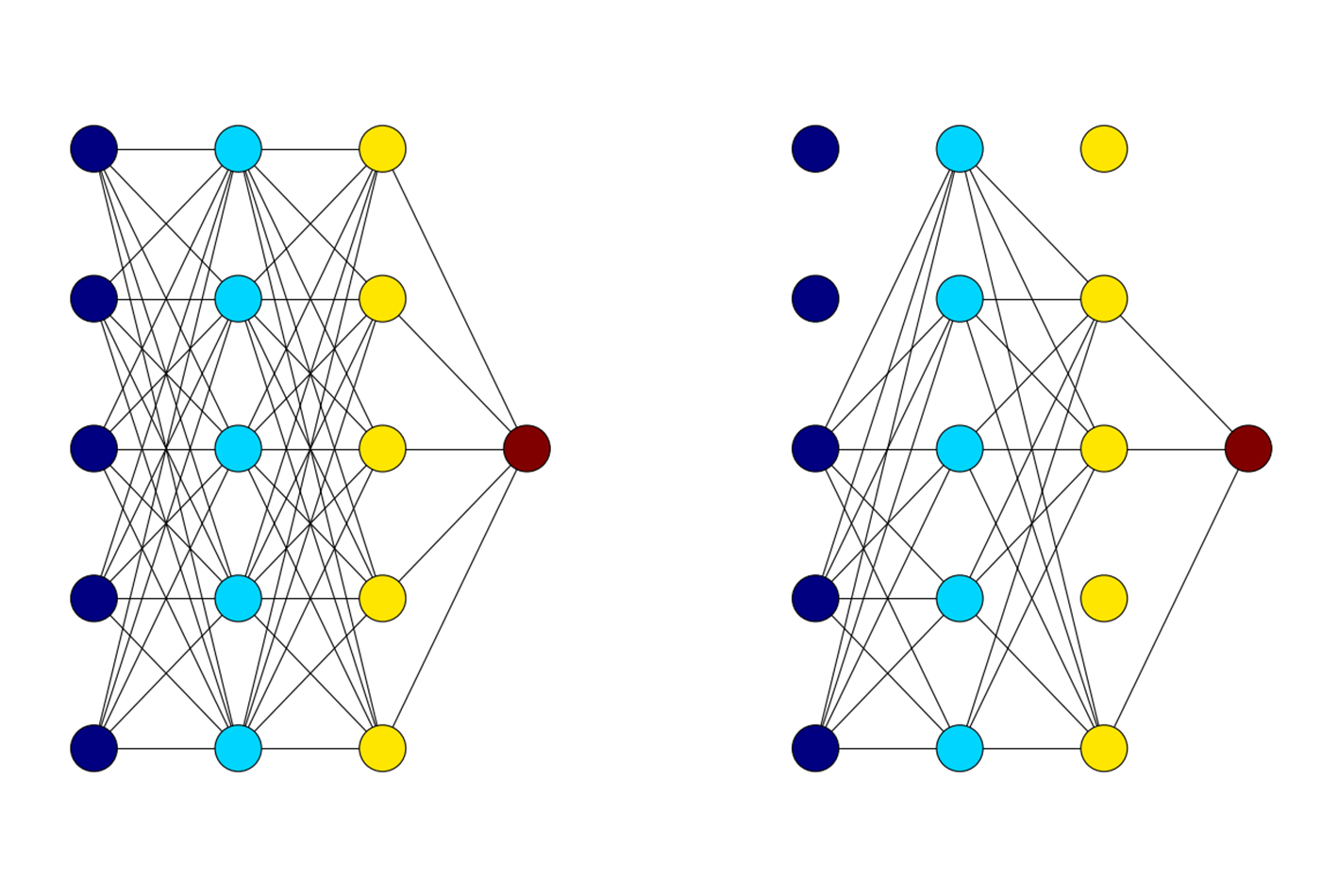
 On the left: A normal fully connected network. On the right: The same network during training, with p = 0.5. (source: Steven Hewitt, used with permission)
On the left: A normal fully connected network. On the right: The same network during training, with p = 0.5. (source: Steven Hewitt, used with permission) Textual entailment is a simple exercise in logic that attempts to discern whether one sentence can be inferred from another. A computer program that takes on the task of textual entailment attempts to categorize an ordered pair of sentences into one of three categories. The first category, called “positive entailment,” occurs when you can use the first sentence to prove that a second sentence is true. The second category, “negative entailment,” is the inverse of positive entailment. This occurs when the first sentence can be used to disprove the second sentence. Finally, if the two sentences have no correlation, they are considered to have a “neutral entailment.”
