

 Card catalog at the Library of Congress (source: picryl.com)
Card catalog at the Library of Congress (source: picryl.com) In a previous post, we talked about applications of machine learning (ML) to software development, which included a tour through sample tools in data science and for managing data infrastructure. Since that time, Andrej Karpathy has made some more predictions about the fate of software development: he envisions a Software 2.0, in which the nature of software development has fundamentally changed. Humans no longer implement code that solves business problems; instead, they define desired behaviors and train algorithms to solve their problems. As he writes, “a neural network is a better piece of code than anything you or I can come up with in a large fraction of valuable verticals.” We won’t be writing code to optimize scheduling in a manufacturing plant; we’ll be training ML algorithms to find optimum performance based on historical data.
If humans are no longer needed to write enterprise applications, what do we do? Humans are still needed to write software, but that software is of a different type. Developers of Software 1.0 have a large body of tools to choose from: IDEs, CI/CD tools, automated testing tools, and so on. The tools for Software 2.0 are only starting to exist; one big task over the next two years is developing the IDEs for machine learning, plus other tools for data management, pipeline management, data cleaning, data provenance, and data lineage.
Karpathy’s vision is ambitious, and we don’t think enterprise software developers need to worry about their jobs any time soon. However, it is clear that the way software is developed is changing. With machine learning, the challenge isn’t writing the code; the algorithms are implemented in a number of well-known and highly optimized libraries. We don’t need to implement our own versions of long short-term memory (LSTM) or reinforcement learning; we get that from PyTorch, Ray RLlib, or some other library. However, machine learning isn’t possible without data, and our tools for working with data aren’t adequate. We have great tools for working with code: creating it, managing it, testing it, and deploying it. But they don’t address the data side, and with ML, managing the data management as important as managing the code itself. GitHub is an excellent tool for managing code, but we need to think about [code+data]. There is no GitHub for data, though we are starting to see version control projects for machine learning models, such as DVC.
It’s important to think precisely about what git does. It captures source code, and all the changes to the source code. For any codebase, it can tell you where the code came from (provenance), and all the changes that led from the original commit to the version you downloaded. It’s capable of maintaining many different branches, reflecting different custom views of the code. If someone has changed a line of code, you will see that change, and who made it. And (with some human help and pain) it can resolve conflicting changes on different branches. Those capabilities are all important for data; but good as git is for code, it isn’t adequate for data. It has trouble with data that isn’t formatted as a sequence of lines (like source code), has problems with binary data, and it chokes on huge files. And it is ill-suited for tracking transformations that change every item in a data set, such as a matrix multiplication or normalization.
We also need better tools for collecting data. Given all the talk about the explosion of data, it’s ironic that most of the data that’s exploding falls on the floor and is never captured. Data management isn’t limited to issues like provenance and lineage; one of the most important things you can do with data is collect it. Given the rate at which data is created, data collection has to be automated. How do you do that without dropping data? Given that the results produced by any model will reflect the data used to create the model, how do you ensure your data collection process is fair, representative, and unbiased?
Toward a sustainable ML practice
In our forthcoming report Evolving Data Infrastructure, one aspect we studied was what European organizations were doing to build a sustainable machine learning practice: not a proof of concept or a one-time cool idea to be dropped when the next technical fad comes along, but a permanent part of the organization’s plans. It’s one thing to kick the tires briefly; it’s something else entirely to deeply build the infrastructure needed to integrate machine learning into your organization.
