Working with the DOM
The Document Object Model
The Document Object Model, or DOM, is a convention for describing the structure of an HTML document, and it’s at the heart of interacting with the browser.
Conceptually, the DOM is a tree. A tree consists of nodes: every node has a parent (except for the root node), and zero or more child nodes. The root node is the document, and it consists of a single child, which is the <html> element. The <html> element, in turn, has two children: the <head> element and the <body> element (Figure 1-1 is an example DOM).
Every node in the DOM tree (including the document itself) is an instance of the Node class (not to be confused with Node.js, the subject of the next chapter). Node objects have a parentNode and childNodes properties, as well as identifying properties such as nodeName and nodeType.
Note
The DOM consists entirely of nodes, only some of which are HTML elements. For example, a paragraph tag (<p>) is an HTML element, but the text it contains is a text node. Very often, the terms node and element are used interchangeably, which is rarely confusing, but not technically correct. In this chapter, we’ll mostly be dealing with nodes that are HTML elements, and when we say “element” we mean “element node.”
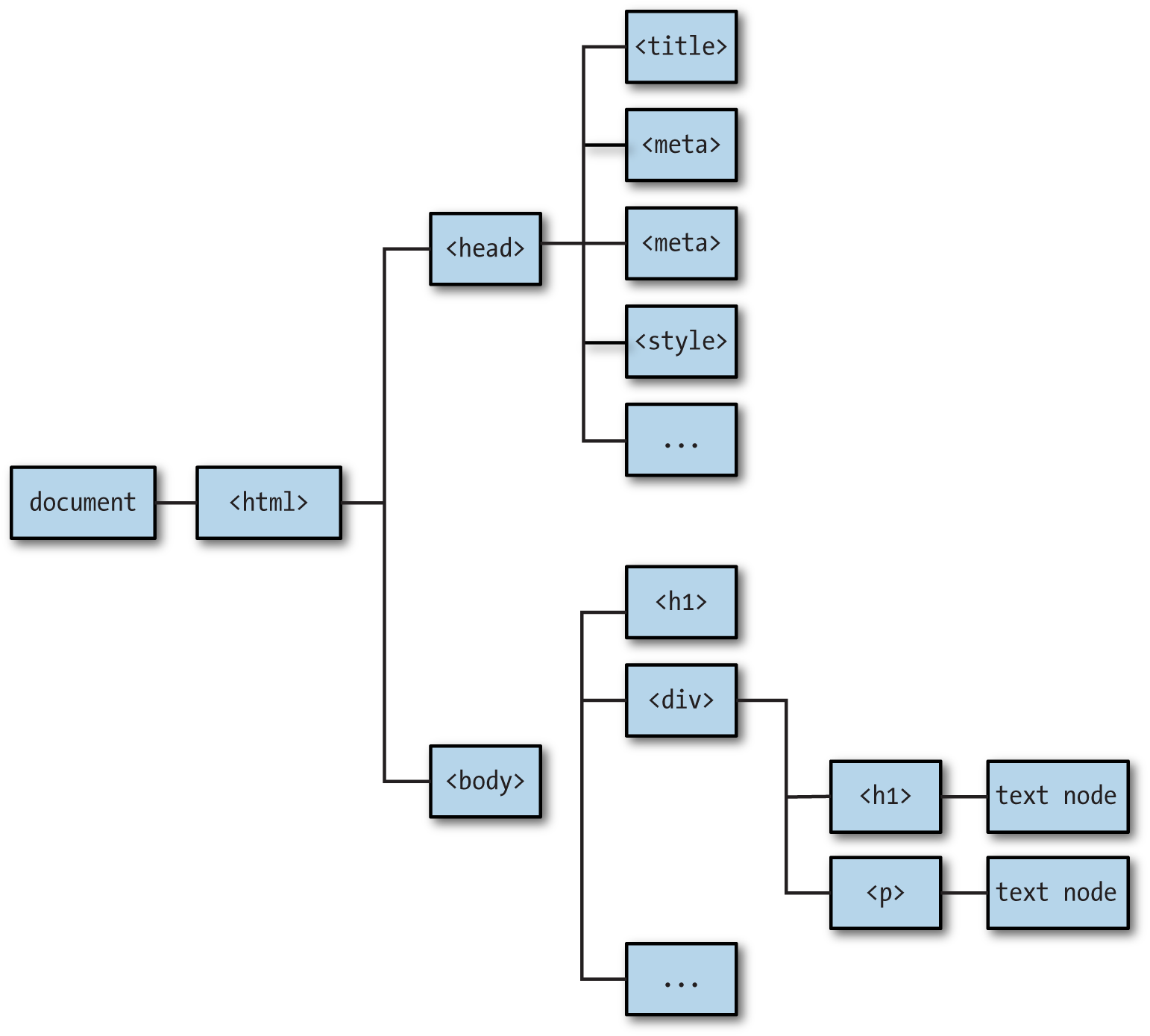
Figure 1-1. DOM tree
For the following examples, we’ll use a very simple HTML file to demonstrate these features. Create a file called ...
Get Working with the DOM now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

