

 Andy Goldsworthy, Montage by iuri, Sticks Framing a Lake (source: Iuri Kothe on Flickr)
Andy Goldsworthy, Montage by iuri, Sticks Framing a Lake (source: Iuri Kothe on Flickr) A message-based microservices architecture offers many advantages, making solutions easier to scale and expand with new services. The asynchronous nature of interservice interactions inherent to this architecture, however, poses challenges for user-initiated actions such as create-read-update-delete (CRUD) requests on an object. CRUD requests sent via messages may be lost or arrive out of order. Or, multiple users may publish request messages nearly simultaneously, requiring a repeatable method for resolving conflicting requests. To avoid these complexities, user-initiated actions are often treated synchronously, often via direct API calls to object management services. However, these direct interactions compromise some of the message-based architecture’s benefits by increasing the burden of managing and scaling the object-management service.
The ability to handle these scenarios via message-based interactions can prove particularly useful for managing objects that can be modified both by direct user interaction and by service-initiated requests, as well as for enabling simultaneous user updates to an object. In this blog post, we discuss an asynchronous pattern for implementing user-initiated requests via decoupled messages in a manner that can handle requests from multiple users and handle late-arriving messages.
A simple scenario: Team management
To illustrate our pattern, let us consider a Team Service that manages teams in a software-as-a-service solution. Teams have multiple users, or team members, associated with them. Teams also have two attributes that any team member can request to update: screen-name and display color-scheme. In this scenario, only one user, User A, has permission to make requests to create or delete any team. Any user can request to read the state of any team. All permissions and security policies, including team membership, are managed by a separate authorization service that can be accessed synchronously. User interaction is facilitated by a user-interaction service, which allows users to publish CRUD requests to the message bus. Those events are then retrieved by the Team Service, which stores all allowed requests into an event registry and collapses that request history into the current state of a team upon receipt of a READ request.
While the addition of a user-interaction service increases the complexity of the user’s interaction with Team Service, it results in a more scalable and efficient architecture overall. The user-interaction service can be used to publish user requests for any other service as well, so that scaling up to accommodate bursts in user activity can be confined to the user-interaction service and applied to other services secondarily as needed. This approach also minimizes network traffic throughout the architecture, as all external calls are handled by this service. And while this post describes a solution that checks policies at the time of message receipt, a more sophisticated user-interaction service could implement policy checking at the time of publication.
Let us consider a use case where multiple users are attempting to update and read the state of a team. Figure 1 shows the request messages, the time they were published to the message bus, the time they were received by the Team Service, and the messages published to the message bus by the Team Service in response.
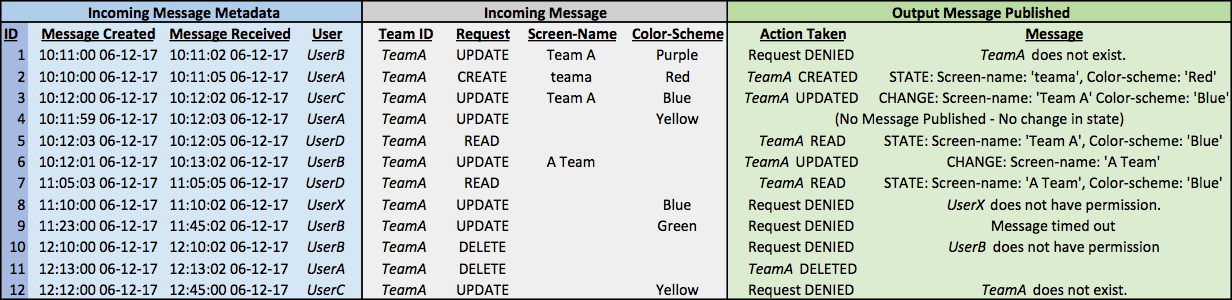
The output messages published by the Team Service based on our pattern demonstrate how we achieve eventual consistency with the users’ desired team state. Our Team Service denies all requests the requesting user does not have permission to make. It also denies any UPDATE or DELETE request associated with a team that does not already exist. Team state is determined by the most recent updates to each team attribute, following an event-sourcing pattern based on request publication time. In this example, we note that message 4 is a “late arrival.” Although it arrived after message 3, it resulted in no change to the Team A state. By 10:12:02, Team A is in a state consistent with all user requests, despite requests coming from multiple users and late-arriving messages. In our implementation, as illustrated by message 9, we include a message time-out for late arrivals beyond a maximum latency time (TIME_OUT_LATENCY = 10 min).
