
 Time lapse (source: Pexels)
Time lapse (source: Pexels) Today’s enterprise applications are deployed to everything from mobile devices to cloud-based clusters running thousands of multi-core processors. Users have come to expect millisecond response times and close to 100% uptime. And by “user” I mean both humans and machines. Traditional architectures, tools and products simply won’t cut it anymore. To paraphrase Henry Ford’s classic quote: we can’t make the horse any faster, we need cars for where we are going.
In this article, we will look at microservices, not as a tool to scale the organization, development and release process (even though it’s one of the main reasons for adopting microservices), but from an architecture and design perspective, and put it in its true context: distributed systems. In particular, we will discuss how to leverage Events-first Domain Driven Design and Reactive principles to build scalable microservices, working our way through the evolution of a scalable microservices-based system.
Don’t build microliths
Let’s say that an organization wants to move away from the monolith and adopt a microservices-based architecture. Unfortunately, what many companies end up with is an architecture similar to the following:
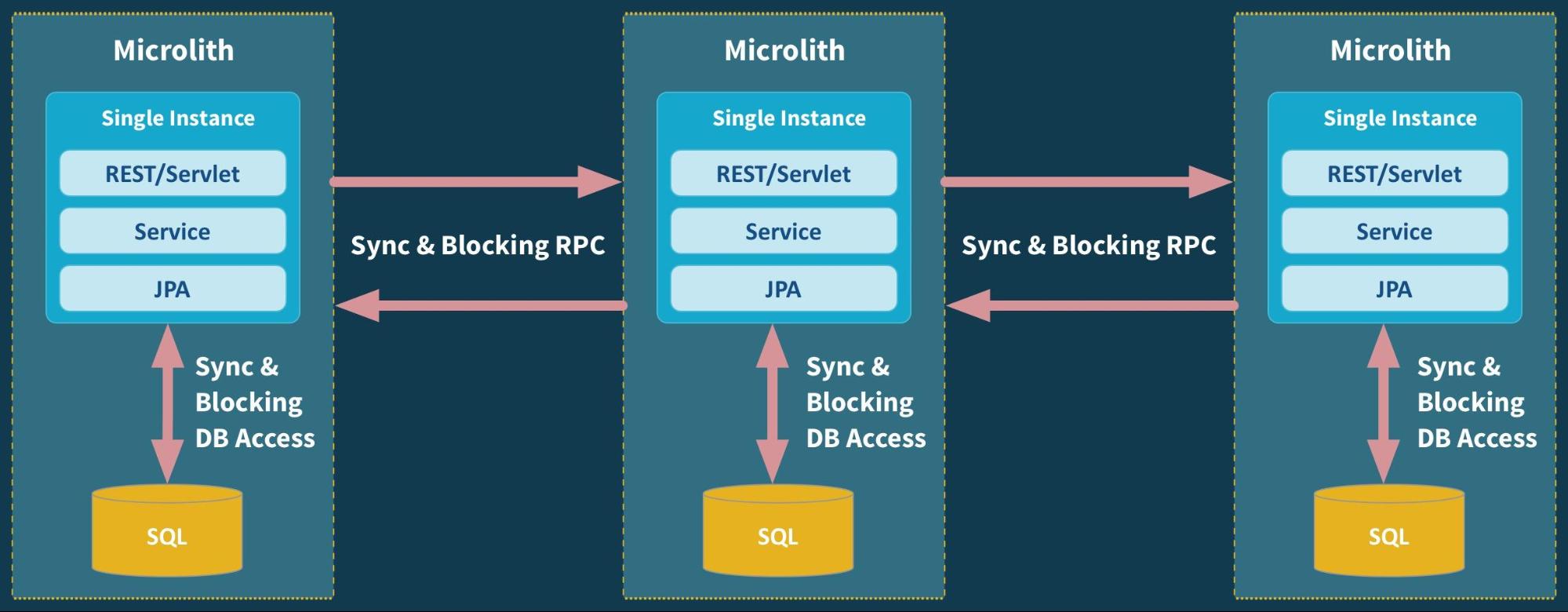
In this figure, we have a bunch of single instance services communicating over synchronous HTTP, running in a Docker container, and using CRUD through JPA talking to a SQL database (in the worst case, still using a single monolithic database, with a single schema for all services). Undeniably, what we have built ourselves here is a set of micro monoliths—or microliths.
