

As we put the finishing touches on what promises to be another outstanding Hardcore Data Science Day at Strata + Hadoop World in New York, I sat down with my co-organizer Ben Recht for the the latest episode of the O’Reilly Data Show Podcast. Recht is a UC Berkeley faculty member and member of AMPLab, and his research spans many areas of interest to data scientists including optimization, compressed sensing, statistics, and machine learning.
At the 2014 Strata + Hadoop World in NYC, Recht gave an overview of a nascent AMPLab research initiative into machine learning pipelines. The research team behind the project recently released an alpha version of a new software framework called KeystoneML, which gives developers a chance to test out some of the ideas that Recht outlined in his talk last year. We devoted a portion of this Data Show episode to machine learning pipelines in general, and a discussion of KeystoneML in particular.
Since its release in May, I’ve had a chance to play around with KeystoneML and while it’s quite new, there are several things I already like about it:
KeystoneML opens up new data types
Most data scientists don’t normally play around with images or audio files. KeystoneML ships with easy to use sample pipelines for computer vision and speech. As more data loaders get created, KeystoneML will enable data scientists to leverage many more new data types and tackle new problems.
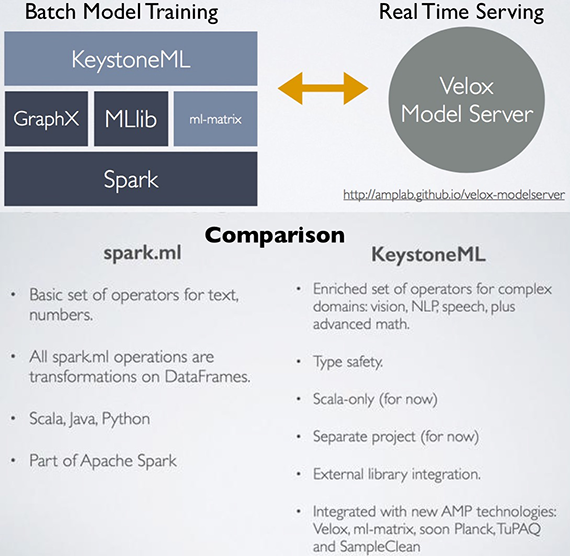
It’s built on top of Apache Spark: Community, scale, speed, results
Spark is the hot new processing framework that many data scientists and data engineers are already using (and judging from recent announcements, more enterprises will start paying attention to it as well). By targeting Spark developers, the creators of KeystoneML can tap into a rapidly growing pool of contributors.
As a distributed computing framework, Spark’s ability to comfortably scale out to large clusters can significantly speed up computations. Early experiments using KeystoneML tackle some computer vision and speech recognition tasks on modestly-sized Spark clusters — resulting in training times that are much faster than other approaches used.
And, while the project is still in its early stages, early pipelines that ship with KeystoneML actually match some state-of-the-art results in speech recognition.
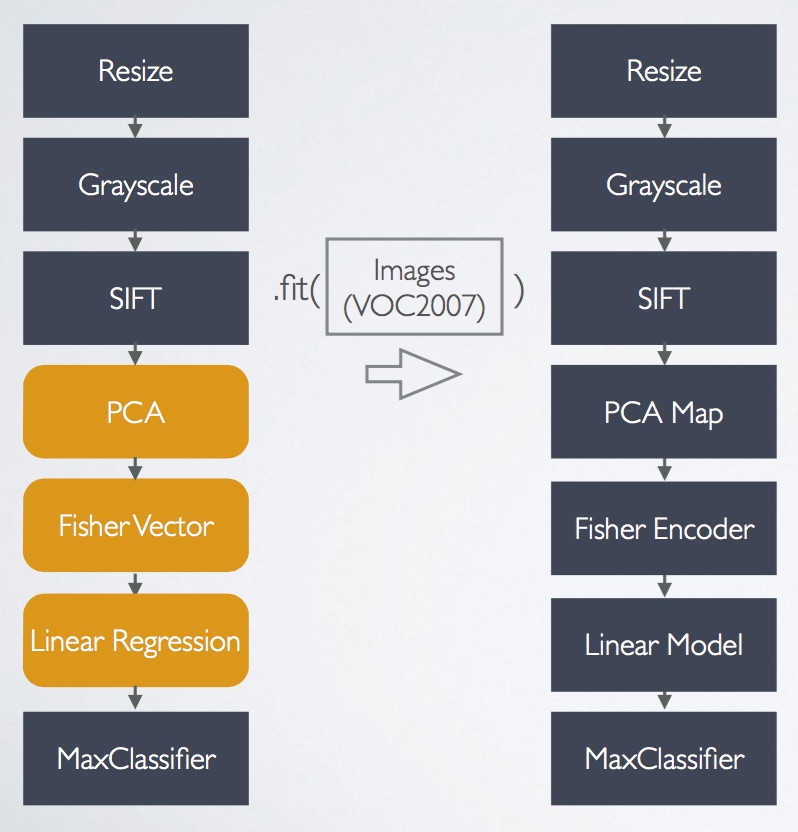
Emphasis on understanding and reproducing end-to-end machine learning pipelines
Rather than the simplistic approach frequently used to teach machine learning (input data -> train model -> use model), KeystoneML’s API reinforces the importance of thinking in terms of end-to-end pipelines. As I and many others have pointed out, model building is actually just one component in data science workflows.
There are many ways to contribute to KeystoneML
As a fairly new project, KeystoneML’s codebase is still relatively small and accessible to potential contributors. A typical pipeline includes data loaders, featurizers, models, and many other components. You need not be an algorithm whiz or a machine learning enthusiast to contribute. In fact, I think many important future contributions to KeystoneML will likely be pipeline components that aren’t advanced modeling primitives. Moreover, if you have access to, or have already created well-tuned components, the creators of KeystoneML provide examples of how to quickly integrate external libraries (including tools written in C) into your pipelines.
A platform for large-scale experiments: Benchmarking and reproducibility
As I noted in an earlier post, the project’s longer term goal is to produce error bounds for end-to-end pipelines. Another important objective is to build a framework and accompanying components that make it easy for data scientists to run experiments and make comparisons. Recht explained:
There are benchmarks, and you get thousands of papers written about the same benchmark and it’s completely impossible to know how people are comparing. They’d say, “Algorithm A is better than algorithm B.” You don’t actually get to see how exactly they’re running algorithm A, or what they did to the default parameters in algorithm B. It’s very hard to actually to make comparisons to make them reproducible. Then [someone will] come along after a bunch of these [and] try to reproduce all of the results and [write a] survey paper comparing a bunch of results. … What we’d like to be able to do is have this framework where you can actually do those kinds of comparisons.
(Automatic) Tuning
Data scientists and data engineers who work with big data tools often struggle to configure and tune complex distributed systems. The designers of KeystoneML are building automation and optimization tools to address these issues. Recht noted:
The other thing that we’re hoping to be able to do are systems optimizations: meaning that we don’t want you to load a thousand-node cluster because you made an incorrect decision in caching. We’d like to be able to actually make these things where we can smartly allocate memory and other resources to be able to run to more compact clusters.
You can listen to our entire interview in the SoundCloud player above, or subscribe through Stitcher, SoundCloud, TuneIn, or iTunes.
Cropped public domain image on article and category pages via Wikipedia.
{kind=link}
Ben Recht will give an update on the state of KeystoneML at Strata + Hadoop World NYC this September. Meet Recht and many other outstanding speakers at Hardcore Data Science day.