Solution approach
We can achieve the output shown in Figure 1 using two simple sets of rules: business rules and state aggregation rules. Business rules govern how to process incoming request messages. These rules are applied to messages in the order they are received. State aggregation rules govern how to resolve state based on request message history. These rules are applied to the messages in the event registry in the order they were published to the message bus by the requestor. In order to most quickly approach consistency with the state desired by the requestors, this distinction is critical. State should be resolved based on the order requests are published, not the order they are received. This ensures that late-arriving messages do not supersede more recent requests that are in conflict with them.
This example applies the following business rules:
- For all messages, check (i) message format, (ii) whether the request was received more than TIME_OUT_LATENCY time after it was published, and (iii) whether the requestor has permission to make the request.
- Publish request DENIED events to the message bus if any of these checks fail.
- For valid messages, query state of target team.
- Publish request DENIED events to the message bus for the following:
- UPDATE and DELETE requests for teams that do not already exist.
- CREATE requests for teams that already exist.
- Publish all other CREATE, UPDATE, DELETE requests to the event registry.
- Query target team state and publish Team CREATED, Team UPDATED, or Team DELETED if there is a change in team state.
- For READ requests, publish team STATE message to the message bus.
- Publish request DENIED events to the message bus for the following:
In this example, we resolve state from the messages in the event registry by applying the following state aggregation rules to implement the event-sourcing pattern:
- Determine whether target team exists.
- Find all CREATE and DELETE request messages for the target team.
- If the most recently published request is CREATE, the team exists.
- If the most recently published request is DELETE, the team does not exist.
- If there are no CREATE or DELETE requests for a target team, it does not exist.
- Find all CREATE and DELETE request messages for the target team.
- If the team exists, find all request messages associated with the target team that were published after the most recently published CREATE request in the event registry.
- The value for each team attribute is the value set in the most recently published message where it is set or updated. Any updates to that attribute in messages published earlier are ignored.
Solution design
We implement our pattern using a simple architecture that consists of: i) an append-only event registry that stores allowed events, ii) a state engine, and iii) a business rules engine. Notably, our architecture does not include a persistent object store, which is common in a command query responsibility segregation (CQRS) pattern. This is because the addition of an object store would require adding processes and architectural components to maintain its consistency with the event registry, introducing the possibility of conflicting “sources of truth” between the event registry and the object store. Replacing the object store with an event registry and a state engine allows us to reap the advantages of event sourcing, such as auditability and traceability, without additional complexity. And our simple algorithms allow us to quickly resolve incoming request messages, including late arrivals, to respond to READ requests. Figure 2 illustrates our architecture design.
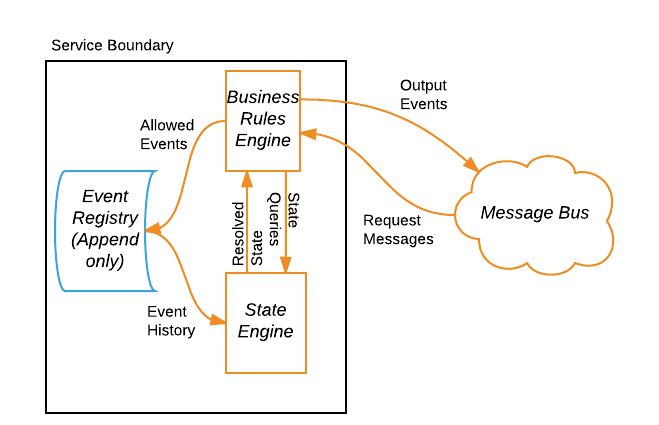
This simple service design minimizes latency in the write path for incoming request messages. And while resolving state does require aggregating multiple messages in the event registry, our algorithm is simple and efficient. By sorting messages by publication time, we can determine state by parsing messages backward in time until the state of all attribute values is known. Regardless of how many UPDATE requests are published, our algorithm only requires parsing enough messages to know the value for each attribute.
In cases where the object being managed is more complex, there are additional rules governing user interactions or how state is determined, or more detailed security policies are needed; our pattern can readily be augmented while maintaining the same architecture. As the event registry grows, we can improve efficiency and reduce registry query load by adding refinements such as caching the most recently resolved state for each object or periodically adding resolved state to the registry and limiting queries to messages received after state publication.
Summary
Event sourcing and asynchronous, message-based interprocess interactions provide an attractive architectural principle for building a scalable, flexible, microservice-based software. User-initiated CRUD operations, however, create challenges for these patterns due to the possibility of lost or late-arriving messages. In this blog post, we suggest a simple architecture and set of algorithms for asynchronously handling user-initiated CRUD requests. A notable feature of our solution is the lack of an object store, which results in a greatly simplified architecture over a traditional CQRS solution. We replace the object store with an immutable, append-only event registry and a state engine, which provides the auditability advantages of the event-sourcing pattern. Overall, our solution provides a simple framework for implementing message-based, user-initiated CRUD operations that can be easily modified for a variety of applications.