Textual entailment is useful as a component in much larger applications. For example, question-answering systems may use textual entailment to verify an answer from stored information. Textual entailment may also enhance document summarization by filtering out sentences that don’t include new information. Other natural language processing (NLP) systems find similar uses for entailment.
This article will guide you through how to build a simple and fast-to-train neural network to perform textual entailment using TensorFlow.
Before we get started
In addition to installing TensorFlow version 1.0, make sure you’ve installed each of the following:
To get a better sense of progress during network training, you’re also welcome to install TQDM, but it’s not required. Please access the code and Jupyter Notebook for this article on GitHub. We’ll be using Stanford’s SNLI data set for our training, but we’ll download and extract the data we need using code from the Jupyter Notebook, so you don’t need to download it manually. If this is your first time working with TensorFlow, I’d encourage you to check out Aaron Schumacher’s article, “Hello, Tensorflow.”
We’ll start by doing all necessary imports, and we’ll let our Jupyter Notebook know it should display graphs and images in the notebook itself.
%matplotlib inline import tensorflow as tf import numpy as np import matplotlib.pyplot as plt import matplotlib.ticker as ticker import urllib import sys import os import zipfile
The files we’re about to use may take five minutes or more to download, so if you’re following along by running the program in the corresponding notebook, feel free to start running the next few cells. In the meantime, let’s explore textual entailment in further detail.
Examples of textual entailment
In this section, we’ll walk through a few examples of textual entailment to illustrate what we mean by positive, negative, and neutral entailment. To begin, we’ll look at positive entailment—when you read, for example, that “Maurita and Jade both were at the scene of the car crash,” you can infer that “Multiple people saw the accident.” In this example sentence pair, we can prove the second sentence (also known as a “hypothesis”) from the first sentence (also called the “text”), meaning that this represents a positive entailment. Given that Maurita and Jade were both there to view the crash, multiple people must have seen it. Note: “car crash” and “accident” have similar meanings, but they aren’t the same word. In fact, entailment doesn’t always mean that the sentences share words, as can be seen in this sentence pair, which only shares the word “the.”
Let’s consider another sentence pair. How, if at all, does the sentence “Two dogs played in the park with the old man” entail “There was only one canine in the park that day”? If there are two dogs, there must be at least two canines. Since the second sentence contradicts that idea, this is negative entailment.
Finally, to illustrate neutral entailment, we consider, how, if at all, the sentence “I played baseball with the kids” entails “The kids love ice cream.” Playing baseball and loving ice cream have absolutely nothing to do with each other. I could play baseball with ice cream lovers, and I could play baseball with ice cream haters (both are equally possible). Thus, the first sentence says nothing about the truth or falsehood of the second—implying neutral entailment.

Representing words as numbers using word vectorization
Unfortunately for neural networks, they primarily work with numeric values. To get around this, we need to represent our words as numbers in some way. Ideally, these numbers mean something; for example, we could use the character codes of the letters in a word, but that doesn’t tell us anything about the meaning of it (which would mean that TensorFlow would have to do a lot of work to tell that “dog” and “canine” are close to the same concept). Turning similar meanings into something a neural network can understand happens by a process called word vectorization.
One common way to create word vectorizations is to have each word represent a single point in a very high-dimensional space. Words with similar representations should be relatively close together in this space. For example, each color has a representation that is usually very similar to other colors; demonstrations of this can be found in the TensorFlow tutorial on word vectorization.
Working with Stanford’s GloVe word vectorization + SNLI data set
For our purposes, we won’t need to create a new representation of words as numbers. There already exist quite a few fantastic general-purpose vector representations of words as well as ways to train even more specialized material if the general-purpose data isn’t enough.
The associated notebook for this article is designed to work with the pre-trained data for Stanford’s GloVe word vectorization. We’ll be using the six-billion-token Wikipedia 2014 + Gigaword 5 vectors, since it’s the smallest and easiest to download. We’ll download the file programmatically, but keep in mind that it may take a while to run (it’s a fairly large file).
