 Containers (source: Pxhere.com)
Containers (source: Pxhere.com) Kubernetes is really cool because managing services as flocks of little containers is a really cool way to make computing happen. We can get away from the idea that the computer will run the program and get into the idea that a service happens because a lot of little computing just happens. This idea is crucial to making reliable services that don’t require a ton of heroism to stand up or keep running.
But there is a dark side here. Containers want to be agile because that is the point of containers in the first place. We want containers because we want to make computing more like a gas made up of indistinguishable atoms instead of like a few billiard balls with colors and numbers on their sides. Stopping or restarting containers should be cheap so we can push flocks of containers around easily and upgrade processes incrementally. If ever a container becomes heavy enough that we start thinking about that specific container, the whole metaphor kind of dissolves.
So that metaphor depends on containers being lightweight. Or, at least, they have to be lightweight compared to the job they are doing. That doesn’t work out well if you have a lot of state in a few containers. The problem is that data lasts a long time and takes a long time to move. The life cycle of data is very different than the life cycle of applications. Upgrading an application is a common occurrence, but data has to live across multiple such upgrades.
Previous solutions
This all has typically meant that we had two possible options. One was to build a lot of state-handling services that each consisted of a few containers, each housing a fair bit of data. That doesn’t turn out well because these state-handling services cause problems. They don’t move easily, but because each service contains just a few containers, statistical variations in load create havoc for neighboring containers creating a need to move them. Because of poor multitenancy, managing state in containers often leads to yet another bespoke state management service for every few operational services. This is a problem because the load imposed by the services attached to each one of these stateful services is small, but the minimum number of containers required to safely manage state is typically five or more. I have heard stories of running 5,000 Kafka brokers distributed across hundreds of clusters, or hundreds of database services, or dozens of HDFS clusters. The twin problems here are that the cost of managing this cluster sprawl scales very poorly and the utilization of these machines is very poor since the load in each of these cases could typically be supported by a few dozen nodes.
The other major option has been to keep the state out of containers and put it onto a service entirely outside of Kubernetes. That can lead to grief in a few ways. First off, if your data is on a specialized storage appliance of some kind that lives in your data center, you have a boat anchor that is going to make it hard to move into the cloud. Even worse, none of the major cloud services will give you the same sort of storage, so your code isn’t portable any more. Each cloud provider has their own idiosyncratic version of storage, typically in the form of something designed to store large immutable blobs, which is only good for a few kinds of archival use. If you want anything else, you will find yourself locked into an array of the cloud provider’s specialized services.
These difficulties people are facing with containers and state have actually been very good for us at my day job because we build a system that provides a software-defined storage layer that can make a pretty good cloud-neutral distributed data platform. That’s great to have because you can use that storage platform to build a data fabric that extends from your on-premises systems into multiple cloud systems to get access to data at a performance level and with an API that you want. This data fabric can share the storage loads of a large number of applications and thus raise utilization dramatically. One particular win with this kind of design is that by putting all or most of your state in a single platform, you get a statistical leveling out of the loads imposed by the storage system, which makes managing the overall system much, much easier.
But that isn’t what we would like in the long run, either. Having stuff managed by Kubernetes and stuff that is outside Kubernetes is philosophically and practically unpleasant. It would be just so much better if we could run an advanced storage platform inside Kubernetes so that everything we do could be managed uniformly. What we need is something that would scale to handle the state required by most or all of the services we are running in all the different forms that we need, but still run in containers managed by Kubernetes. By having one service act as a data platform that handles all or most of the data for the rest of the service, we still face the problem that the containers that make up this service will have mass due to the data they are managing. If this service handles storage for many services, though, we can put the law of large numbers to work to our advantage and thus improve the manageability.
Recent advances in Kubernetes
This vision of having a high-performance storage platform that runs inside Kubernetes is becoming a very real possibility due to recent advances in how Kubernetes works. The basic idea of attaching containers to storage volumes has been around since Kubernetes 1.2, but until recently, this was mostly useful to attach to external storage systems. More recently, however, it has become much more feasible to run high-performance data platforms directly inside Kubernetes itself.
There are a few key problems to be solved to do this. These include:
- It is common that there needs to be some machine-level (as opposed to pod-level) bits that run exactly once per host OS instance. This is particularly true for code that accesses physical resources such as the low-level code that implements the data platform itself, but you probably will need something like this for once-per-host client-side driver mechanisms as well. Daemonsets solve both of these problems by allowing you to define pods of containers that are guaranteed to run on every node. As you add nodes to your Kubernetes cluster, all applicable daemonsets will be started on these new nodes if they meet the specifications you set. Thus, if you add a node with storage resources, the low-level device interface code will run and will handle talking to the disks. As you add nodes that will have storage clients (potentially every node in the cluster), shared client side code will run.
- You need to be able to use unmodified Docker containers, even though there may be some driver code required. For instance, you might want to run an official PostgreSQL database image completely unchanged. Sidecar containers are ideal for this along with the Flexvolume plugin. Until Kubernetes 1.8, it was typical to put vendor-specific drivers directly into the Kubenetes source code. Since then, the standard practice is to use the container storage interface (CSI) or Flexvolume plugins to deliver these drivers. The basic idea is that your pod will contain an extra container that talks to the client-side daemonset and causes the appropriate data to be mounted and exposed to the application containers in your pod.
