Hand Labeling Considered Harmful
Labeling training data is the one step in the data pipeline that has resisted automation. It’s time to change that.
 Image from "Nostrums and quackery," from "The Journal of the American Medical Association," 1914 (source: Internet Archive on Flickr)
Image from "Nostrums and quackery," from "The Journal of the American Medical Association," 1914 (source: Internet Archive on Flickr)
We are traveling through the era of Software 2.0, in which the key components of modern software are increasingly determined by the parameters of machine learning models, rather than hard-coded in the language of for loops and if-else statements. There are serious challenges with such software and models, including the data they’re trained on, how they’re developed, how they’re deployed, and their impact on stakeholders. These challenges commonly result in both algorithmic bias and lack of model interpretability and explainability.
There’s another critical issue, which is in some ways upstream to the challenges of bias and explainability: while we seem to be living in the future with the creation of machine learning and deep learning models, we are still living in the Dark Ages with respect to the curation and labeling of our training data: the vast majority of labeling is still done by hand.

Learn faster. Dig deeper. See farther.
There are significant issues with hand labeling data:
- It introduces bias, and hand labels are neither interpretable nor explainable.
- There are prohibitive costs to hand labeling datasets (both financial costs and the time of subject matter experts).
- There is no such thing as gold labels: even the most well-known hand labeled datasets have label error rates of at least 5% (ImageNet has a label error rate of 5.8%!).
We are living through an era in which we get to decide how human and machine intelligence interact to build intelligent software to tackle many of the world’s toughest challenges. Labeling data is a fundamental part of human-mediated machine intelligence, and hand labeling is not only the most naive approach but also one of the most expensive (in many senses) and most dangerous ways of bringing humans in the loop. Moreover, it’s just not necessary as many alternatives are seeing increasing adoption. These include:
- Semi-supervised learning
- Weak supervision
- Transfer learning
- Active learning
- Synthetic data generation
These techniques are part of a broader movement known as Machine Teaching, a core tenet of which is getting both humans and machines each doing what they do best. We need to use expertise efficiently: the financial cost and time taken for experts to hand-label every data point can break projects, such as diagnostic imaging involving life-threatening conditions and security and defense-related satellite imagery analysis. Hand labeling in the age of these other technologies is akin to scribes hand-copying books post-Gutenberg.
There is also a burgeoning landscape of companies building products around these technologies, such as Watchful (weak supervision and active learning; disclaimer: one of the authors is CEO of Watchful), Snorkel (weak supervision), Prodigy (active learning), Parallel Domain (synthetic data), and AI Reverie (synthetic data).
Hand Labels and Algorithmic Bias
As Deb Raji, a Fellow at the Mozilla Foundation, has pointed out, algorithmic bias “can start anywhere in the system—pre-processing, post-processing, with task design, with modeling choices, etc.,” and the labeling of data is a crucial point at which bias can creep in.
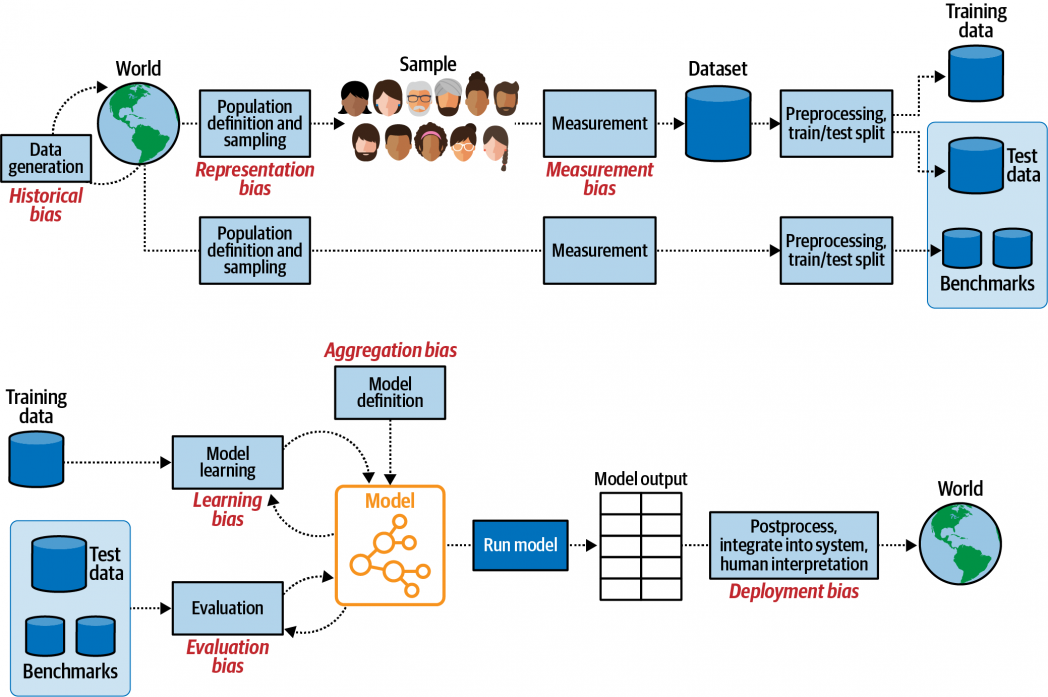
Figure 1: Bias can start anywhere in the system. Image adapted from A Framework for Understanding Sources of Harm throughout the Machine Learning Life Cycle by Harini Suresh and John Guttag.