At the same time, we’ll also be picking up our data set for textual entailment: Stanford’s SNLI data set. We’ll be using the development set in the interest of speed (it has only 10,000 sentence pairs), but if you’re interested in getting better results and have time to spare for training, you can try using the full data set instead.
glove_zip_file = "glove.6B.zip" glove_vectors_file = "glove.6B.50d.txt" snli_zip_file = "snli_1.0.zip" snli_dev_file = "snli_1.0_dev.txt" snli_full_dataset_file = "snli_1.0_train.txt"
from six.moves.url.lib.request import urlretrieve
#large file - 862 MB
if (not os.path.isfile(glove_zip_file) and
not os.path.isfile(glove_vectors_file)):
urlretrieve ("http://nlp.stanford.edu/data/glove.6B.zip",
glove_zip_file)
#medium-sized file - 94.6 MB
if (not os.path.isfile(snli_zip_file) and
not os.path.isfile(snli_dev_file)):
urlretrieve ("https://nlp.stanford.edu/projects/snli/snli_1.0.zip",
snli_zip_file)
def unzip_single_file(zip_file_name, output_file_name):
"""
If the outFile is already created, don't recreate
If the outFile does not exist, create it from the zipFile
"""
if not os.path.isfile(output_file_name):
with open(output_file_name, 'wb') as out_file:
with zipfile.ZipFile(zip_file_name) as zipped:
for info in zipped.infolist():
if output_file_name in info.filename:
with zipped.open(info) as requested_file:
out_file.write(requested_file.read())
return
unzip_single_file(glove_zip_file, glove_vectors_file)
unzip_single_file(snli_zip_file, snli_dev_file)
# unzip_single_file(snli_zip_file, snli_full_dataset_file)
Now that we have our GloVe vectors downloaded, we can load them into memory, deserializing the space separated format into a Python dictionary:
glove_wordmap = {}
with open(glove_vectors_file, "r") as glove:
for line in glove:
name, vector = tuple(line.split(" ", 1))
glove_wordmap[name] = np.fromstring(vector, sep=" ")
Once we have our words, we need our input to contain entire sentences and process it through a neural network. Let’s start with making the sequence:
def sentence2sequence(sentence):
"""
- Turns an input sentence into an (n,d) matrix,
where n is the number of tokens in the sentence
and d is the number of dimensions each word vector has.
Tensorflow doesn't need to be used here, as simply
turning the sentence into a sequence based off our
mapping does not need the computational power that
Tensorflow provides. Normal Python suffices for this task.
"""
tokens = sentence.lower().split(" ")
rows = []
words = []
#Greedy search for tokens
for token in tokens:
i = len(token)
while len(token) > 0 and i > 0:
word = token[:i]
if word in glove_wordmap:
rows.append(glove_wordmap[word])
words.append(word)
token = token[i:]
i = len(token)
else:
i = i-1
return rows, words
What the computer sees when it looks at a sentence
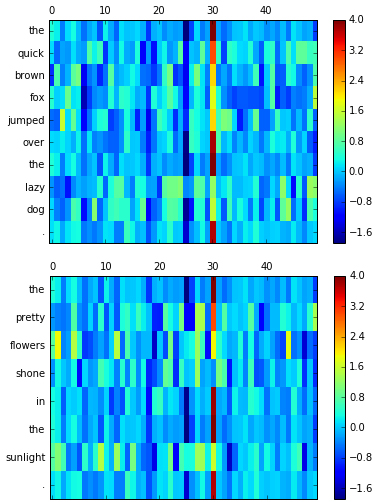
To better visualize the word vectorization process, and to see what the computer sees when it looks at a sentence, we can represent the vectors as images. Feel free to use the notebook to play around with visualizing your own sentences. Each row represents a single word, and the columns represent individual dimensions of the vectorized word. The vectorizations are trained in terms of relationships to other words, so what the representations actually mean is ambiguous. The computer can understand this vector language, and that’s the most important part to us. Generally speaking, two vectors that contain similar colors in the same positions represent words that are similar in meaning.
def visualize(sentence):
rows, words = sentence2sequence(sentence)
mat = np.vstack(rows)
fig = plt.figure()
ax = fig.add_subplot(111)
shown = ax.matshow(mat, aspect="auto")
ax.yaxis.set_major_locator(ticker.MultipleLocator(1))
fig.colorbar(shown)
ax.set_yticklabels([""]+words)
plt.show()
visualize("The quick brown fox jumped over the lazy dog.")
visualize("The pretty flowers shone in the sunlight.")
Unlike images, sentences are inherently sequential and can’t be constrained by size, so instead of fully connected forward-feeding networks that take in one input value and simply run until it produces a single output, we need a new type of network. We need…recurrence.
Vanilla recurrent networks
Recurrent neural networks (RNNs) are a sequence-learning tool for neural networks. This type of neural network has only one layer’s worth of hidden inputs, which is re-used for each input from the sequence, along with a “memory” that’s passed ahead to the next input’s calculations. These are calculated using matrix multiplication, where the matrix indices are trained weights, just like they are in a fully connected layer.
