 Inner circle at Stonehenge. (source: Kristian H. Resset on Wikimedia Commons)
Inner circle at Stonehenge. (source: Kristian H. Resset on Wikimedia Commons) There are four basic ingredients for making AI: data, compute resources (i.e., hardware), algorithms (i.e., software), and the talent to put it all together. In this era of deep learning ascendancy, it has become conventional wisdom that data is the most differentiating and defensible of these resources; companies like Google and Facebook spend billions to develop and provide consumer services, largely in order to amass information about their users and the world they inhabit. While the original strategic motivation behind these services was to monetize that data via ad targeting, both of these companies—and others who are desperate to follow their lead—now view the creation of AI as an equally important justification for their massive collection efforts.
Abundance and scarcity of ingredients
While all four pieces are necessary to build modern AI systems, what we’ll call their “scarcity” varies widely. Scarcity is driven in large part by the balance of supply and demand: either a tight supply of a limited resource or a heavy need for it can render it more scarce. When it comes to the ingredients that go into AI, these supply and demand levels can be influenced by a wide range of forces—not just technical changes, but also social, political, and economic shifts.
Fictional depictions can help to draw out the form and implications of technological change more clearly. So, before turning to our present condition, I want to briefly explore one of my favorite sci-fi treatments of AI, from David Marusek’s tragically under-appreciated novel Counting Heads. Marusek paints a 22nd-century future where an AI’s intelligence, and its value, scales directly with the amount of “neural paste” it runs on—and that stuff isn’t cheap. Given this hardware (wetware?) expense, the most consequential intelligences, known as mentars, are sponsored by—and allied with—only the most powerful entities: government agencies, worker guilds, and corporations owned by the super-rich “affs” who really run the world. In this scenario, access to a powerful mentar is both a signifier and a source of power and influence.
Translating this world into our language of AI ingredients, in Counting Heads it is the hardware substrate that is far and away the scarcest resource. While training a new mentar takes time and skill, both the talent and data needed to do so are relatively easy to come by. And the algorithms are so commonplace as to be beneath mention.
With this fictional example in mind, let’s take stock of the relative abundance and scarcity of these four ingredients in today’s AI landscape:
- The algorithms and even the specific software libraries (e.g., TensorFlow, Torch, Theano) have become, by and large, a matter of public record—they are simply there for the taking on github and the ArXiv.
- Massive compute resources (e.g., Amazon AWS, Google, Microsoft Azure) aren’t without cost, but are nevertheless fully commoditized and easily accessible to any individual or organization with modest capital. A run-of-the-mill AWS instance, running about $1 an hour, would have been at or near the top of the world supercomputer rankings in the early 1990s.
- The talent to build the most advanced systems is much harder to come by, however. There is a genuine shortage of individuals who are able to work fluently with the most effective methods, and even fewer who can advance the state of the art.
- Finally, the massive data sets necessary to train modern AIs are hardest of all to obtain, in some cases requiring a level of capital expenditure and market presence that only the largest organizations can muster. While data is a non-rival good, and therefore could be shared widely after collection, in practice the largest and most valuable data sets are closely guarded – they form the true barriers to competition in today’s landscape.
