How to think like a data scientist
Using induction to test your hypotheses
 Stator of induction motor. (source: Via Andy Dingley on Wikimedia Commons)
Stator of induction motor. (source: Via Andy Dingley on Wikimedia Commons)
Data science is about finding signals buried in the noise. It’s tough to do, but there is a certain way of thinking about it that I’ve found useful. Essentially, it comes down to finding practical methods of induction, where I can infer general principles from observations, and then reason about the credibility of those principles.
Induction is the go-to method of reasoning when you don’t have all of the information. It takes you from observations to hypotheses to the credibility of each hypothesis. In practice, you start with a hypothesis and collect data you think can give you answers. Then, you generate a model and use it to explain the data. Next, you evaluate the credibility of the model based on how well it explains the data observed so far. This method works ridiculously well.

Learn faster. Dig deeper. See farther.
To illustrate this concept with an example, let’s consider a recent project, wherein I worked to uncover factors that contribute most to employee satisfaction at our company. Our team guessed that patterns of employee satisfaction could be expressed as a decision tree. We selected a decision-tree algorithm and used it to produce a model (an actual tree), and error estimates based on observations of employee survey responses. We arrived at a model that predicted—as long as employees felt they were paid even moderately-well, had options to advance, and management that cared—they were likely to be happy.
The following figure illustrates this way of thinking, using concepts borrowed from David J. Saville and Graham R. Wood’s statistical triangle. The figure is a schematic representation that makes it easier to see how the logic of data science works.
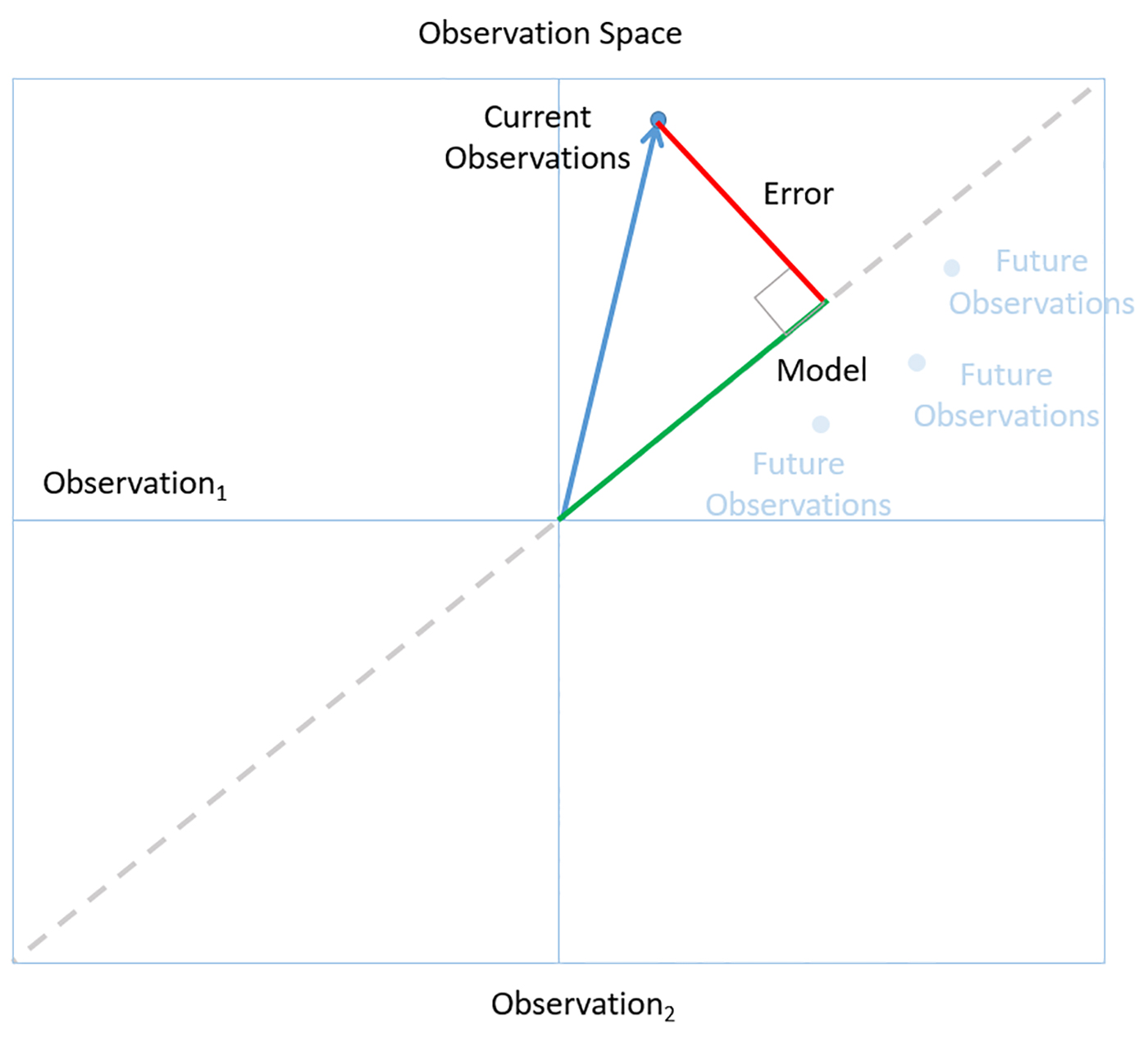
A point in the space represents a collection of independent observations. The dotted line shows the places in the space where the observations are all consistent. The best models are generic ones that can apply consistently across all observations (ones that lie along the dotted line). For example, in the employee satisfaction analysis, we generated a simple decision tree that could accurately classify a great majority of the employee responses we observed. The general model with the smallest error is also the model most likely to accurately predict future observations—the principle of Ockham’s Razor. This assumes, of course, that the observations are faithful representatives of the world at large.