High-profile cases of bias in training data resulting in harmful models include an Amazon recruiting tool that “penalized resumes that included the word ‘women’s,’ as in ‘women’s chess club captain.’” Don’t take our word for it. Play the educational game Survival of the Best Fit where you’re a CEO who uses a machine learning model to scale their hiring decisions and see how the model replicates the bias inherent in the training data. This point is key: as humans, we possess all types of biases, some harmful, others not so. When we feed hand labeled data to a machine learning model, it will detect those patterns and replicate them at scale. This is why David Donoho astutely observed that perhaps we should call ML models recycled intelligence rather than artificial intelligence. Of course, given the amount of bias in hand labeled data, it may be more apt to refer to it as recycled stupidity (hat tip to artificial stupidity).
The only way to interrogate the reasons for underlying bias arising from hand labels is to ask the labelers themselves their rationales for the labels in question, which is impractical, if not impossible, in the majority of cases: there are rarely records of who did the labeling, it is often outsourced via at-scale global APIs, such as Amazon’s Mechanical Turk and, when labels are created in-house, previous labelers are often no longer part of the organization.
Uninterpretable, Unexplainable
This leads to another key point: the lack of both interpretability and explainability in models built on hand labeled data. These are related concepts, and broadly speaking, interpretability is about correlation, whereas explainability is about causation. The former involves thinking about which features are correlated with the output variable, while the latter is concerned with why certain features lead to particular labels and predictions. We want models that give us results we can explain and some notion of how or why they work. For example, in the ProPublica exposé of COMPAS recidivism risk model, which made more false predictions that Black people would re-offend than it did for white people, it is essential to understand why the model is making the predictions it does. Lack of explainability and transparency were key ingredients of all the deployed-at-scale algorithms identified by Cathy O’Neil in Weapons of Math Destruction.
It may be counterintuitive that getting machines more in-the-loop for labeling can result in more explainable models but consider several examples:
- There is a growing area of weak supervision, in which SMEs specify heuristics that the system then uses to make inferences about unlabeled data, the system calculates some potential labels, and then the SME evaluates the labels to determine where more heuristics might need to be added or tweaked. For example, when building a model of whether surgery was necessary based on medical transcripts, the SME may provide the following heuristic: if the transcription contains the term “anaesthesia” (or a regular expression similar to it), then surgery likely occurred (check out Russell Jurney’s “Hand labeling is the past” article for more on this).
- In diagnostic imaging, we need to start cracking open the neural nets (such as CNNs and transformers)! SMEs could once again use heuristics to specify that tumors smaller than a certain size and/or of a particular shape are benign or malignant and, through such heuristics, we could drill down into different layers of the neural network to see what representations are learned where.
- When your knowledge (via labels) is encoded in heuristics and functions, as above, this also has profound implications for models in production. When data drift inevitably occurs, you can return to the heuristics encoded in functions and edit them, instead of continually incurring the costs of hand labeling.
On Auditing
Amidst the increasing concern about model transparency, we are seeing calls for algorithmic auditing. Audits will play a key role in determining how algorithms are regulated and which ones are safe for deployment. One of the barriers to auditing is that high-performing models, such as deep learning models, are notoriously difficult to explain and reason about. There are several ways to probe this at the model level (such as SHAP and LIME), but that only tells part of the story. As we have seen, a major cause of algorithmic bias is that the data used to train it is biased or insufficient in some way.
There currently aren’t many ways to probe for bias or insufficiency at the data level. For example, the only way to explain hand labels in training data is to talk to the people who labeled it. Active learning, on the other hand, allows for the principled creation of smaller datasets which have been intelligently sampled to maximize utility for a model, which in turn reduces the overall auditable surface area. An example of active learning would be the following: instead of hand labeling every data point, the SME can label a representative subset of the data, which the system uses to make inferences about the unlabeled data. Then the system will ask the SME to label some of the unlabeled data, cross-check its own inferences and refine them based on the SME’s labels. This is an iterative process that terminates once the system reaches a target accuracy. Less data means less headache with respect to auditability.