This basic idea of pods running on two different nodes is illustrated in Figure 1. The low-level storage code is running on both nodes, while the shared client code is only running on a single node where an application is also running.
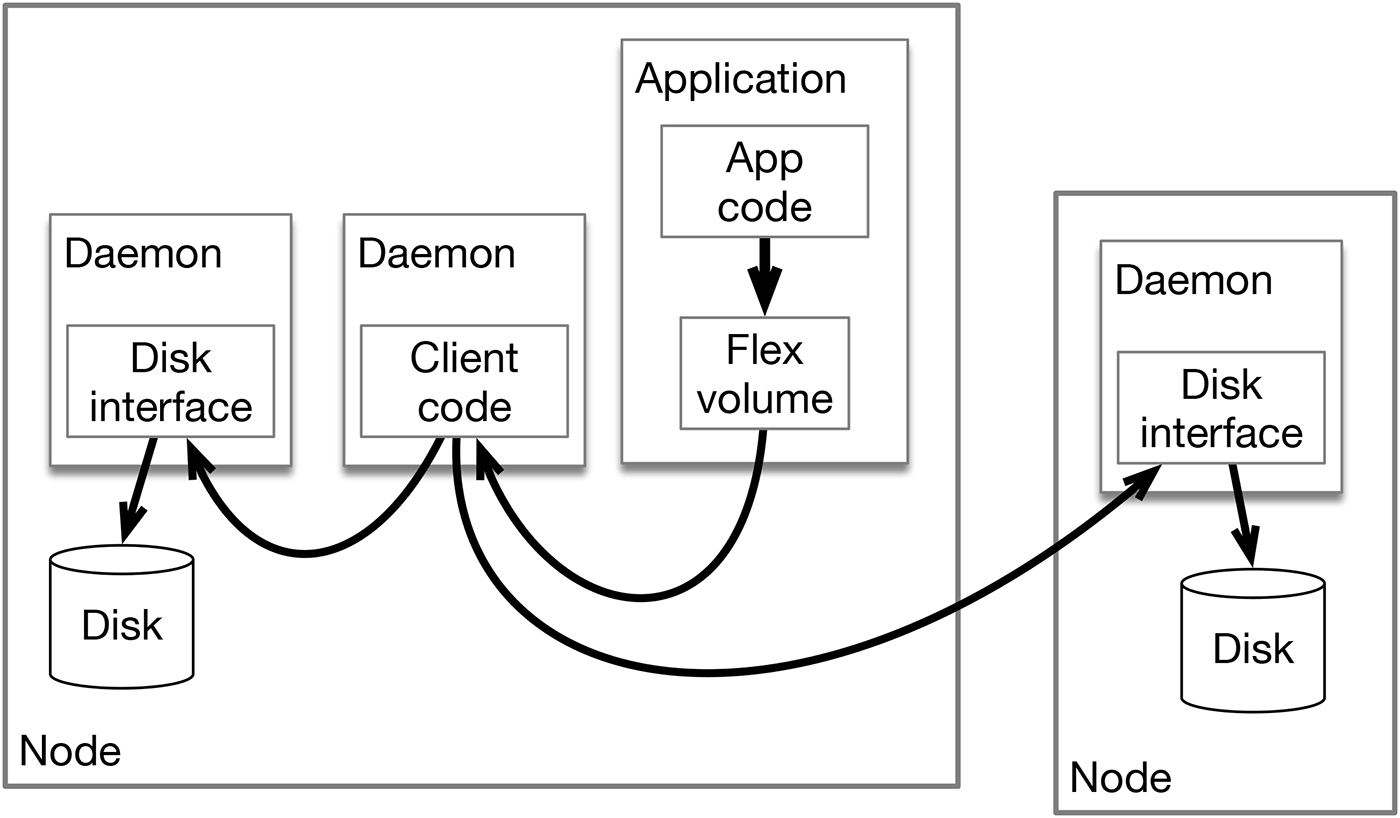
The exciting thing about this architecture is that it permits independent evolution on several levels. The storage code can evolve independently of Kubernetes, the application container can access the data platform with no changes whatsoever, and any or all pieces of the system can be upgraded on the fly in a running production cluster.
One subtle point is that having a shared client-side daemon allows for more efficient access to network and storage services without necessarily imposing an extra copy of the data between the application and the disk or network.
The implications for big data
Ultimately, what matters is what can you do with a system like this, and that is where these new capabilities really shine. The goal is to build a system that is conceptually like what we see in Figure 2. Here, Kubernetes is in charge of managing and deploying applications, and these applications persist data to a data platform. To simplify the system, we want Kubernetes to manage the execution of the data platform itself, and we want the data platform to manage the complete life cycle of the application data. In fact, you could say that we want the data platform to be “like Kubernetes, but for data.”