The same calculations are repeated for each input in the sequence, meaning that a single “layer” of a recurrent neural network can be unrolled into many layers. In fact, there will be as many layers as there are inputs in the sequence. This allows the network to process a very complex sentence. TensorFlow includes its own implementation of a vanilla RNN cell, BasicRNNCell, which can be added to your TensorFlow graph as follows:
rnn_size = 64 rnn = tf.contrib.rnn.BasicRNNCell(rnn_size)
The vanishing gradient problem
In theory, the network would be able to remember things from one of the first layers, much earlier in the sentence—even at the end of the sentence. The main problem with this form of recurrence is that, in practice, earlier data is completely drowned out by newer inputs and information that doesn’t end up being nearly as important. Recurrent neural networks, or at least a neural network with standard hidden units, often fail to hold on to information for long periods of time. This failure is known as the vanishing gradient problem.
The simplest way to visualize this is by example. In the simplest case, input and “memory” are roughly equally weighted. The first input into the data will affect approximately half of the first output (the other half being the starting “memory”), a quarter of the second output, then an eighth of the third output, and so on.
This means we can’t use vanilla recurrent networks, at least not if we want to keep track of both sentences in this pair. The solution is to use a different type of recurrent network layer. Perhaps the simplest of these is the long short-term memory layer, also known as an LSTM.
Utilizing LSTM
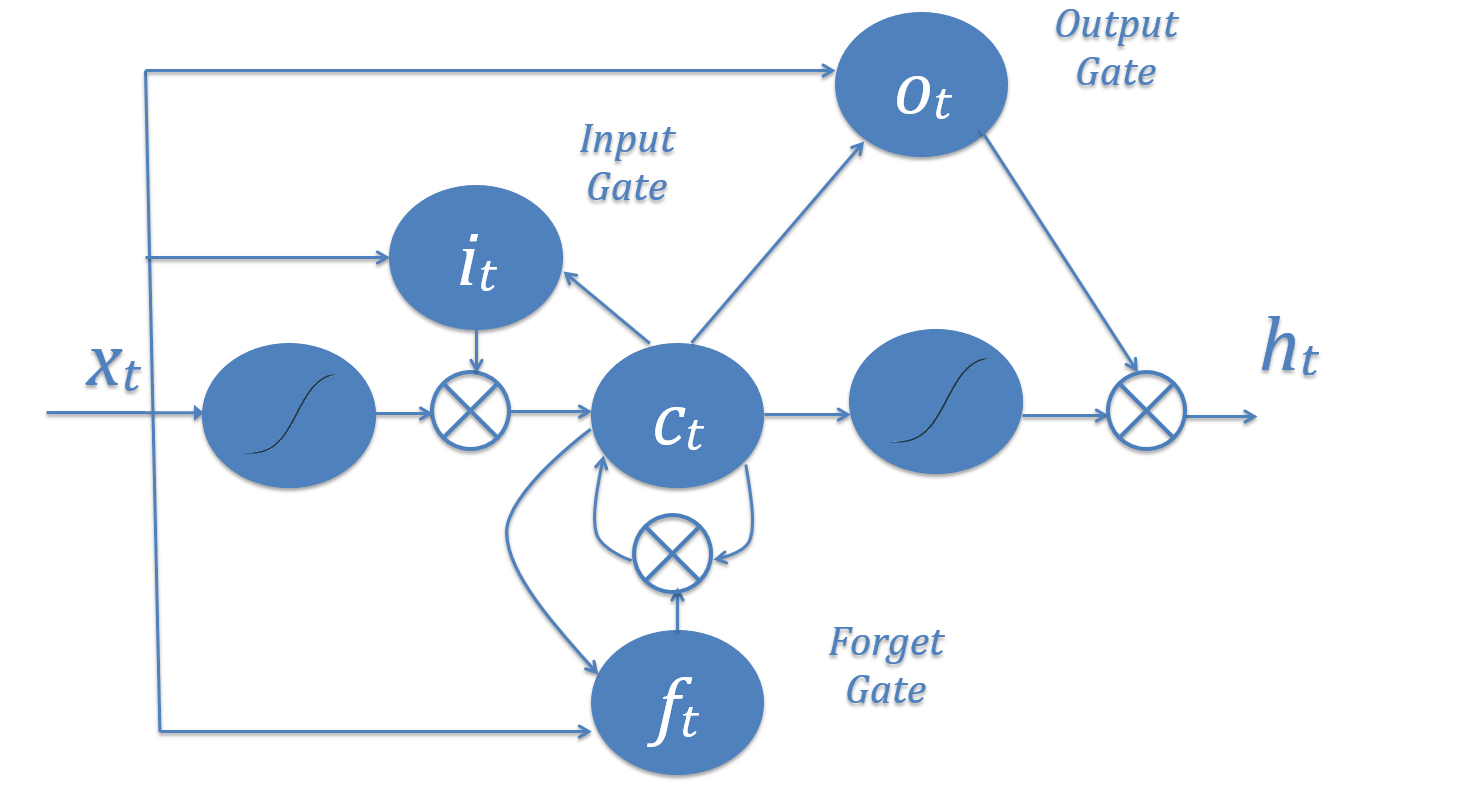
In an LSTM, instead of the input (xt) always being used the same way every time in the calculation of current memory, the network makes a decision on how much the current values can affect the memory by an “input gate” (it), and makes another decision on what memory (ct) is forgotten by an appropriately named “forget gate” (ft), and finally makes a third decision on what parts of memory are sent to the next timestep (ht) by an “output gate” (ot).