You could summarize the current situation with the following visual:
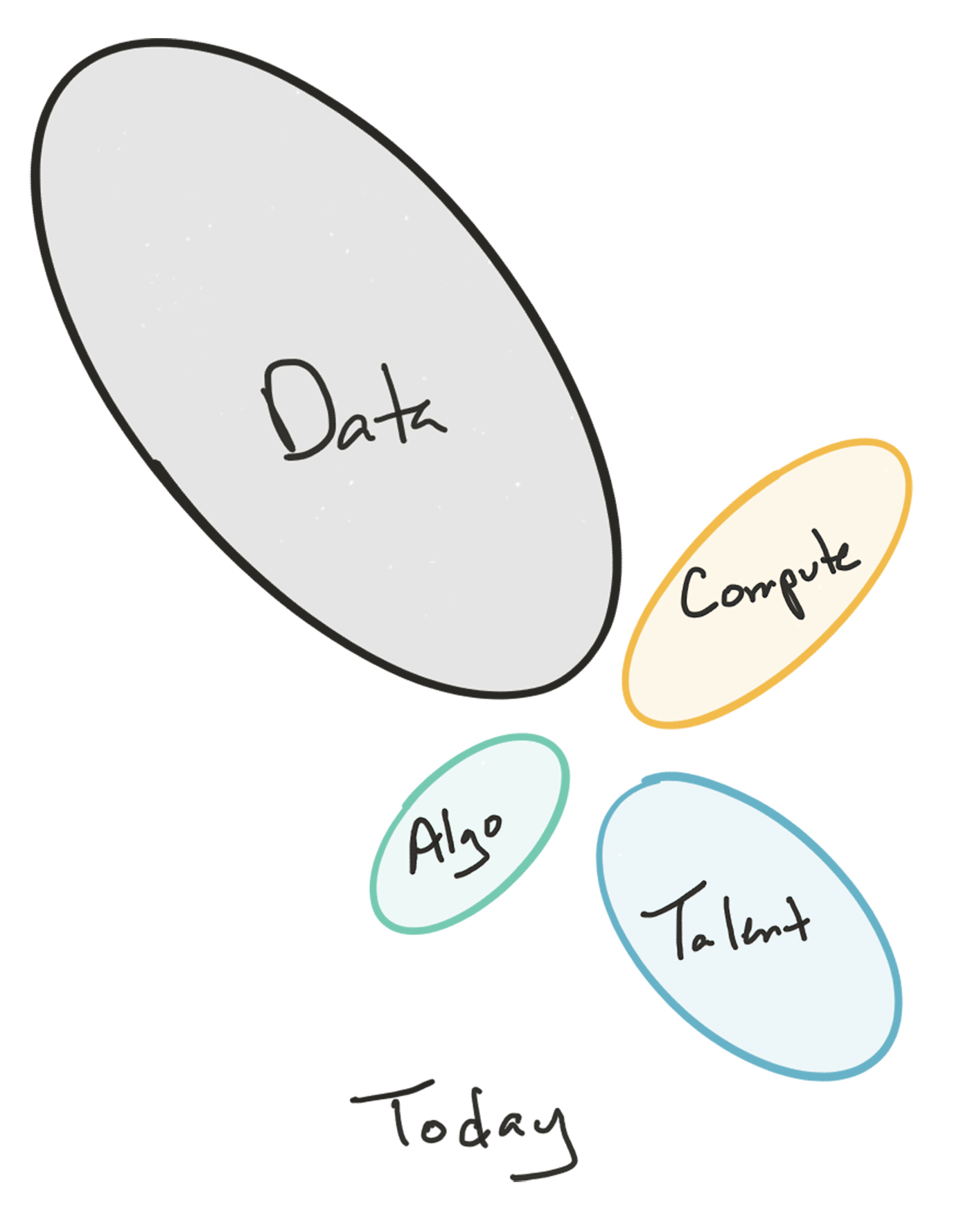
(Note that bubble size here is scarcity, not importance—these resources are all necessary)
But this particular distribution of AI ingredient scarcity is not the only possible configuration, and it is in fact quite new (though see here for the argument that data sets are the fundamentally scarce resource). For example, the realization that very large and expensive-to-gather data sets are in fact crucial in creating the most valuable and impactful AI systems is usually credited to Google, and is largely a phenomenon of the last 10-15 years. The demand for these data sets has therefore grown fantastically; their supply has increased as well, but not at the same rate.
The conventional wisdom was quite different around the turn of the century, when many of the smartest practitioners viewed the relative importance of the ingredients quite differently, leading to a different distribution of demand. People knew that data was essential, to be sure, but the scale at which it was needed simply wasn’t appreciated. On the other hand, reliance on different (and often secret) algorithms for competitive differentiation was much more widespread—even if the actual superiority of these proprietary methods didn’t live up to their perceived worth. We might caricature the scarcity distribution of this pre-big data AI era as follows:
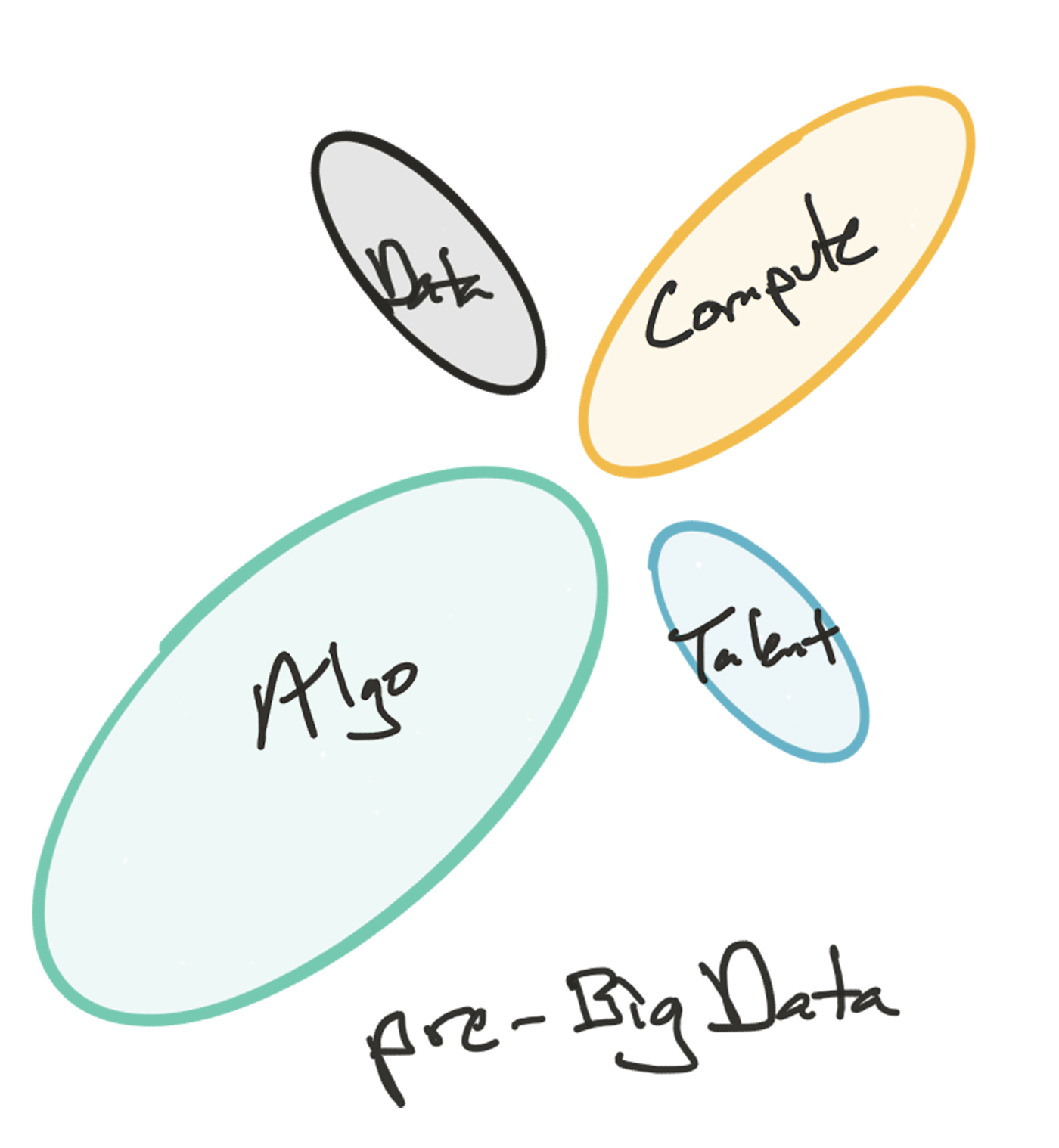
Debate the details if you will, but the overall balance was certainly quite different: this was a time when the most successful approach to natural language understanding, for example, was to construct parsers that included detailed grammar rules for the language in question, rather than today’s practice of extracting statistical patterns from very large text corpora. And eliciting explicit knowledge from experts through in-person interviews and encoding the results into formal decision rules was a dominant learning method, rather than today’s standard approach of extracting patterns automatically from many examples.
Forces driving abundance and scarcity of ingredients
This glimpse at recent history motivates the question: will our current scarcity distribution hold, or instead shift again? Which immediately begs another question: what are the factors that affect the absolute and relative scarcity levels of each ingredient?
We don’t have room here for a complete exploration of the many variables, but a brief tour should at least get the critical juices flowing.
New technology advances obviously drive change in AI. Perhaps a new kind of sensor will reach a price/performance tipping point that allows it to be deployed at massive scale, transforming our ability to observe and track human behavior. New chip architectures or even circuit substrates may emerge that fundamentally alter the capital requirements for running the most effective AI methods—either pushing them up, so that the needed computing resources are no longer a cheap commodity, or down, so that highly capable intelligences are significantly cheaper to train and run. Or new algorithms could emerge that require much less data to train: it is widely noted that, unlike today’s machine learning methods, humans do not need thousands or millions of labeled examples to make new distinctions, but can instead generalize in very nuanced ways from just a handful of cases. In fact, such data-efficient methods are undergoing intense development in academic and corporate research labs today, and constitute one of the most active areas of the field. What would happen to the balance of scarcity if these algorithms proved their effectiveness and became widely available?