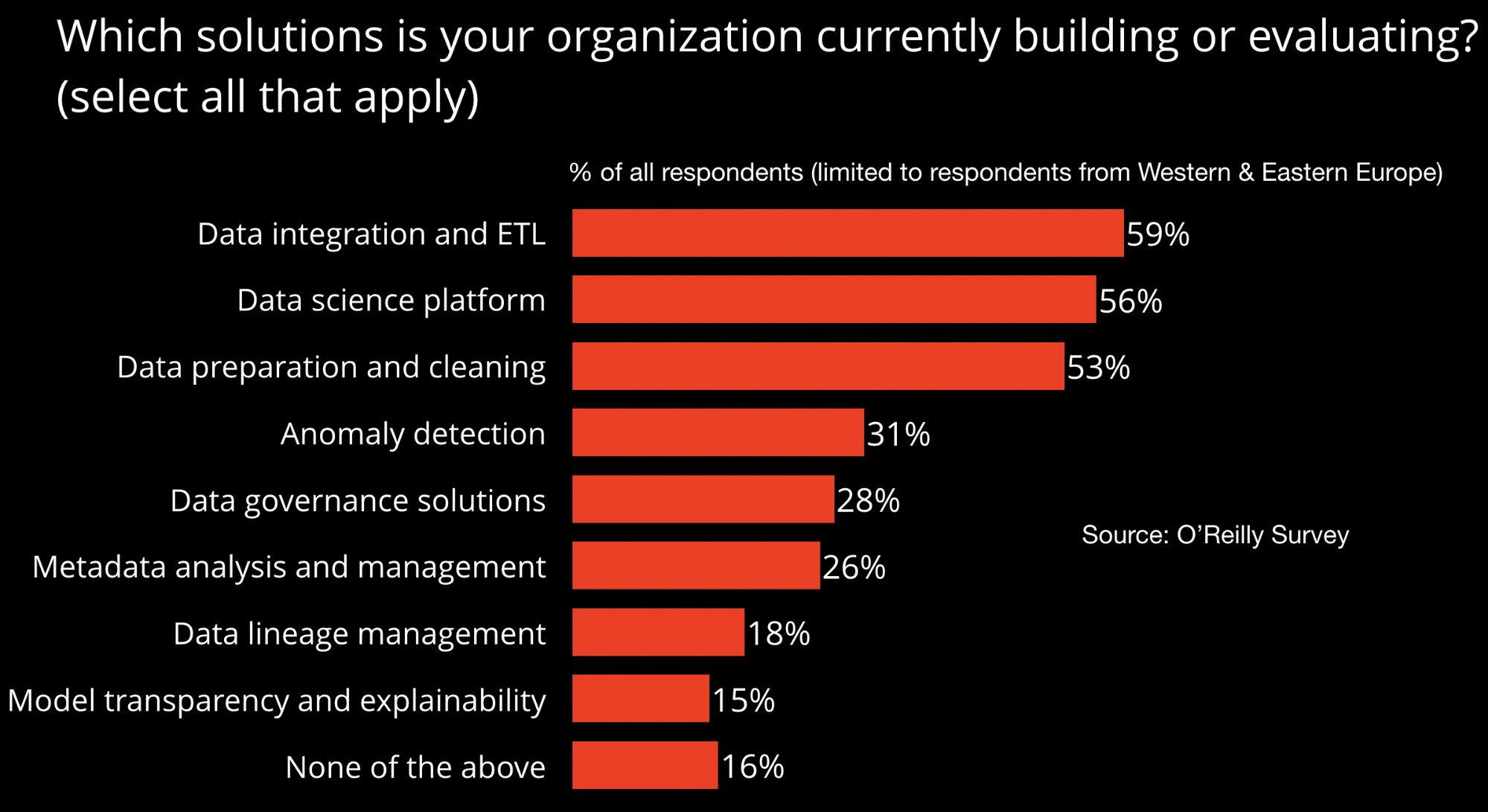
Building a sustainable practice means investing in the tools that allow you to work effectively over the long term. These tools enable you to build software you can rely on, not just proof-of-concept hacks that don’t need to be duplicated. These tools include basics like ETL (extract, transform and load: extracting data from multiple sources, transforming it into a form that’s useful, and loading it into a datastore for analysis). It’s no surprise that companies are investing in data science platforms to run machine learning at scale, just as they invested in Hadoop a decade ago. And given that most of the work of a data scientist is cleaning the data prior to analysis, it’s no surprise that most companies are investing in tools for data preparation. These are tools we would have expected to see on the list five years ago as companies started building their data science practices.
We also see investment in new kinds of tools. Anomaly detection is well-known in the financial industry, where it’s frequently used to detect fraudulent transactions, but it can also be used to catch and fix data quality issues automatically. This isn’t surprising; if you’re collecting data from several weather stations and one of them malfunctions, you would expect to see anomalous data. A faulty weather station might stop reporting data (which might be turned into zeros, infinities, or nulls in your data stream), or it might just send readings that are a few degrees above what’s expected, or that are out of line with other stations in the area. In any case, there will be an anomaly in the input data, and it will be easier for a machine to detect that anomaly than a human. If you suddenly see unexpected patterns in your social data, that may mean adversaries are attempting to poison your data sources. Anomaly detection may have originated in finance, but it is becoming a part of every data scientist’s toolkit.