Ultimately, the goal is to arrive at insights we can rely on to make high-quality decisions in the real world. We can tell if we have a model we can trust by following a simple rule of Bayesian reasoning: look for a level of fit between model and observation that is unlikely to occur just by chance. For example, the low P values for our employee satisfaction models told us that these results were probably significant. In observation space, this corresponds to small angles (which are less likely than larger ones) between the observation vector and the model.
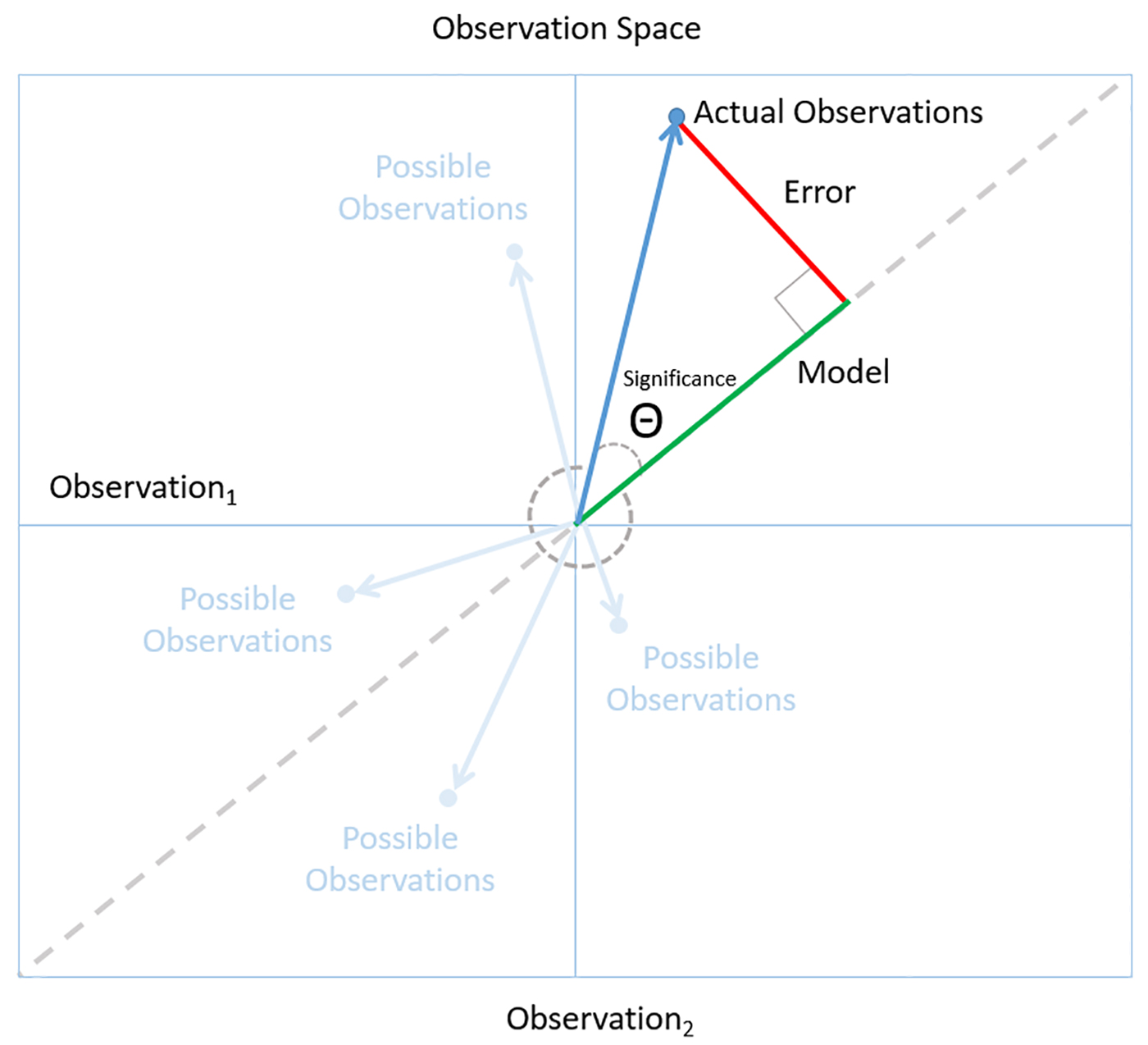
Treating data as evidence
The logic of data science tells us what it means to treat data as evidence. But following the evidence does not necessarily lead to a smooth increase or decrease in confidence in a model. Models in real-world data science change, and sometimes these changes can be dramatic. New observations can change the models you should consider. New evidence can change confidence in a model. As we collected new employee satisfaction responses, factors like specific job titles became less important, while factors like advancement opportunities became crucial. We stuck with the methods described in this blog, and as we collected more observations, our models became more stable and more reliable.
I believe that data science is the best technology we have for discovering business insights. At its best, data science is a competition of hypotheses about how a business really works. The logic of data science are the rules of the contest. For the practicing data scientist, simple rules like Ockham’s Razor and Bayesian reasoning are all you need to make high-quality, real-world decisions.