{kind=link}
The combination of these three gates creates a choice: a single LSTM node can either keep information in long-term memory or keep it in short-term memory, but it can’t do both at the same time. Short-term memory LSTMs usually train to have relatively open input gates that let a lot of information in and forget many things often, while long-term memory LSTMs have tight input gates that only allow very small, very specific pieces of information in. This tightness means that it doesn’t lose its information easily, allowing for longer retention time.
In general, LSTMs are very cryptic. Different LSTM nodes in the same network may have vastly different gates that rely upon one another, such as perhaps having a short-term gate remember the word “not” in the sentence “John did not go to the store,” so that when the word “go” appears, a long-term gate could remember “not go” instead of “go.” Of course, this is a contrived example, and, in practice, these relationships are very complex to the point of being indecipherable.
Defining the constants for our network
Since we aren’t going to use a vanilla RNN layer in our network, let’s clear out the graph and add an LSTM layer, which TensorFlow also includes by default. Since this is going to be the first part of our actual network, let’s also define all the constants we’ll need for the network, which we’ll talk about as they come up:
#Constants setup
max_hypothesis_length, max_evidence_length = 30, 30
batch_size, vector_size, hidden_size = 128, 50, 64
lstm_size = hidden_size
weight_decay = 0.0001
learning_rate = 1
input_p, output_p = 0.5, 0.5
training_iterations_count = 100000
display_step = 10
def score_setup(row):
convert_dict = {
'entailment': 0,
'neutral': 1,
'contradiction': 2
}
score = np.zeros((3,))
for x in range(1,6):
tag = row["label"+str(x)]
if tag in convert_dict: score[convert_dict[tag]] += 1
return score / (1.0*np.sum(score))
def fit_to_size(matrix, shape):
res = np.zeros(shape)
slices = [slice(0,min(dim,shape[e])) for e, dim in enumerate(matrix.shape)]
res[slices] = matrix[slices]
return res
def split_data_into_scores():
import csv
with open("snli_1.0_dev.txt","r") as data:
train = csv.DictReader(data, delimiter='\t')
evi_sentences = []
hyp_sentences = []
labels = []
scores = []
for row in train:
hyp_sentences.append(np.vstack(
sentence2sequence(row["sentence1"].lower())[0]))
evi_sentences.append(np.vstack(
sentence2sequence(row["sentence2"].lower())[0]))
labels.append(row["gold_label"])
scores.append(score_setup(row))
hyp_sentences = np.stack([fit_to_size(x, (max_hypothesis_length, vector_size))
for x in hyp_sentences])
evi_sentences = np.stack([fit_to_size(x, (max_evidence_length, vector_size))
for x in evi_sentences])
return (hyp_sentences, evi_sentences), labels, np.array(scores)
data_feature_list, correct_values, correct_scores = split_data_into_scores()
l_h, l_e = max_hypothesis_length, max_evidence_length
N, D, H = batch_size, vector_size, hidden_size
l_seq = l_h + l_e
We’ll also reset the graph to not include the RNN cell we added earlier, since we won’t be using that for this network:
tf.reset_default_graph()
With both those out of the way, we can define our LSTM using TensorFlow as follows:
lstm = tf.contrib.rnn.BasicLSTMCell(lstm_size)
Implementing dropout, for regularization
If we simply used LSTM layers and nothing more, the network might read a lot of meaning into common, but inconsequential, words like “a,” “the,” and “and.” The network might incorrectly believe that it has found negative entailment if one sentence uses the phrase “an animal” and the other uses “the animal,” even if those phrases refer to the same object.
To solve this, we need to regulate to see if individual words end up being important to the meaning as a whole, and we do that by a process called “dropout.” Dropout is a regularization pattern in neural network design that revolves around dropping randomly selected hidden and visible units. As the size of a neural network increases, so does the number of parameters used to calculate the final result, each of which contributes to overfitting if trained all at once. In order to regularize for this, a portion of the units contained within the network are selected randomly and zeroed out temporarily during training, and their outputs are scaled appropriately during actual use.