A microlith is defined as a single instance service where synchronous method calls have been turned into synchronous RPC calls (often over REST) and blocking database access remains blocking. This architecture is maintaining the strong coupling we wanted to move away from, but with higher latency added by IPC.
The problem with a single instance is that it cannot—by definition—be scalable or available. A single monolithic thing, whatever it might be (a human, or a software process), can’t be scaled out, and can’t stay available if it crashes. Some software architects and developers might think that working with microliths is just fine, since we can just put each one in a container and spin up as many of them as needed. The problem is that it’s not that simple. Microservices are not isolated islands, they come in systems.
It’s important to understand that as soon as we exit the boundary of the single service instance we enter a wild ocean of non-determinism—the world of distributed systems—where systems fail in the most spectacular and intricate ways; where information gets lost, reordered, garbled, and where failure detection is a guessing game. It’s a fact that distributed systems are hard.
But how can we manage distributed systems? Let’s first turn to Events-first Domain Driven Design for help.
Using events-first domain driven design
The term Events-first Domain Driven Design was coined by Russ Miles, and is a name for a set of design principles that has emerged in our industry over the last few years and that has proved to be very useful in building distributed systems at scale.
Focus on what happens
Object-oriented programming and later Domain Driven Design taught us that we should start with focusing on the things—the nouns—in the domain. It turns out that this approach has a major flaw: it forces you to focus on structure too early.
Instead, we should turn our attention to the things that happen—the flow of events—in our domain. This forces us to understand how change propagates in the system, including communication patterns, workflow, and data ownership.
Events as facts
A fact represents something that has happened in the past. Facts are immutable—they can’t be changed or be retracted—as we can’t change the past, even if we sometimes wish that we could.
Knowledge is cumulative—either by receiving new facts, or by deriving new facts from existing facts. Invalidation of existing knowledge is done by adding new facts to the system that refute existing facts. But facts are not deleted, they are only made irrelevant for current knowledge.
Ask yourself: what are the facts? Try to understand which facts are causally related, and which are not. It’s the path towards understanding the domain, and later the system itself.
Events represent facts about the domain and should be part of the Ubiquitous Language of the subdomain, modeled as Domain Events, and help us to define the Bounded Context for the subdomain, forming the boundaries for our service.
Commands represent intent to perform an action. These actions are often side-effecting, meaning that the intent is to cause an effect on the receiving side—cause it to change its internal state, start a new task, or send more commands.
A technique called Event Storming can help. It’s a design process in which you bring all the stakeholders—the domain experts and the programmers—into a single room where they brainstorm using post-it notes, trying to find the domain language for the Events and Commands, to discover how they are causally related and the reactions they cause. The result should be an Event-driven design, and paves the way for getting the most out of Reactive principles.
Moving towards reactive microsystems
Ever since I helped co-author the Reactive Manifesto in 2013, Reactive has gone from being a virtually unknown technique for constructing systems—used by only fringe projects within a select few corporations—to become part of the overall platform strategy in numerous big players in the industry. During this time, Reactive has become an overloaded word, meaning different things to different people. More specifically, there has been some confusion around the difference between reactive programming and reactive systems (a topic covered in depth in this O’Reilly article). Both are equally important to understand how—and when—to implement in a Microservices-based design.