Metadata analysis makes it possible to build data catalogs, which in turn allow humans to discover data that’s relevant to their projects. Democratizing access to data is a major step on the process to becoming a data-driven (or an AI-driven) company; users must be empowered to explore data and to create their own projects. That is difficult without some kind of data catalog. You can tell users they have access to all the data they need, and given them access to databases, but unless they know what data is available and how to find it, that access doesn’t mean anything. Creating that catalog by hand isn’t possible; it needs to be automated.
Data lineage
The history of data analysis has been plagued with a cavalier attitude toward data sources. That is ending; discussions of data ethics have made data scientists aware of the importance of data lineage and provenance. Both refer to the source of the data: where does the data come from, how was it gathered, and how was it modified along the way? Data provenance is increasingly a legal issue; it’s clearly important to know where data came from and how it was obtained. It’s particularly important when you’re combining data from multiple sources; we’ve often observed that data is most powerful when several sources are combined. Provenance can get very complex, particularly when results generated from one set of data are further combined with other data.
It’s important to be able to trace data lineage at a granular level, to understand the entire path from the source to the application. Data is modified all the time: it’s often been observed that most of the work in data science is cleanup or preparation. Data cleaning involves modifying the data: eliminating rows that have missing or illegal values, for example. We’re beginning to understand exactly how important it is to understand what happened during that cleanup, how data evolved from its raw state: that can be a source of error and bias. As companies ingest and use more data, and as the number of consumers of that data increases, it’s important to know the data is trustworthy. When data is modified, it’s important to track exactly how and when it was modified.
The tools for tracking data provenance and lineage are limited, although products from commercial vendors such as Trifacta are starting to appear. Git and its predecessors (SVN and even RCS) can track every change to every line of code in software, maintain multiple branches of the code, and reconcile differences between branches. How do we do that for data? Furthermore, what will we do with the results? It’s common to normalize data, or to transform in some way, but such transformations can easily change every byte in the data set.
Not only do such changes pose problems, but tools like git force humans to supply explanatory comments when they commit a new version to explain why any change was made. That’s not possible with an automated data pipeline. It might be possible for systems to log and “explain” the changes they make, but this assumes you have fine-grained control to force them to do so.
Such control may be possible within the scope of a single tool. For example, Jacek Laskowski describes how to extract a resilient distributed data set (RDD) lineage graph that describes a series of Spark transformations. This graph could be committed to a lineage tracking system, or even a more traditional version-control system, to document transformations that have been applied to the data. But this process only applies to a single machine learning platform: Spark. To be generally useful, every platform would need to support extracting a lineage graph, preferably in a single format and without requiring additional scripting by developers. That’s a good vision for where we need to go, but we’re not there yet.
Data provenance and lineage isn’t just about the quality of the results; it’s a security and compliance issue. At the Strata Data Conference in New York in 2017, danah boyd argued that social media systems were intentionally poisoned by tools that propagated low-quality content designed to sway the algorithms that determined what people watch. Malicious agents have learned to “hack the attention economy.” In “Flat Light: Data Protection for the Disoriented, from Policy to Practice,” Andrew Burt and Daniel Geer argue that in the past, data accuracy was binary; data was either correct or incorrect. Now, data provenance is as important as correctness, if not more so. You can’t judge whether data is reliable if you don’t know its origin. For machine learning systems, this means we need to track source data as well as source code: the data used to train the system is as important to its behavior as the algorithms and their implementation.
We are starting to see some tools that automate data quality issues. Intuit uses the Circuit Breaker pattern to halt data pipelines when they detect anomalies in the data. Their tool tracks data lineage because it’s important to understand the inputs and outputs of every stage of the pipeline; it also tracks the status of the pipeline components themselves and the quality of the data at every stage of the pipeline (is it within expected bounds, is it of the appropriate type, etc.). Intuit, Netflix, and Stitchfix have built data lineage systems that track the origin and evolution of the data that they use in their systems.
