence enable SQL-based analytics on your data lake, wherever it is located and however it stores the data.
SQL Conversions and ETL
With support for RDBMSs and other data storage systems alike, Trino can be used to move data. SQL, and the rich set of SQL functions available, allow you to query data, transform it, and then write it to the same data source or any other data source.
In practice, this means that you can copy data out of your object storage system or key-value store and into a RDBMS, and use it for your analytics going forward. Of course, you can also transform and aggregate the data to gain new understanding.
On the other hand, it is also common to take data from an operational RDBMS, or maybe an event-streaming system like Kafka, and move it into a data lake to ease the burden on the RDBMS in terms of querying by many analysts. ETL processes, now often also called data preparation, can be an important part of this process to improve the data and create a data model better suited for querying and analysis.
In this scenario, Trino is a critical part of an overall data management solution.
Better Insights Due to Faster Response Times
Asking complex questions and using massive data sets always runs into limitations. It might end up being too expensive to copy the data and load it into your data warehouse and analyze it there. The computations require too much compute power to be able to run them at all, or it takes numerous days to get an answer.
Trino avoids data copying by design. Parallel processing and heavy optimizations regularly lead to performance improvements for your analysis with Trino.
If a query that used to take three days can now run in 15 minutes, it might be worth running it after all. And the knowledge gained from the results gives you an advantage and the capacity to run yet more queries.
These faster processing times of Trino enable better analytics and results.
Big Data, Machine Learning, and Artificial Intelligence
The fact that Trino exposes more and more data to standard tooling around SQL, and scales querying to massive data sets, makes it a prime tool for big data processing. Now this often includes statistical analysis and grows in complexity toward machine learning and artificial intelligence systems. With the support for R and other tools, Trino definitely has a role to play in these use cases.
Other Use Cases
In the prior sections, we provided a high-level overview of Trino use cases. New use cases and combinations are emerging regularly.
In Chapter 13, you can learn details about the use of Trino by some well-known companies and organizations. We present that information toward the end of the book so you can first gain the knowledge required to understand the data at hand by reading the following chapters.
Trino Resources
Beyond this book, many more resources are available that allow you to expand your knowledge about Trino. In this section, we enumerate the important starting points. Most of them contain a lot of information and include pointers to further resources.
Website
The Trino Software Foundation governs the community of the open source Trino project and maintains the project website. You can see the home page in Figure 1-5. The website contains documentation, contact details, community blog posts with the latest news and events, and other information at https://trino.io.
Figure 1-5. Home page of Trino website at trino.io
Documentation
The detailed documentation for Trino is maintained as part of the code base and is available on the website. It includes high-level overviews as well as detailed reference information about the SQL support, functions and operators, connectors, configuration, and much more. You also find release notes with details of latest changes there. Get started at https://trino.io/docs.
Community Chat
The community of beginner, advanced, and expert users, as well as the contributors and maintainers of Trino, is very supportive and actively collaborates every day on the community chat available at https://trinodb.slack.com.
Join the general channel, and then check out the numerous channels focusing on various topics such as bug triage, releases, and development.
Note
You can find Matt, Manfred, and Martin on the community chat nearly every day, and we would love to hear from you there.
Source Code, License, and Version
Trino is an open source project distributed under the Apache License, v2 with the source code managed and available in the Git repository at https://github.com/trinodb/trino.
The trinodb organization at
https://github.com/trinodb contains numerous
other repositories related to the project, such as the source code of the
website, clients, other components, or the contributor license management
repository.
Trino is an active open source project with frequent releases. By using the most recent version, you are able to take advantage of the latest features, bug fixes, and performance improvements. This book refers to, and uses, the latest Trino version 354 at the time of writing. If you choose a different and more recent version of Trino, it should work the same as described in this book. While it’s unlikely you’ll run into issues, it is important to refer to the release notes and documentation for any changes.
Contributing
As we’ve mentioned, Trino is a community-driven, open source project, and your contributions are welcome and encouraged. The project is very active on the community chat, and committers and other developers are available to help there.
Here are a few tasks to get started with contributing:
-
Check out the Developer Guide section of the documentation.
-
Learn to build the project from source with instructions in the README file.
-
Read the research papers linked on the Community page of the website.
-
Read the Code of Conduct from the same page.
-
Find an issue with the label good first issue.
-
Sign the contributor license agreement (CLA).
The project continues to receive contributions with a wide range of complexity—from small documentation improvements, to new connectors or other plug-ins, all the way to improvements deep in the internals of Trino.
Of course, any work you do with and around Trino is welcome in the community. This certainly includes seemingly unrelated work such as writing blog posts, presenting at user group meetings or conferences, or writing and managing a plug-in on your own, maybe to a database system you use.
Overall, we encourage you to work with the team and get involved. The project grows and thrives with contributions from everyone. We are ready to help. You can do it!
Book Repository
We provide resources related to this book—such as configuration file examples, SQL queries, data sets and more—in a Git repository for your convenience.
Find it at https://github.com/trinodb/trino-the-definitive-guide,
and download the content as an archive file or clone the repository with git.
Feel free to create a pull request for any corrections, desired additions, or file issues if you encounter any problems.
Iris Data Set
In later sections of this book, you are going to encounter example queries and use cases that talk about iris flowers and the iris data set. The reason is a famous data set, commonly used in data science classification examples, which is all about iris flowers.