Embrace reactive programming
Reactive programming is a great technique for making individual components performant and efficient through asynchronous and non-blocking execution, most often together with a mechanism for backpressure. It has a component local focus and is event-driven—publishing events/facts to 0-N anonymous subscribers. Popular libraries for reactive programming on the JVM include Akka Streams, Reactor, Vert.x, and RxJava.
Enter reactive microliths
Let’s now go back to our discussion of microliths and apply the techniques of reactive programming. Starting at the edge of the service, we replace the synchronous and blocking database access with asynchronous drivers[1], and the synchronous and blocking communication protocol over HTTP/REST with Messaging or Streaming.
One good alternative in moving to an Event-driven model is to use Pub/Sub messaging—over a message broker such as Apache Kafka or AWS Kinesis. This helps to decouple the services by introducing temporal decoupling—the services communicating do not need to be available at the same time—which increases resilience and opens up for scaling them independently.
Applying these techniques to our system can give us a design like this, a set of reactive microliths:
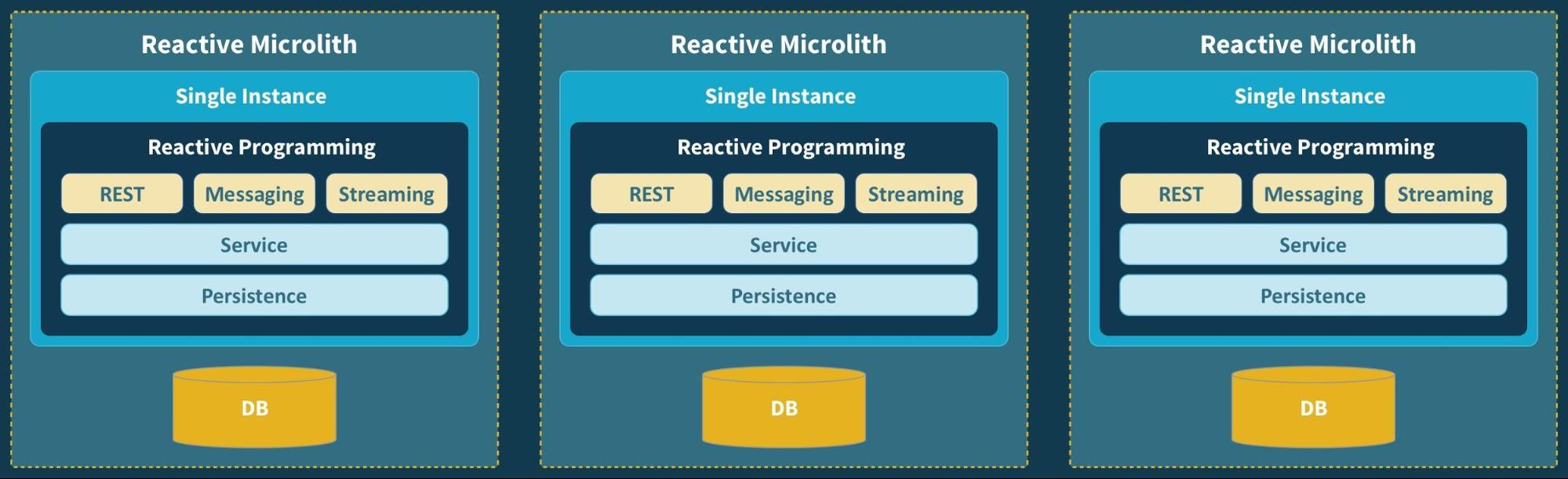
We’re getting there. But we still have a set of single instance microservices—and neither service is resilient or elastic. This is something that we have to address.
We have discussed that microservices come in systems. However, what is less obvious is that microservices also come as systems. Each microservice needs to be designed as a system, a distributed one, which needs to work together as a single whole. Essentially, we need to move from microliths to microsystems.
