Future-proof and scale-proof your code
Using Apache Beam to become data-driven, even before you have big data.
 Light beam, Luxor, Las Vegas. (source: InSapphoWeTrust on Flickr)
Light beam, Luxor, Las Vegas. (source: InSapphoWeTrust on Flickr)
Many of the students I work with in my big data classes don’t actually have big data problems; instead, they’re worried about future-proofing their code. These students are hoping that when they do have big data to process and analyze, they’ll be ready.
Becoming scale-proof
Future-proofing code means that we’ll be able to run it on new technologies as they come out, without having to re-write the code. As an example, migrating code from Hadoop MapReduce to Apache Spark requires learning a new API, and rewriting code in order to use it, and this should not be necessary.

Learn faster. Dig deeper. See farther.
As data grows, “scale-proofing” code means that we can start out with small data, and have an API that grows with us. Instead of code rewrites as we make the transition from small to big data, we can simply change the platform or execution engine we run on. We can stop rewriting code at every point in our company’s data journey, and use one API to go from small to big data.
A startup example
Here’s a story about the data journey of a startup where I used to work—a mobile and web event listings company, where I joined as Lead Engineer. I started going through the code and found that we weren’t capturing user interactions with the service. It was my first priority to start capturing the data because we could never recover or reconstitute that data; not having a better place for it, I stored all of these accesses in the database.
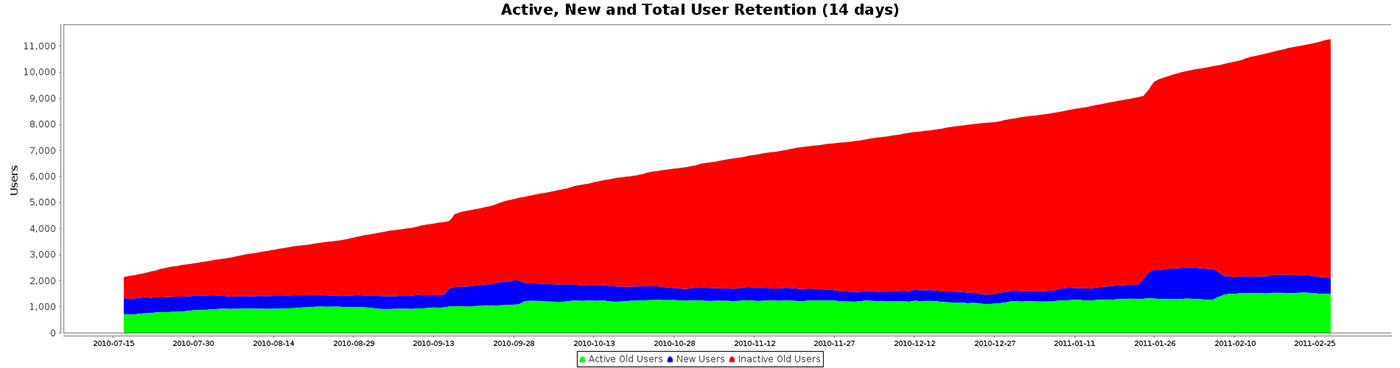
My next priority was to start gaining value from the data. At the time, I created the graph shown below, in an attempt to discover the absolute level of user retention. The green area shows active/retained users, the blue area shows new users, and the red area of the graph shows inactive users or those who never used the service again. The summation of this graph spelled doom for the company—there was an incredibly low conversion rate:
Three reasons not to use big data technology, for small data
The startup in this example did not have big data. Had I used big data technologies in this situation, it would have been a total waste of time and resources. Of course, even though the data was small, I still needed to process it. This is the perfect case for writing code that is scale-proof. Scale-proof code can be written once, and scaled operationally as needed. In this case, the code I wrote was a Java program that loaded everything into memory for processing, and output about 10 different charts showing the (worsening) health of the business.
Let’s say, for example, that I wrote all of this code using MapReduce or Spark APIs. For one, it would have been extremely premature. By the time we actually needed big data, we would have had to rewrite to the newest and hottest framework.
Using big data technologies for small data also has a high operational cost. Many of the questions you need to consider when implementing big data technologies are especially challenging when you only have small data. For example, how would we have spun up a cluster? How often should we have spun up the cluster? If we spun up a cluster for small data, how long would the actual job take?
Finally, the time spent learning big data frameworks, for a startup with small data, is unlikely to have much benefit. There are often other ways in which a business with small data can spend time and money to increase value to the customer. In my particular example, our time may have been better spent perfecting a feature or asking our customers why they stopped using the service.
In many cases, startups are using big data technologies before they have big data needs; in the past, this was often the case because there were not great alternatives—this is not the case today.
Let’s review what we need, even as we process small data. We need to:
- analyze and gain value from data
- scale without having to rewrite code (scale-proof)
- implement new frameworks without having to rewrite code (future-proof)
- avoid operational problems early on
- prevent having to learn several data processing frameworks
Introducing Apache Beam
Apache Beam is a new kind of open source data processing framework, where instead of the API being tied directly to an execution framework, like MapReduce or Spark, you can run it on any supported execution framework. Being able to choose your execution engine allows you to future-proof your code; for example, instead of rewriting code to change between Spark and Flink, you can simply change the execution engine. In this case, you wouldn’t have to learn the Spark or Flink API; you would only have to learn Beam’s API, which is written in Java and will support other languages in the future.
Beam is written to handle data of any size—meaning you can start using it with megabytes of data and scale to petabytes without having to change your code. It also makes it easier to window, sessionize, or process time series.
So far, I’ve talked about Beam using Spark or Flink as the execution engine (runner). Beam also supports local execution, allowing you to run it locally on a machine without installing a Spark or Flink cluster—making your operational overhead the same as running a Java process. Beam also supports both batch and stream processing.
Originally, Apache Beam was Google’s Dataflow Model—the API that Google uses internally for data processing. Google has written several generations of data processing frameworks, learning from each previous generation of APIs, to create one that solves data processing problems, in a faster and cleaner way.
How to know you are ready to scale
There are three runners that Beam currently supports: Google Dataflow, Apache Spark, and Apache Flink (and more are planned). Yet, how do we know when to transition to one of these frameworks? There are several manifestations that might indicate you are running into big data problems and may be ready to scale:
- Your jobs are taking too long. For example, it’s taking 25 hours to process 24 hours of data.
- You want the data faster. If a job runs for nine hours, running it on three machines in a cluster should take three hours.
- Your jobs are business-critical. You need to be able to recover quickly from a job that fails, for whatever reason (and they will fail).
- You’ve exhausted the memory constraints for the JVM. Running locally, Beam will need to keep the data set in memory, and the more processing and the more data you have will require that Beam’s JVM has copious amounts of memory allocatable. (Note: Google Cloud’s VMs can have custom memory and CPU settings. You could boost the memory without boosting CPU and keep costs lower.)
- You want real-time or stream processing. For stream processing, high availability is very important, and these processing engines provide these features out of the box.
Using Beam is a way to scale-proof and future-proof your code because you don’t have to rewrite your code. Instead, you can focus on creating new features or making improvements for better analytics, and avoid spending valuable time rewriting your data processing code to the latest framework.