Technology is not developed in a vacuum, but rather constitutes just one major element in the larger socioeconomic system. Shifts may occur in the political and public opinion landscape around issues of privacy, economic inequality, government power, and virtual or physical security. These changes in public sentiment can themselves be motivated by technological advances, and can in turn feed back to influence the pace and direction of those technology developments. Such policy and political shifts might render data collection harder (or easier), which could influence which algorithm classes are the most valuable to invest in.
The larger economic picture can also change the context in which AI is developed. For example, the skills distribution of the workforce will inevitably shift over time. As the simplest example, the current scarcity of qualified AI architects and developers will surely drive more people to enter the field, increasing the supply of qualified people. But other shifts are possible, too: continued difficulty in finding the right workers could tip the balance toward algorithms that are easier to train for a class of workers with less rarefied skills, for example. Or a new technology may emerge that requires a new mix of skills to reach its full potential—say, more coach or trainer than today’s applied mathematicians and engineers.
Possible scenarios for the future of AI
With these and other possible factors in mind, it should be clear that today’s status quo is at least subject to question—while it might endure for some time, it’s far more likely to represent a temporary equilibrium. Looking forward, a large number of scenarios are possible; we only have room to describe a few of them here, but I hope that this piece sparks a bit of discussion about the full range of conceivable outcomes.
First, the baseline scenario is a straightforward extrapolation from our current situation: data, at large scale and of high quality, remains the key differentiator in constructing AIs. New hardware architectures that accelerate the most important learning algorithms may also come into play, but the role of these new substrates remains secondary. The net effect is that AI remains a capital-intensive and strong-get-stronger affair: while there is near-universal consumer access to no-cost, shared, cloud-based AIs, these systems are exclusively created by, and ultimately reflect the interests and priorities of, highly resourced organizations.