Embrace reactive systems
Reactive systems—as defined by the Reactive Manifesto—takes a holistic view on system design, focusing on keeping distributed systems responsive by making them resilient and elastic. These systems are message-driven—based upon asynchronous message-passing which makes distributed communication to addressable recipients first class—allowing for location transparency, isolation, decentralization, supervision, and self-healing.
Scaling state and behavior independently
It can often be helpful to separate the stateless[2] behavioral part of the service—the processing, the business logic—from the stateful aggregate part—which will be the durable system of record.
Commands flow, in an asynchronous fashion, from the stateless to the stateful part—preferably modeled as an Aggregate. This allows us to decouple them, run them on different nodes, or run them in-process on the same node if that is preferred. Now we can tune the availability through scaling.
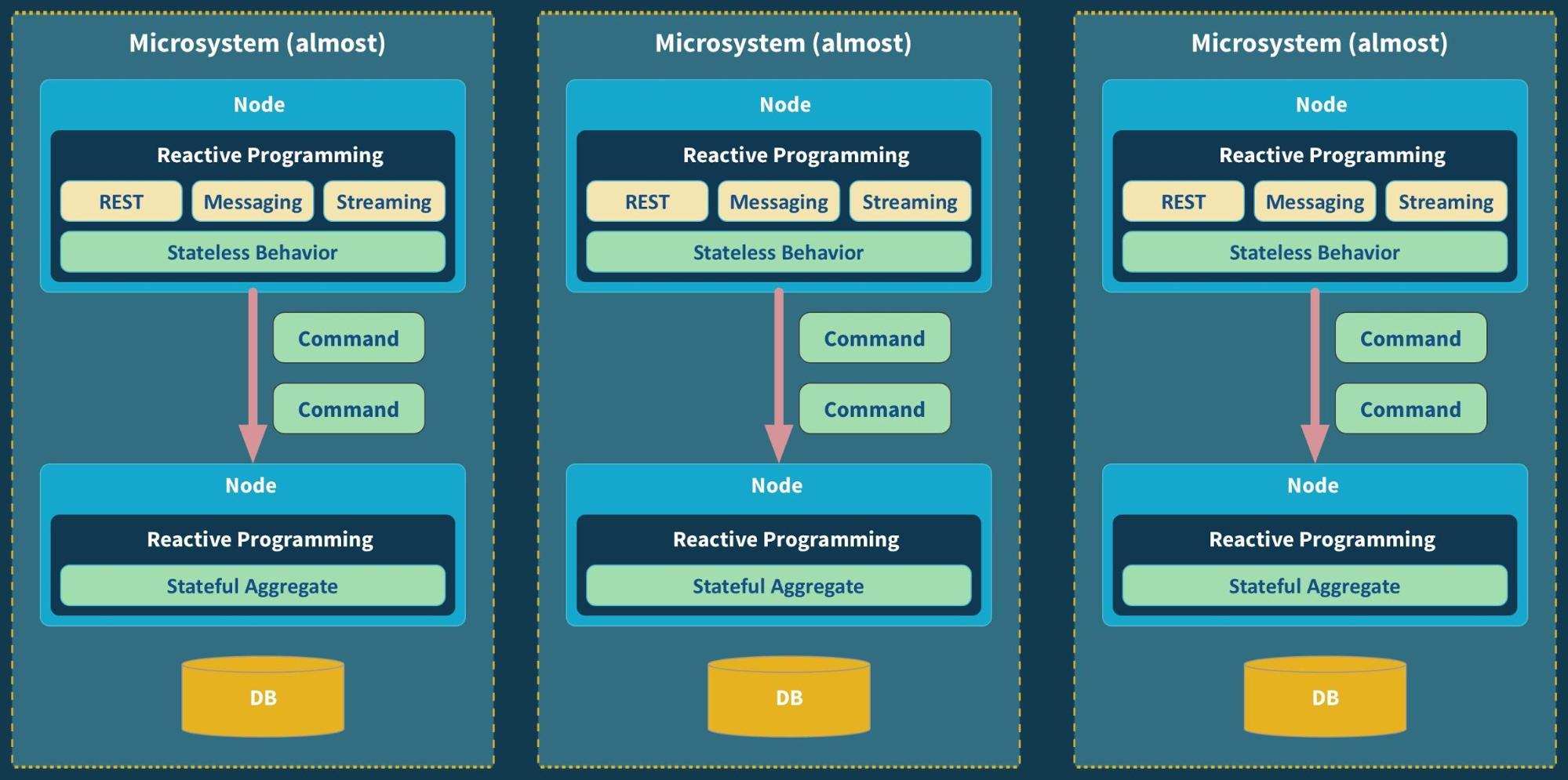
Scaling stateless behavior is trivial. It can be scaled linearly—assuming non-shared infrastructure—in a fully automatic fashion. One example of this is AWS Lambda—spearheading the “serverless” trend.