Dropout on “standard” (i.e., fully connected) layers is also useful because it effectively trains multiple smaller networks, and then combines them during testing time. One of the constants in machine learning is that combining multiple models nearly always makes for a better method than a single model on its own, and dropout serves to turn a single neural network into multiple smaller neural networks that share some nodes, and thus some parameters, with the others.
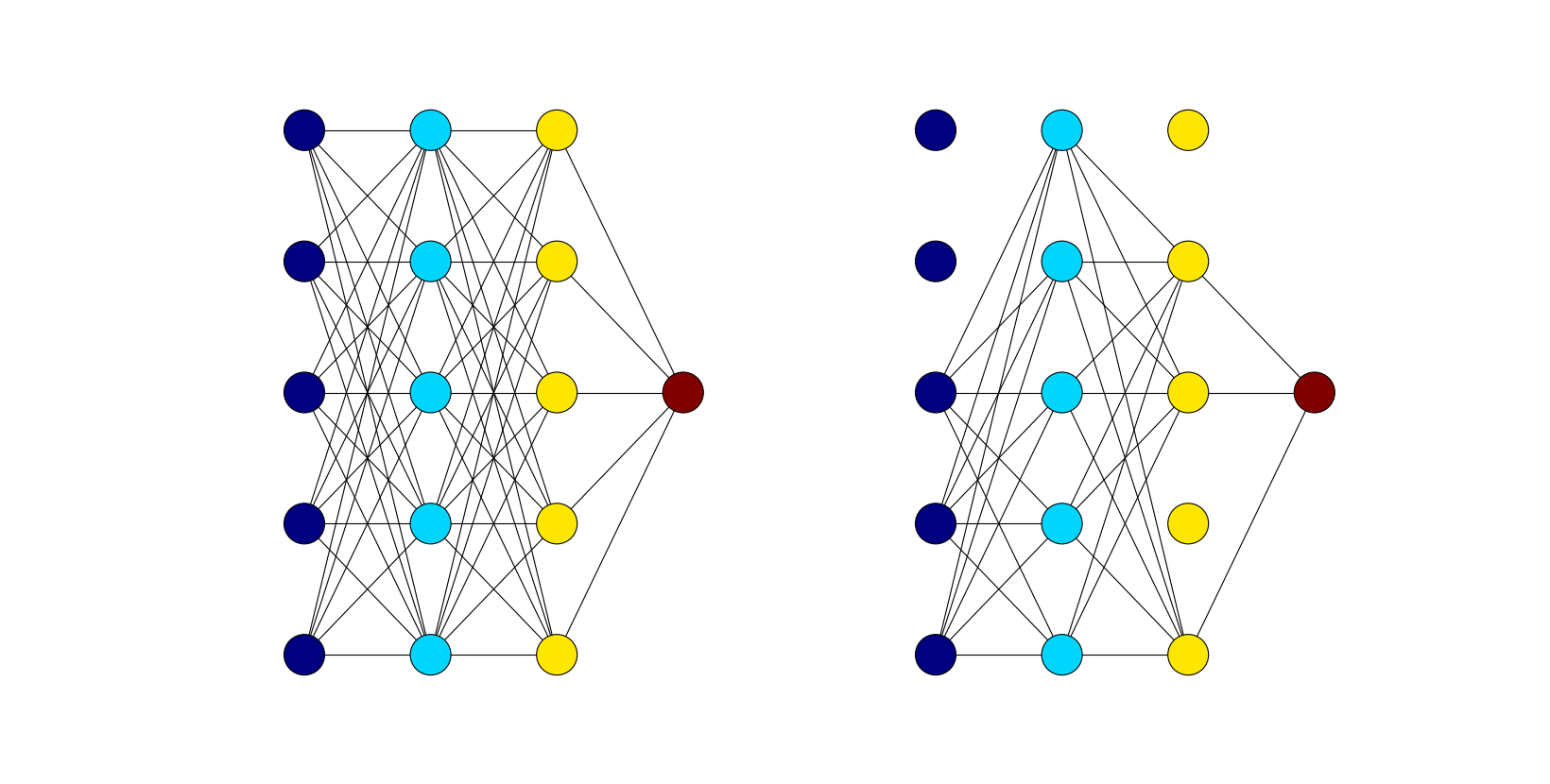
A dropout layer has one hyperparameter known as p, which is simply the probability that each unit is kept in the network for that iteration of training. The units that are kept provide their outputs to the next layer, and the units that are not kept provide nothing. What follows is an example showing the difference between a fully connected network without dropout and a fully connected network with dropout during one iteration of training:
Tensorflow’s DropoutWrapper for recurrent layers
Unfortunately, dropout does not play particularly nicely with LSTM layers’ internal gates. The loss of certain pieces of crucial memory means that complicated relationships required for first-order logic have a harder time forming with dropout, so for our LSTM layer, we’ll skip using dropout on internal gates, instead using it on everything else. Thankfully, this is the default implementation of Tensorflow’s DropoutWrapper for recurrent layers:
lstm_drop = tf.contrib.rnn.DropoutWrapper(lstm, input_p, output_p)
Completing our model
With all the explanations out of the way, we can finish up our model. The first step is tokenizing and using our GloVe dictionary to turn the two input sentences into a single sequence of vectors. Since we can’t effectively use dropout on information that gets passed within an LSTM, we’ll use dropout on features from words and on final output instead—effectively using dropout on the first and last layers from the unrolled LSTM network portions.