Automation is more than model building
In the past year, we have seen several companies build tools to “automate machine learning,” including Google and Amazon. These tools automate the process of building models: trying different algorithms and topologies, to minimize error when the model is used on test data. But these tools just build models, and we’ve seen that machine learning requires much more. The model can’t exist without tools for data integration and ETL, data preparation, data cleaning, anomaly detection, data governance, and more. Automating model building is just one component of automating machine learning.
To be truly useful, automated machine learning has to go much deeper than model building. It’s too simple to think a machine learning project will require a single model; one project can easily require several different models, doing different things. And different aspects of the business, while superficially similar, can require different models, trained from different data sources. Consider a hotel business such as Marriott: more than 6,000 hotels, and more than $20 billion in gross revenue. Any hotel would like to predict occupancy, income, and the services they need to provide. But each hotel is a completely different business: The Times Square Marriott is dominated by large corporate conferences and New York City tourism, while the Fairfield Inn in Sebastopol is dominated by local events and wine country tourism. The customer demographics are different; but more than that, the event sources are different. The Sebastopol hotel needs to know about local weddings and wine country events; I’d expect them to use natural language processing to parse feeds from local newspapers. The Times Square hotel needs to know about Broadway openings, Yankees games, and Metro-North train schedules. This isn’t just a different model; these two businesses require completely different data pipelines. Automating the model building process is helpful, but it doesn’t go far enough.
Hotels aren’t the only business requiring more models than humans can conceivably build. Salesforce provides AI services for its clients, which number in the hundreds of thousands. Each client needs a custom model; models can’t be shared, even between clients in similar businesses. Aside from confidentiality issues, no two clients have the same customers or the same data, and small differences between clients can add up to large errors. Even with the most optimistic estimates for machine learning talent, there aren’t enough people to build that many models by hand. Salesforce’s solution is TransmogrifAI, an open source automated ML library for structured data. TransmogrifAI automates the model building process, like other Auto ML solutions, but it also automates many other tasks, including data preparation and feature validation.
Other enterprise software vendors are in the same boat: they have many customers, each of whom requires “custom models.” They cannot hire enough data scientists to support all of these customers with conventional manual workflows. Automation isn’t an option; it’s a necessity.
Automation doesn’t stop when the model is “finished”; in any real-world application, the model can never be considered “finished.” Any model’s performance will degrade over time: situations change, people change, products change, and the model may even play a role in driving that change. We expect to see new tools for automating model testing, either alerting developers when a model needs to be re-trained or starting the training process automatically. And we need to go even further: beyond simple issues of model accuracy, we need to test for fairness and ethics. Those tests can’t be automated completely, but tools can be developed to help domain experts and data scientists detect problems of fairness. For example, such a tool might generate an alert when it detects a potential problem, like a significantly higher loan rejection rate from a protected group; it might also provide tools to help a human expert analyze the problem and make a correction.
Closing thoughts
The way we build software is changing. Whether or not we get to Karpathy’s Software 2.0, we’re certainly on a road headed in that direction. The future holds more machine learning, not less; developing and maintaining models will be part of the job of building software. Software developers will be spending less time writing code and more time training models.
However, the lack of data—and of tools for working with data—remains a fundamental bottleneck. Over the past 50 years, we’ve developed excellent tools for working with software. We now need to build the tools for software+data: tools to track data provenance and lineage, tools to build catalogs from metadata, tools to do fundamental operations like ETL. Companies are investing in these foundational technologies.
The next bottleneck will be model building itself; the number of models we need will always be much greater than the number of people capable of building those models by hand. Again, the solution is building tools for automating the process. We need to do more than automate model building with autoML; we also need to automate feature engineering, data preparation, and other tasks at every stage of the data pipeline. Software developers are, after all, in the business of automation. And the most important thing for software developers to automate is their own work.
Related content
- “What machine learning means for software development”
- Vitaly Gordon on “Building tools for enterprise data science”
- Tim Kraska on “How machine learning will accelerate data management systems”
- “Building tools for the AI applications of tomorrow”
- Mark Hammond on why “Machine learning needs machine teaching”
- Joe Hellerstein on how “Metadata services can lead to performance and organizational improvements”