Scaling state, however, is very hard. For services that do not have the luxury of being “forgetful” and need to read/write state, delegating to a database only moves the problem to the database. We still need to deal with the coordination of reading and writing. Ignoring the problem by calling the architecture “stateless” with “stateless” services pushing their state down into a shared database will only delegate the problem, push it down the stack, and make it harder to control in terms of data integrity, scalability and availability guarantee[3].
Enter microsystems
Now we are in a position to scale out the stateless behavioral part of our microservice to N number of nodes, and set up the stateful entity part in an active-passive replication scheme for seamless failover. The behavioral part can also function as a translation and Anti-Corruption Layer, unless it is put in a unifying API Gateway in front of the microservices.
What we end up with is a system of (potentially) distributed parts that all need to work in concert, as illustrated in the below figure, while being scaled alongside different axises—a microsystem.
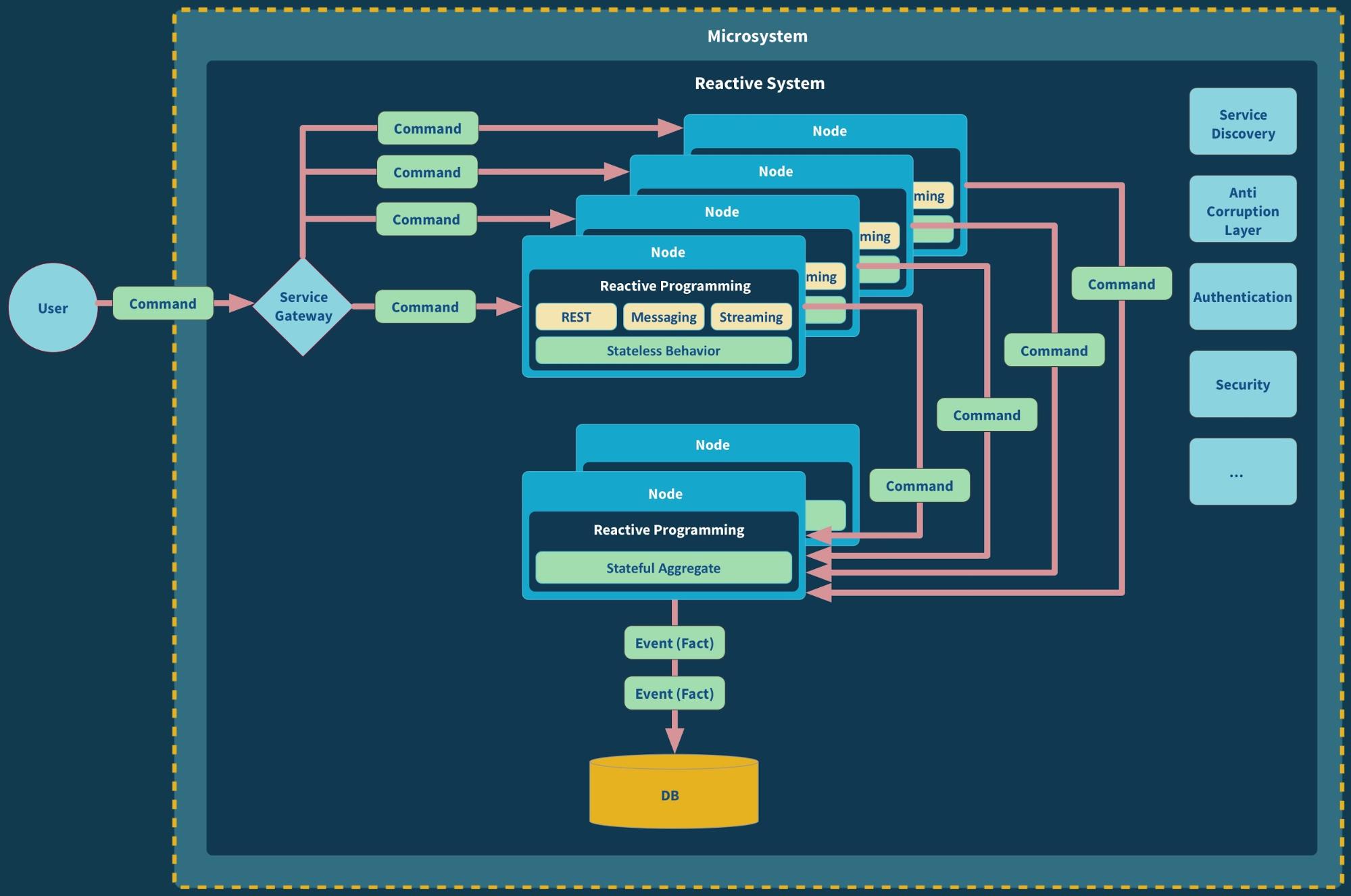
This design does not only give us increased scalability but also resilience, by ensuring that there is always another node that can serve requests and take over processing or state management, in the case of node failure. The “user” in this figure can be anything from a human using a client application, another microservice, or an external system sending commands in the form of HTTP requests, streams, or messages.
Event-based persistence
Disk space used to be very expensive. This is one of the reasons why most SQL databases are using update-in-place—overwriting existing records with new data as it arrives. As Jim Gray once said[4]: “Update-in-place strikes many systems designers as a cardinal sin: it violates traditional accounting practices that have been observed for hundreds of years”. Still, money talked, and CRUD (Create/Read/Update/Delete) was born.