This is the future that Kevin Kelly foresees in his recent book, The Inevitable:
The bigger the network, the more attractive it is to new users, which makes it even bigger and thus more attractive, and so on. A cloud that serves AI will obey the same law. The more people who use an AI, the smarter it gets. The smarter it gets, the more people who use it. The more people who use it, the smarter it gets. And so on. Once a company enters this virtuous cycle, it tends to grow so big so fast that it overwhelms any upstart competitors. As a result, our AI future is likely to be ruled by an oligarchy of two or three large, general-purpose cloud-based commercial intelligences.
In a second scenario, developments in the technical or political sphere alter the fundamental dynamics of access to data, making training data sets accessible to a much broader range of actors. This in turn gradually loosens the near-monopoly on talent currently held by the leading AI companies, which the top recruits no longer in thrall to the few sources of good data. Assuming the necessary compute remains a cheap commodity, this is a more “open” world, one in which it’s easier to imagine powerful AIs being developed that reflect the interests of a broader range of individuals and organizations.
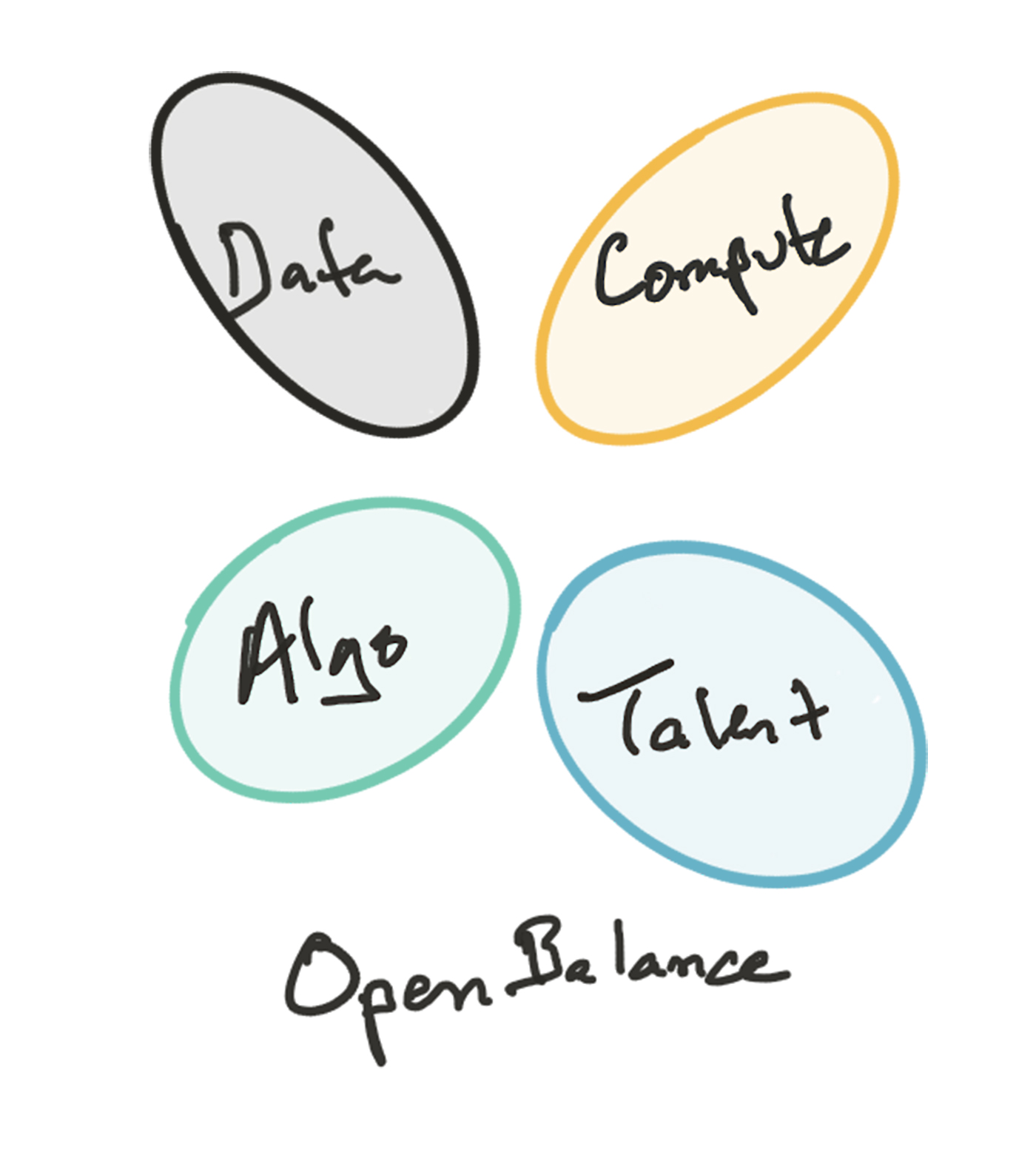
We can also consider more exotic scenarios, such as the one illustrated below. Consider a scenario in which the human talent element becomes even more differentiating and scarce than today (i.e., a world where the most effective AI algorithms must be taught and trained, and where some people are much better at this than others). Data, compute power, and the “blank slate” software are all available off-the-shelf, but the most gifted AI teachers are very highly sought-after. This seems far-fetched in our current technosocial landscape, but I wouldn’t be surprised if, one way or another, the scarcity landscape of the year 2030 didn’t seem at least this outlandish.
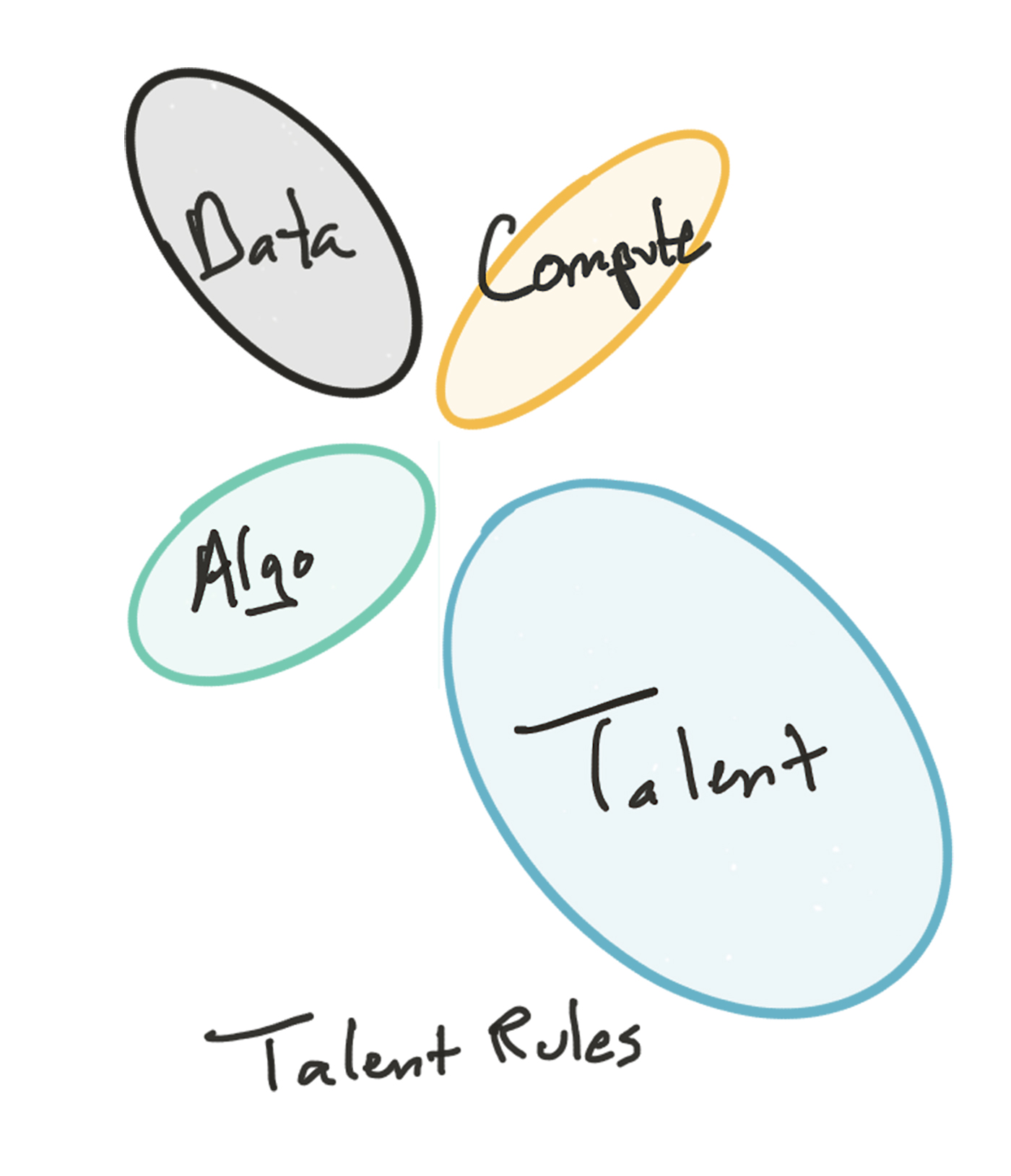
Several early readers of this piece had their own pet scenarios in mind—including, I was glad to see, storylines in which the general public awoke to the value of personal data and demanded the right to control and profit from access to it—and I hope that they and others will share and debate them in a public forum. How do you see the driving forces playing out in the years to come, and what scenarios do those developments suggest?