You may notice that we use a bi-directional RNN, with two different LSTM units. This form of recurrent network runs both forward and backward through the input data, which allows the network to review both the hypothesis and the evidence both independently and in relation to each other.
The final output from the LSTMs will be passed into a set of fully connected layers, and then from that, we’ll get a single real-valued score that indicates how strong each of the kinds of entailment are, which we use to select our final result and determine our confidence in that result.
# N: The number of elements in each of our batches,
# which we use to train subsets of data for efficiency's sake.
# l_h: The maximum length of a hypothesis, or the second sentence. This is
# used because training an RNN is extraordinarily difficult without
# rolling it out to a fixed length.
# l_e: The maximum length of evidence, the first sentence. This is used
# because training an RNN is extraordinarily difficult without
# rolling it out to a fixed length.
# D: The size of our used GloVe or other vectors.
hyp = tf.placeholder(tf.float32, [N, l_h, D], 'hypothesis')
evi = tf.placeholder(tf.float32, [N, l_e, D], 'evidence')
y = tf.placeholder(tf.float32, [N, 3], 'label')
# hyp: Where the hypotheses will be stored during training.
# evi: Where the evidences will be stored during training.
# y: Where correct scores will be stored during training.
# lstm_size: the size of the gates in the LSTM,
# as in the first LSTM layer's initialization.
lstm_back = tf.contrib.rnn.BasicLSTMCell(lstm_size)
# lstm_back: The LSTM used for looking backwards
# through the sentences, similar to lstm.
# input_p: the probability that inputs to the LSTM will be retained at each
# iteration of dropout.
# output_p: the probability that outputs from the LSTM will be retained at
# each iteration of dropout.
lstm_drop_back = tf.contrib.rnn.DropoutWrapper(lstm_back, input_p, output_p)
# lstm_drop_back: A dropout wrapper for lstm_back, like lstm_drop.
fc_initializer = tf.random_normal_initializer(stddev=0.1)
# fc_initializer: initial values for the fully connected layer's weights.
# hidden_size: the size of the outputs from each lstm layer.
# Multiplied by 2 to account for the two LSTMs.
fc_weight = tf.get_variable('fc_weight', [2*hidden_size, 3],
initializer = fc_initializer)
# fc_weight: Storage for the fully connected layer's weights.
fc_bias = tf.get_variable('bias', [3])
# fc_bias: Storage for the fully connected layer's bias.
# tf.GraphKeys.REGULARIZATION_LOSSES: A key to a collection in the graph
# designated for losses due to regularization.
# In this case, this portion of loss is regularization on the weights
# for the fully connected layer.
tf.add_to_collection(tf.GraphKeys.REGULARIZATION_LOSSES,
tf.nn.l2_loss(fc_weight))
x = tf.concat([hyp, evi], 1) # N, (Lh+Le), d
# Permuting batch_size and n_steps
x = tf.transpose(x, [1, 0, 2]) # (Le+Lh), N, d
# Reshaping to (n_steps*batch_size, n_input)
x = tf.reshape(x, [-1, vector_size]) # (Le+Lh)*N, d
# Split to get a list of 'n_steps' tensors of shape (batch_size, n_input)
x = tf.split(x, l_seq,)
# x: the inputs to the bidirectional_rnn
# tf.contrib.rnn.static_bidirectional_rnn: Runs the input through
# two recurrent networks, one that runs the inputs forward and one
# that runs the inputs in reversed order, combining the outputs.
rnn_outputs, _, _ = tf.contrib.rnn.static_bidirectional_rnn(lstm, lstm_back,
x, dtype=tf.float32)
# rnn_outputs: the list of LSTM outputs, as a list.
# What we want is the latest output, rnn_outputs[-1]
classification_scores = tf.matmul(rnn_outputs[-1], fc_weight) + fc_bias
# The scores are relative certainties for how likely the output matches
# a certain entailment:
# 0: Positive entailment
# 1: Neutral entailment
# 2: Negative entailment
Showing TensorFlow how to calculate accuracy
In order to test the accuracy and begin to add in optimization constraints, we need to show TensorFlow how to calculate the accuracy—or the percentage of correctly predicted labels.
