Chapter 5. Dealing with Failure
Life would be so much easier if failures never happened. Of course, without failures, much of the need for ZooKeeper would also go away. To effectively use ZooKeeper, it is important to understand the kinds of failures that happen and how to handle them.
There are three main places where failures occur: in the ZooKeeper service itself, the network, and an application process. Recovery depends on finding which one of these is the locus of the failure, but unfortunately, doing so isn’t always easy.
Imagine the simple configuration shown in Figure 5-1. Just two processes make up the application, and three servers make up the ZooKeeper service. The processes will connect to one of the servers at random and so may end up connecting to different servers. The servers use internal protocols to keep the state in sync across clients and present a consistent view to clients.
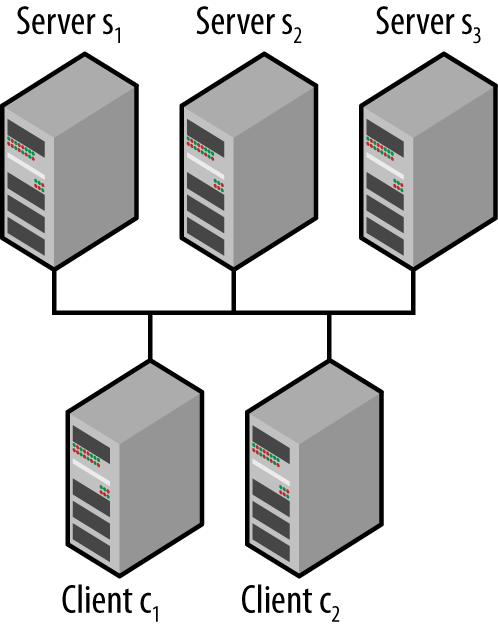
Figure 5-1. Simple distributed application diagram
Figure 5-2 shows some of the failures that can happen in the various components of the system. It’s interesting to examine how an application can distinguish between the different types of failures. For example, if the network is down, how can c1 determine the difference between a network failure and a ZooKeeper service outage? If ZooKeeper s1 is the only server that is down, the other ZooKeeper servers will be online, so if there is ...
Get ZooKeeper now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