Broadening the discussion
Two tired frames currently dominate the popular discussion about the future of AI: will robots and automation take all the jobs? And how long after that before a superintelligent AI kills or enslaves us all? These derpy discussions distract us from the issues around AI that are far more likely to impact us, for better and worse, in the next few decades. AI will certainly change our lives and livelihoods, but the ways in which this plays out will depend largely on which aspects of AI creation remain difficult versus easy, expensive versus affordable, exclusive versus accessible, and serious versus child’s play.
Why does this ultimately matter? As Ben Lorica and Mike Loukides wrote in their report “What is Artificial Intelligence?”:
If AI research becomes the sole province of the military, we will have excellent auto-targeting drones; if AI research becomes the sole province of national intelligence, we will have excellent systems for surreptitiously listening to and understanding conversations. Our imaginations will be limited about what else AI might do for us, and we will have trouble imagining AI applications other than murderous drones and the watchful ear of Big Brother. We may never develop intelligent medical systems or robotic nurses’ aides.
This, in the end, is why it is important to debate and discuss these scenarios: our AI future is being written as we speak. While it seems unlikely today that, say, the military will dominate the field, it is entirely possible that large companies will. If this outcome is not the one you want, then the analysis here suggests that the key areas to examine are not algorithms or hardware, but rather the data and the talent. As David Chapman points out, “Given sufficient confidence that ‘deep learning would solve multi-billion-dollar problem X, if only we had the data,’ getting the resources to gather the data shouldn’t be difficult.” This even in the face of very large up-front capital outlay.
Today, the center of the AI universe has shifted from academic labs to applied research labs at large technology companies. Whether that remains the case 5, 10, or 20 years from now depends in large part on whether it becomes possible for that activity to happen elsewhere. Will it ever be possible for the next great AI to be born in a garage?