We also need to determine a loss, to show how poorly the network is doing. Since we have both classification scores and optimal scores, the choice here is using a variation on softmax loss from TensorFlow: tf.nn.softmax_cross_entropy_with_logits. We add in regularization losses to help with overfitting and then prepare an optimizer to learn how to reduce the loss.
with tf.variable_scope('Accuracy'):
predicts = tf.cast(tf.argmax(classification_scores, 1), 'int32')
y_label = tf.cast(tf.argmax(y, 1), 'int32')
corrects = tf.equal(predicts, y_label)
num_corrects = tf.reduce_sum(tf.cast(corrects, tf.float32))
accuracy = tf.reduce_mean(tf.cast(corrects, tf.float32))
with tf.variable_scope("loss"):
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(
logits = classification_scores, labels = y)
loss = tf.reduce_mean(cross_entropy)
total_loss = loss + weight_decay * tf.add_n(
tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES))
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
opt_op = optimizer.minimize(total_loss)
Let’s train the network
Finally, we can train the network! If you installed TQDM, you can use it to keep track of progress as the network trains.
# Initialize variables
init = tf.global_variables_initializer()
# Use TQDM if installed
tqdm_installed = False
try:
from tqdm import tqdm
tqdm_installed = True
except:
pass
# Launch the Tensorflow session
sess = tf.Session()
sess.run(init)
# training_iterations_count: The number of data pieces to train on in total
# batch_size: The number of data pieces per batch
training_iterations = range(0,training_iterations_count,batch_size)
if tqdm_installed:
# Add a progress bar if TQDM is installed
training_iterations = tqdm(training_iterations)
for i in training_iterations:
# Select indices for a random data subset
batch = np.random.randint(data_feature_list[0].shape[0], size=batch_size)
# Use the selected subset indices to initialize the graph's
# placeholder values
hyps, evis, ys = (data_feature_list[0][batch,:],
data_feature_list[1][batch,:],
correct_scores[batch])
# Run the optimization with these initialized values
sess.run([opt_op], feed_dict={hyp: hyps, evi: evis, y: ys})
# display_step: how often the accuracy and loss should
# be tested and displayed.
if (i/batch_size) % display_step == 0:
# Calculate batch accuracy
acc = sess.run(accuracy, feed_dict={hyp: hyps, evi: evis, y: ys})
# Calculate batch loss
tmp_loss = sess.run(loss, feed_dict={hyp: hyps, evi: evis, y: ys})
# Display results
print("Iter " + str(i/batch_size) + ", Minibatch Loss= " + \
"{:.6f}".format(tmp_loss) + ", Training Accuracy= " + \
"{:.5f}".format(acc))
Your network is now trained! You should see accuracies around 50-55%, which can be improved by careful modification of hyperparameters and increasing the data set size to include the entire training set. Usually, this will correspond with an increase in training time.
Feel free to modify the following code in the notebook by inserting your own sentences:
evidences = ["Maurita and Jade both were at the scene of the car crash."]
hypotheses = ["Multiple people saw the accident."]
sentence1 = [fit_to_size(np.vstack(sentence2sequence(evidence)[0]),
(30, 50)) for evidence in evidences]
sentence2 = [fit_to_size(np.vstack(sentence2sequence(hypothesis)[0]),
(30,50)) for hypothesis in hypotheses]
prediction = sess.run(classification_scores, feed_dict={hyp: (sentence1 * N),
evi: (sentence2 * N),
y: [[0,0,0]]*N})
print(["Positive", "Neutral", "Negative"][np.argmax(prediction[0])]+
" entailment")
Finally, once we’re done playing with our model, we’ll close the session to free up system resources.
sess.close()
Interested in developing more results?
The design focus of this network was creating a simple system that was easy and quick to train. In order to get more accurate results, you may want to consider:
- Adding more layers of LSTMs.
- Using alternative types of RNN layers, such as Gated Recurrent Units (GRUs). TensorFlow also includes an implementation of GRUs.
- Adding more hidden units. If you do this, increase regularization and dropout strengths to account for the fact that there are more parameters in the network.
- Experimentation with other kinds of networks entirely!
This post is a collaboration between O’Reilly and TensorFlow. See our statement of editorial independence.