
 "The Highland Shepherd," 1859. (source: Wikimedia Commons)
"The Highland Shepherd," 1859. (source: Wikimedia Commons) “Is my developer team ready for big data?” This is the most common question I’m asked by business leaders. Executives realize that big data projects can build their enterprise, but aren’t sure if their current development teams have the skills to actually create the solutions.
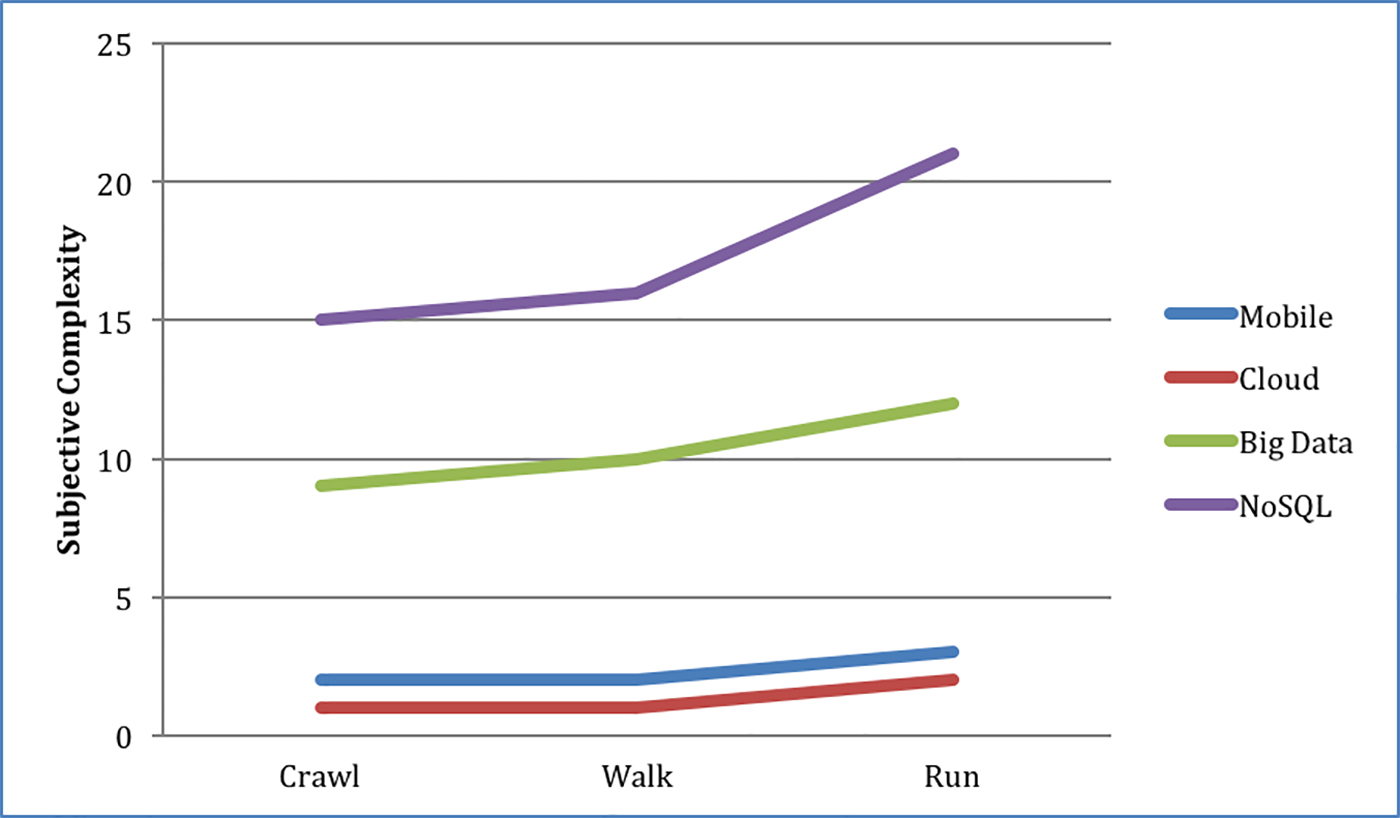
Big data and NoSQL technologies represent dramatic shifts in complexity compared to the technologies that came before, more so than other recent technology revolutions, such as the rise of mobile or cloud. I’ve written before about the stages companies go through as they adopt new technologies, from crawling to walking to running, and big data is more complex at each stage (see Figure 1). Data technologies require a great deal of knowledge to be successful, and if this is the first big data technology your company has deployed, chances are your developers will need some training. And to create a successful big data project, management and individual contributors need to have the skills and abilities to evaluate options, create the solution, and troubleshoot problems.