The good news is that today disk space is incredibly cheap so there is little-to-no reason to use update-in-place for system of record. We can afford to store all data (the facts) that has ever been created in the system, giving us the entire history of everything that has ever happened in the system.
We don’t need Update and Delete anymore. We just Create new facts—either by adding more knowledge (facts) or drawing new conclusions (facts) from existing knowledge—and Read facts, from any point in the history of the system. This means that CRUD is no longer necessary. But the question now becomes: how can we move to a more efficient form of persisting data? Let’s turn our attention to Event Logging.
Using event sourcing
One of the most scalable ways to store facts is in an Event Log. It allows us to store them in their natural causal order—the order they were created in. A popular pattern for event logging is Event Sourcing, where we capture the state change—triggered by a command/request—as a new event to be stored in the Event Log. These events represent the fact that something has happened (i.e., OrderCreated, PaymentAuthorized or PaymentDeclined).
One benefit of using Event Sourcing is that it allows the aggregate to cache the data set—the latest snapshot—in memory, instead of having to reconstitute it from durable storage every request (or periodically)—as often seen when using raw SQL, JDBC, Object-Relational Mapping (ORM) or NoSQL databases. This pattern is often referred to as a Memory Image and helps avoid the infamous Object-Relational Impedance Mismatch. It allows us to store the data in-memory inside our services, in any format that we find convenient. The master data resides on disk in an optimal format for append-only event logging, ensuring efficient write patterns—such as the Single Writer Principle—are working in harmony with modern hardware instead of at odds with it.