Weak supervision more directly encodes expertise (and hence bias) as heuristics and functions, making it easier to evaluate where labeling went awry. For more opaque methods, such as synthetic data generation, it might be a bit difficult to interpret why a particular label was applied, which may actually complicate an audit. The methods we choose at this stage of the pipeline are important if we want to make sure the system as a whole is explainable.
The Prohibitive Costs of Hand Labeling
There are significant and differing forms of costs associated with hand labeling. Giant industries have been erected to deal with the demand for data-labeling services. Look no further than Amazon Mechanical Turk and all other cloud providers today. It is telling that data labeling is becoming increasingly outsourced globally, as detailed by Mary Gray in Ghost Work, and there are increasingly serious concerns about the labor conditions under which hand labelers work around the globe.
The sheer amount of capital involved was evidenced by Scale AI raising $100 million in 2019 to bring their valuation to over $1 billion at a time when their business model solely revolved around using contractors to hand label data (it is telling that they’re now doing more than solely hand labels).
Money isn’t the only cost, and quite often, isn’t where the bottleneck or rate-limiting step occurs. Rather, it is the bandwidth and time of experts that is the scarcest resource. As a scarce resource, this is often expensive but, much of the time it isn’t even available (on top of this, the time it also takes to correct errors in labeling by data scientists is very expensive). Take financial services, for example, and the question of whether or not you should invest in a company based on information about the company scraped from various sources. In such a firm, there will only be a small handful of people who can make such a call, so labeling each data point would be incredibly expensive, and that’s if the SME even has the time.
This is not vertical-specific. The same challenge occurs in labeling legal texts for classification: is this clause talking about indemnification or not? And in medical diagnosis: is this tumor benign or malignant? As dependence on expertise increases, so does the likelihood that limited access to SMEs becomes a bottleneck.
The third cost is a cost to accuracy, reality, and ground truth: the fact that hand labels are often so wrong. The authors of a recent study from MIT identified “label errors in the test sets of 10 of the most commonly-used computer vision, natural language, and audio datasets.” They estimated an average error rate of 3.4% across the datasets and show that ML model performance increases significantly once labels are corrected, in some instances. Also, consider that in many cases ground truth isn’t easy to find, if it exists at all. Weak supervision makes room for these cases (which are the majority) by assigning probabilistic labels without relying on ground truth annotations. It’s time to think statistically and probabilistically about our labels. There is good work happening here, such as Aka et al.’s (Google) recent paper Measuring Model Biases in the Absence of Ground Truth.
The costs identified above are not one-off. When you train a model, you have to assume you’re going to train it again if it lives in production. Depending on the use case, that could be frequent. If you’re labeling by hand, it’s not just a large upfront cost to build a model. It is a set of ongoing costs each and every time.

Figure 2: There are no “gold labels”: even the most well-known hand labeled datasets have label error rates of at least 5% (ImageNet has a label error rate of 5.8%!).
The Efficacy of Automation Techniques
In terms of performance, even if getting machines to label much of your data results in slightly noisier labels, your models are often better off with 10 times as many slightly noisier labels. To dive a bit deeper into this, there are gains to be made by increasing training set size even if it means reducing overall label accuracy, but if you’re training classical ML models, only up to a point (past this point the model starts to see a dip in predictive accuracy). “Scaling to Very Very Large Corpora for Natural Language Disambiguation (Banko & Brill, 2001)” demonstrates this in a traditional ML setting by exploring the relationship between hand labeled data, automatically labeled data, and subsequent model performance. A more recent paper, “Deep Learning Scaling Is Predictable, Empirically (2017)”, explores the quantity/quality relationship relative to modern state of the art model architectures, illustrating the fact that SOTA architectures are data hungry, and accuracy improves as a power law as training sets grow:
We empirically validate that DL model accuracy improves as a power-law as we grow training sets for state-of-the-art (SOTA) model architectures in four machine learning domains: machine translation, language modeling, image processing, and speech recognition. These power-law learning curves exist across all tested domains, model architectures, optimizers, and loss functions.
The key question isn’t “should I hand label my training data or should I label it programmatically?” It should instead be “which parts of my data should I hand label and which parts should I label programmatically?” According to these papers, by introducing expensive hand labels sparingly into largely programmatically generated datasets, you can maximize the effort/model accuracy tradeoff on SOTA architectures that wouldn’t be possible if you had hand labeled alone.
The stacked costs of hand labeling wouldn’t be so challenging were they necessary, but the fact of the matter is that there are so many other interesting ways to get human knowledge into models. There’s still an open question around where and how we want humans in the loop and what’s the right design for these systems. Areas such as weak supervision, self-supervised learning, synthetic data generation, and active learning, for example, along with the products that implement them, provide promising avenues for avoiding the pitfalls of hand labeling. Humans belong in the loop at the labeling stage, but so do machines. In short, it’s time to move beyond hand labels.
Many thanks to Daeil Kim for feedback on a draft of this essay.