The data set consists of one simple table of 150 records and columns with values for sepal length, sepal width, petal length, petal width, and species.
The small size allows users to test and run queries easily and perform a wide range of analyses. This makes the data set suitable for learning, including for use with Trino. You can find out more about the data set on the Wikipedia page about it.
Our book repository contains the directory iris-data-set with the data in comma-separated values (CSV) format, as well as a SQL file to create a table and insert it. After reading Chapter 2 and “Trino Command-Line Interface”, the following instructions are easy to follow.
You can use the data set by first copying the etc/catalog/memory.properties file into the same location as your Trino installation and restarting Trino.
Now you can use the Trino CLI to get the data set into the iris table in the
default schema of the memory catalog:
$trino -f iris-data-set/iris-data-set.sql USE CREATE TABLE INSERT:150rows
Confirm that the data can be queried:
$trino --execute'SELECT * FROM memory.default.iris;'"5.1","3.5","1.4","0.2","setosa""4.9","3.0","1.4","0.2","setosa""4.7","3.2","1.3","0.2","setosa"...
Alternatively, you can run the queries in any SQL management tool connected to Trino; for example, with the Java Database Connectivity (JDBC) driver described in “Trino JDBC Driver”.
Later sections include example queries to run with this data set in Chapter 8 and Chapter 9, as well as information about the memory connector in “Memory Connector”.
Flight Data Set
Similar to the iris data set, the flight data set is used later in this book for example queries and usage. The data set is a bit more complex than the iris data set, consisting of lookup tables for carriers, airports, and other information, as well as transactional data about specific flights. This makes the data set suitable for more complex queries using joins and for use in federated queries, where different tables are located in different data sources.
The data is collected from the Federal Aviation Administration (FAA) and curated for analysis. The flights table
schema is fairly large, with a subset of the available columns shown in Table 1-1.
flightdate |
airlineid |
origin |
dest |
arrtime |
deptime |
Each row in the data set represents either a departure or an arrival of a flight at an airport in the United States.
The book repository—see “Book Repository”—contains a separate folder, flight-data-set. It contains instructions on how to import the data into different database systems, so that you can hook them up to Trino and run the example queries.
A Brief History of Trino
In 2008, Facebook open sourced Hive, later to become Apache Hive. Hive became widely used within Facebook for running analytics against data in HDFS on its very large Apache Hadoop cluster.
Data analysts at Facebook used Hive to run interactive queries on its large data warehouse. Before Presto existed at Facebook, all data analysis relied on Hive, which was not suitable for interactive queries at Facebook’s scale. In 2012, its Hive data warehouse was 250 petabytes in size and needed to handle hundreds of users issuing tens of thousands of queries each day. Hive started to hit its limit within Facebook and did not provide the ability to query other data sources within Facebook.
Presto was designed from the ground up to run fast queries at Facebook scale. Rather than create a new system to move the data to, Presto was designed to read the data from where it is stored via its pluggable connector system. One of the first connectors developed for Presto was the Hive connector; see “Hive Connector for Distributed Storage Data Sources”. This connector queries data stored in a Hive data warehouse directly.
In 2012, four Facebook engineers started Presto development to address the performance, scalability, and extensibility needs for analytics at Facebook. From the beginning, the intent was to build Presto as an open source project. At the beginning of 2013, the initial version of Presto was rolled out in production at Facebook. By the fall of 2013, Presto was officially open sourced by Facebook. Seeing the success at Facebook, other large web-scale companies started to adopt Presto, including Netflix, LinkedIn, Treasure Data, and others. Many companies continued to follow.
In 2015, Teradata announced a large commitment of 20 engineers contributing to Presto, focused on adding enterprise features such as security enhancements and ecosystem tool integration. Later in 2015, Amazon added Presto to its AWS Elastic MapReduce (EMR) offering. In 2016, Amazon announced Athena, in which Presto serves as a major foundational piece. And 2017 saw the creation of Starburst, a company dedicated to driving the success of Presto everywhere.
At the end of 2018, the original creators of Presto left Facebook and founded the Presto Software Foundation to ensure that the project remains collaborative and independent. The project came to be known as PrestoSQL. The whole community of contributors and users moved to the PrestoSQL codebase with the founders and maintainers of the project. Since then, the innovation and growth of the project has accelerated even more.
The end of 2020 saw another milestone of the project. In order to reduce confusion between PrestoSQL, the legacy PrestoDB project, and other versions, the community decided to rename the project. After a long search for a suitable name, Trino was chosen. The code, website and everything surrounding the project was updated to use Trino. The foundation was renamed to Trino Software Foundation. The last release under the PrestoSQL banner was 350. Versions 351 and later use Trino. The community welcomed and celebrated the change, moved with the project, and chose a name for the new mascot, Commander Bun Bun.
Today, the Trino community thrives and grows, and Trino continues to be used at large scale by many well-known companies. The project is maintained by a flourishing community of developers and contributors from many companies across the world, including Amazon, Bloomberg, Eventbrite, Gett, Google, Line, LinkedIn, Lyft, Netflix, Pinterest, Qubole, Red Hat, Salesforce, Shopify, Starburst, Treasure Data, Varada, Zuora, and the many customers of these users.
Conclusion
In this chapter, we introduced you to Trino. You learned more about some of its features, and we explored possible use cases together.
In Chapter 2, you get Trino up and running, connect a data source, and see how you can query the data.
Get Trino: The Definitive Guide now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