The events are stored in causal order, providing the full history of all the interactions with the service. Since events most often represent service transactions, the Event Log essentially provides us with a transaction log that is explicitly available to us for querying, auditing, and replaying messages from an arbitrary point in time for resilience, debugging, and replication—instead of having it abstracted away from the user, as seen in RDBMSs.
Each event sourced aggregate usually has an event stream through which it is publishing its events to the rest of the world. The event stream can be subscribed to by many different parties, for different purposes. Some examples include: a database optimized for queries (as in the CQRS pattern discussed below); other microservices reacting to events as a way of coordinating workflow; and supporting infrastructure services like audit or replication.
Untangle your read and write models with CQRS
CQRS is a technique invented by Greg Young as a way of separating the write and read (query) model from each other, opening up for using different techniques to address each side of the equation.
This is accomplished by letting the query-serving database subscribe to the event log’s event stream, in an asynchronous fashion. One benefit of this design is that the event stream is made available for anyone to subscribe to, not just the query database. For example, being subscribed to by more than one query model (as an example using Cassandra for queries, ElasticSearch general search and HDFS for batch-oriented data mining), or by other Microservices as a way of coordinating workflow, often using the Process Manager or Distributed Saga pattern to handle progress[5].
The write and read models exhibit very different characteristics and requirements in terms of data consistency, availability, and scalability. The benefit of CQRS is that it allows both models to be stored in its optimal format.
CQRS is a general design pattern that can be used successfully together with almost any persistence strategy and storage backend. It fits perfectly together with Event Sourcing in the context of event-driven and message-driven architectures, which is the reason why you will often hear them mentioned in tandem. One benefit of decoupling the read side from the write side is that it allows us to scale them independently of each other, which opens up a lot of flexibility, and gives us more headroom and knobs to turn.