However, as a manager embarking on a first big data project, how do you know what your team needs to know, whether your current team is up to the task of learning new technologies, and how to bring everyone up to speed? In my work as a trainer, I’ve spent time thinking and observing successful students from my big data classes. What are the common characteristics of developers who have successfully learned big data skills? I’ll provide a non-exhaustive list in order of technical difficulty.
Continuous learners
Developers who have continued to learn new technologies and concepts throughout their professional careers often have a leg up for learning new technologies. They’ve learned how to learn. They understand how to internalize and apply new technology concepts.
Secondly, big data requires various skills like Java, Scala, SQL, and distributed systems. If developers have learned any of these concepts or languages already, they won’t have to learn a new language at the same time as a new technology. I’ve found that learning a new language and a new technology at the same time is a nonstarter for most people.
Comfort with multi-threading
In my trainings, I’ve found that students who are familiar with multi-threading are more likely to understand distributed systems concepts. Even better is familiarity with the java.util.concurrent package in Java.
For a hands-on test, let’s take a look at some code. This code is multi-threaded, but has various mistakes. A developer who’s poised to learn more about big data should be able to see the multi-threading issues and explain why they are problems.
for (int i = 0; i < POOL_SIZE; i++) {
submit = executorService.submit(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 50000; i++) {
myCount = myCount + 1;
}
}
});
}
submit.get();
System.out.println(myCount);
So after looking at this code, I would ask, what will the code snippet output with a POOL_SIZE of 4? And, are there any multi-threading issues with this code? The answers that I would be looking for are: (1) that the output will always be random, and (2) there are at least two issues: first, that each thread will be overwriting the other’s new value; and second, only one future is “get,” so not all threads will be finished executing when the output is created.
Here is another snippet for review. This one shows the use of partitioning and key/values, both common concepts in big data:
HashMap<String, ArrayList<String>> postalCodeToList = getPostalCodes();
ExecutorService executorService = Executors
.newFixedThreadPool(POOL_SIZE);
ArrayList<Future<?>> futures = new ArrayList<Future<?>>();
Iterator<Entry<String, ArrayList<String>>> iterator = postalCodeToList
.entrySet().iterator();
for (int i = 0; i < POOL_SIZE; i++) {
futures.add(executorService.submit(new Runnable() {
@Override
public void run() {
while (iterator.hasNext()) {
ArrayList<String> list = null;
synchronized (iterator) {
list = iterator.next().getValue();
}
if (list != null) {
int localCount = 0;
for (String listItem : list) {
// Do something with listItem
localCount++;
}
synchronized (mapCount) {
mapCount += localCount;
}
}
}
}
}));
}
for (Future<?> future : futures) {
future.get();
}
System.out.println(mapCount);
After looking at this, I would ask a developer if there are any issues with using postal or ZIP codes to identify large groups of data. Additionally, I’d ask whether the threads will complete at the same time, and why or why not. As far as postal codes go, I’d hope that a developer would point out that postal codes are created based on geographic area, not population, and may not be appropriate keys to identifying large segments of data, if the amount of data is based on the number of people. Additionally, at scale, a big ZIP code could get an OutOfMemoryError exception. Regarding the threading question, an issue to point out is that using this code may result in one thread that takes way too long to complete.
As an aside, ask about the use of synchronized blocks. What would happen if we remove one? For example, how would the program execute if we were to change:
synchronized (iterator) {
list = iterator.next().getValue();
}
to:
list = iterator.next().getValue();
It’s worth noting that frameworks like Hadoop and Spark handle threading for the developer. However, I’ve still found that the ability to understand multi-threading issues is an indicator of success.
Understanding multi-process systems
Big data frameworks are distributed systems and run on many computers at once. Understanding how to run multiple processes on different computers simultaneously is another identifier that a developer is ready to dive into big data.
Many programmers have only written programs where everything is contained in a single process. Once several processes need to work together, the complexity of the system goes up dramatically. A programmer will need to understand the difficulty of maintaining a coherent state across many processes.
If a programmer hasn’t written multi-threaded or multi-process programs, does that mean they can’t do big data? I’ve seen a few developers overcome this deficit and go on to do good work with big data; however, odds of success are very low. Often, those who try achieve a very small portion of their stated goals and take far longer to achieve them.
The final word: Ability level that matches the complexity of the tasks
At the different companies I’ve taught at, the students and their ability levels have varied. A company’s use case for big data may be simple and straightforward, requiring programmers at a low skill level. Or, it may be difficult and require highly skilled programmers. Business leaders need to gauge the complexity of their use cases and accurately assess their programmers’ abilities, using methods like the ones I just outlined.
Business leaders can make all the difference in a successful big data project by understanding the particular strengths of their developer teams, realizing the proper training they will need, and enabling them to shine by giving them the right resources to build the right products. Together, you can be successful in your big data journey.