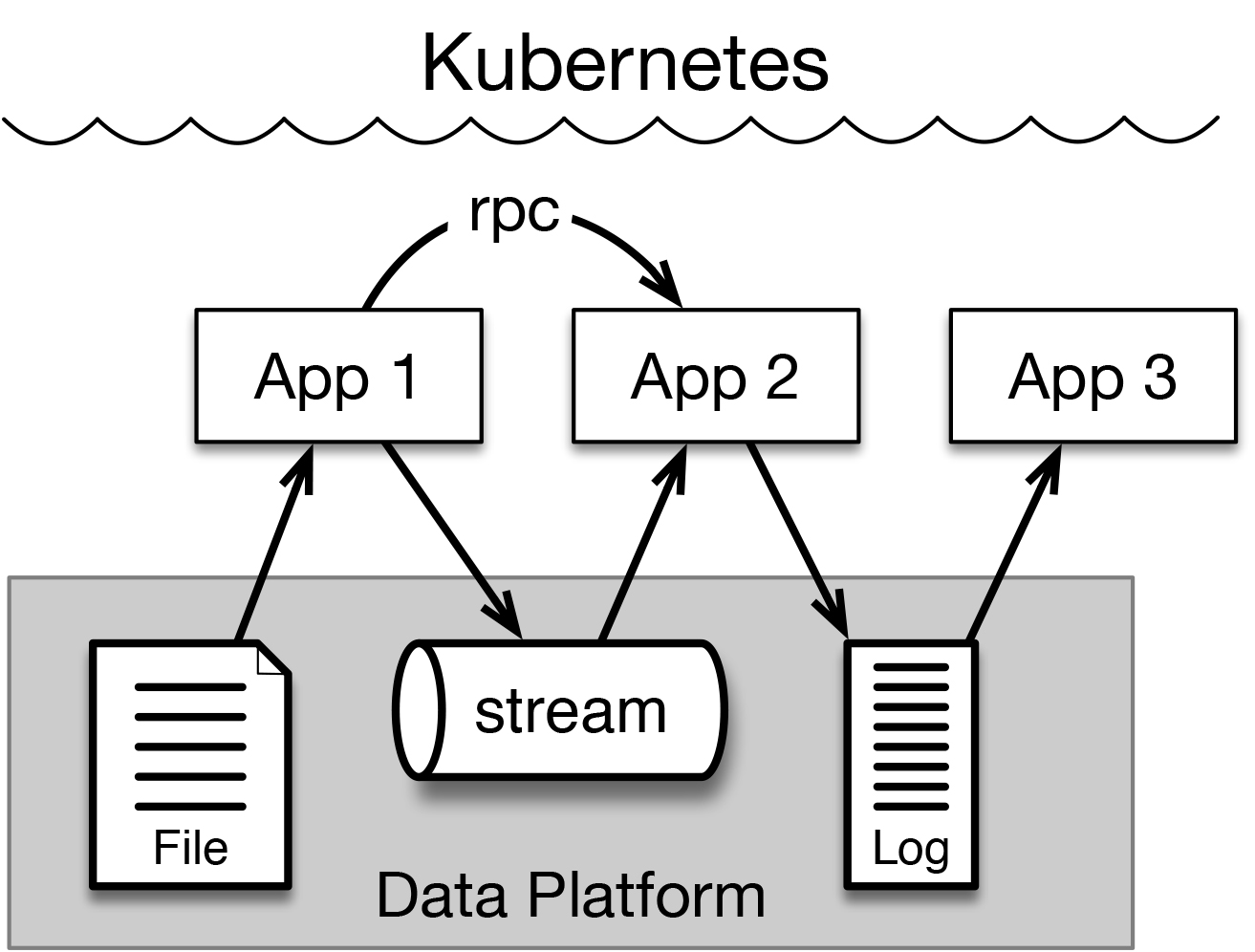
The ability to host a data platform in this way has been part of Kubernetes’ vision from nearly the beginning, but it is only now becoming possible to build out a system like this with all of the performance, security, and features needed to fully support a multitenant data platform.
Big data systems have always stressed storage systems. The original rationale for HDFS and higher performance follow-ons like MapR FS has always been that big data applications needed much more performance than dedicated storage appliances could deliver. This is more true than ever as modern hardware makes it possible to support enormous throughput. As it becomes possible to support this kind of performance entirely within Kubernetes, we are going to see enormous benefits, such as the ability to simultaneously run multiple versions of big data tool sets like Spark that interface transparently to machine learning systems like TensorFlow or H2O.
Future outlook
As exciting as these recent developments are, more is on the way. Most of the work so far in Kubernetes involves the use of file system APIs. Files are not the only way we want to persist data. For some applications, tables are much better; between services, message streams are often the right thing to use. Modern data platforms can support all of these persistence modes at the same time in a fully integrated way, but the Portable Operating System Interface (POSIX) API isn’t sufficient to access these systems, so systems like Flexvolumes aren’t sufficient. There isn’t, however, any real reason that Flexvolumes can’t provide alternative API access to persistence beyond simple files.
It is reasonable to expect that, before long, we will see ways of supporting more than just files via the same basic mechanisms we have discussed here. But even before that happens, it is already an amazing time to be working on big data under Kubernetes.