In the below illustration we can see how we can let our microsystems make use of CQRS and Event Sourcing for increased scalability and resilience.
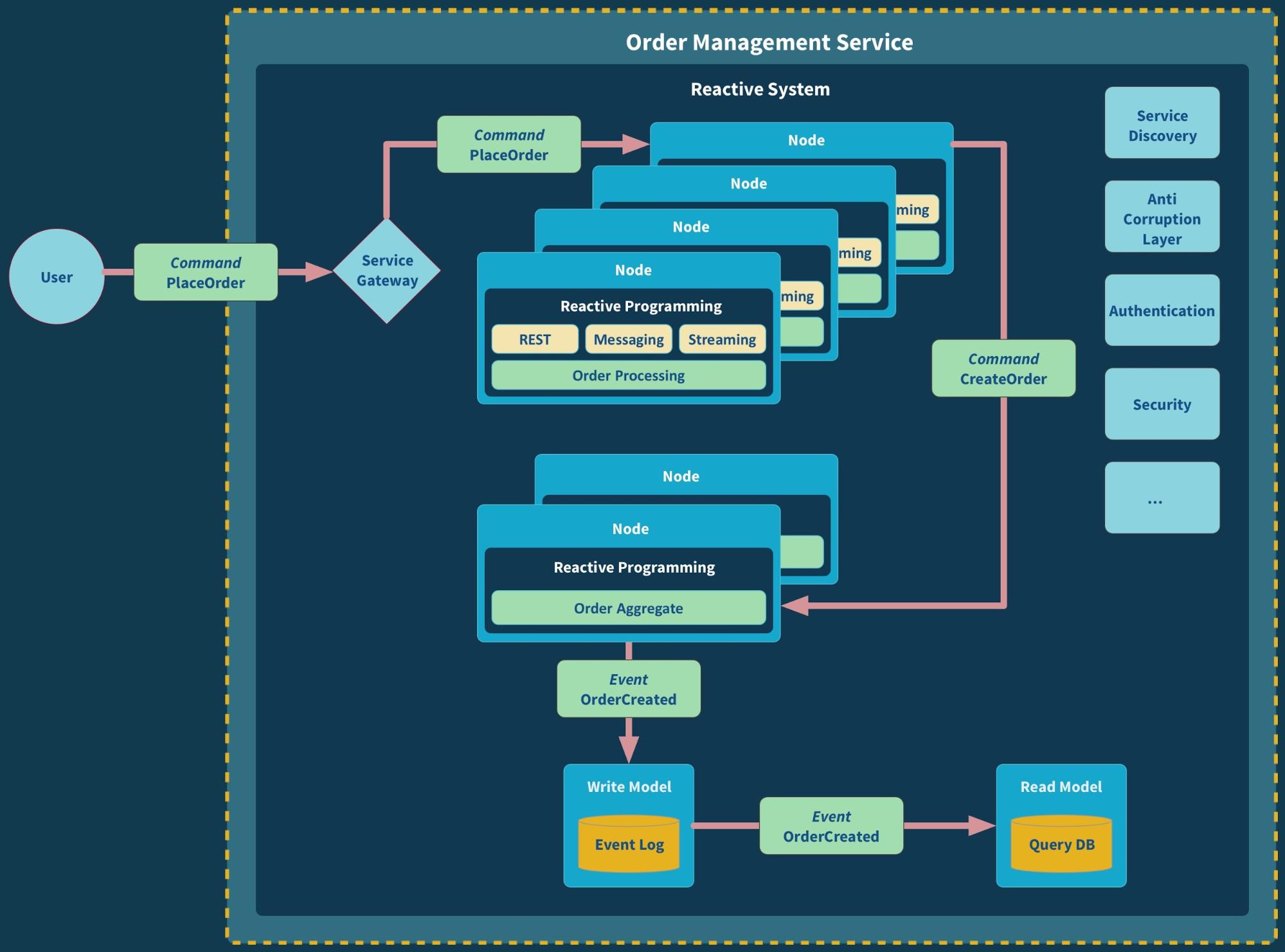
Let’s dive deeper into this order management microsystem to better understand the flow of commands and events:
- A user sends a PlaceOrder command (in the form of an HTTP request) to the order management service.
- The command is received by a load balancer, in this case in the form of a Service Gateway, within the microsystem, who relays it to an available instance of its (stateless) processing behavior.
- The processing instance executes the business logic involved in creating the order. For example, validation of campaign codes and calculation of discounts and shipping costs.
- When it is done it creates and sends off a CreateOrder command to the Aggregate instance, representing the intention to create a new order in the system.
- Upon reception of the CreateOrder command the Aggregate instance:
- Creates a OrderCreated event.
- Writes it to the Event Log, the write model—using Event Sourcing.
- Updates its internal state.
- The OrderCreated event is then propagated, through the event stream, to all listeners that have registered for changes to the Event Log. One of these listeners is the read model, the database dedicated for queries, who upon reception of the event incorporates the new fact into its view(s).
Conclusion
We have covered a lot of ground in this article. We began with a simplistic approach to microservices design, based on single instance non-scalable services—microliths— and gradually moved towards a design based on decoupled, scalable and resilient microsystems, leveraging Reactive principles and event-based communication and persistence.
There is a lot more to say about these topics, but I hope that you by now have some ideas on how to use Reactive and Events-first design to build microservices-based systems that can thrive in the barren lands of distributed systems.
If you want to dive deeper into these topics I suggest that you grab a copy of Roland Kuhn’s excellent Reactive Design Patterns and Vaughn Vernon’s great and practical Implementing Domain Driven Design.
However, if you want to get hands-on and start exploring these ideas through code, then I recommend that you take a look at Lagom. It’s a microservices framework built on top of Akka and the Play Framework, and it embodies the principles and techniques that we have discussed here.
This article was created in collaboration with Lightbend. See our statement of editorial independence.