Interpretability via attentional and memory-based interfaces, using TensorFlow
A closer look at the reasoning inside your deep networks.
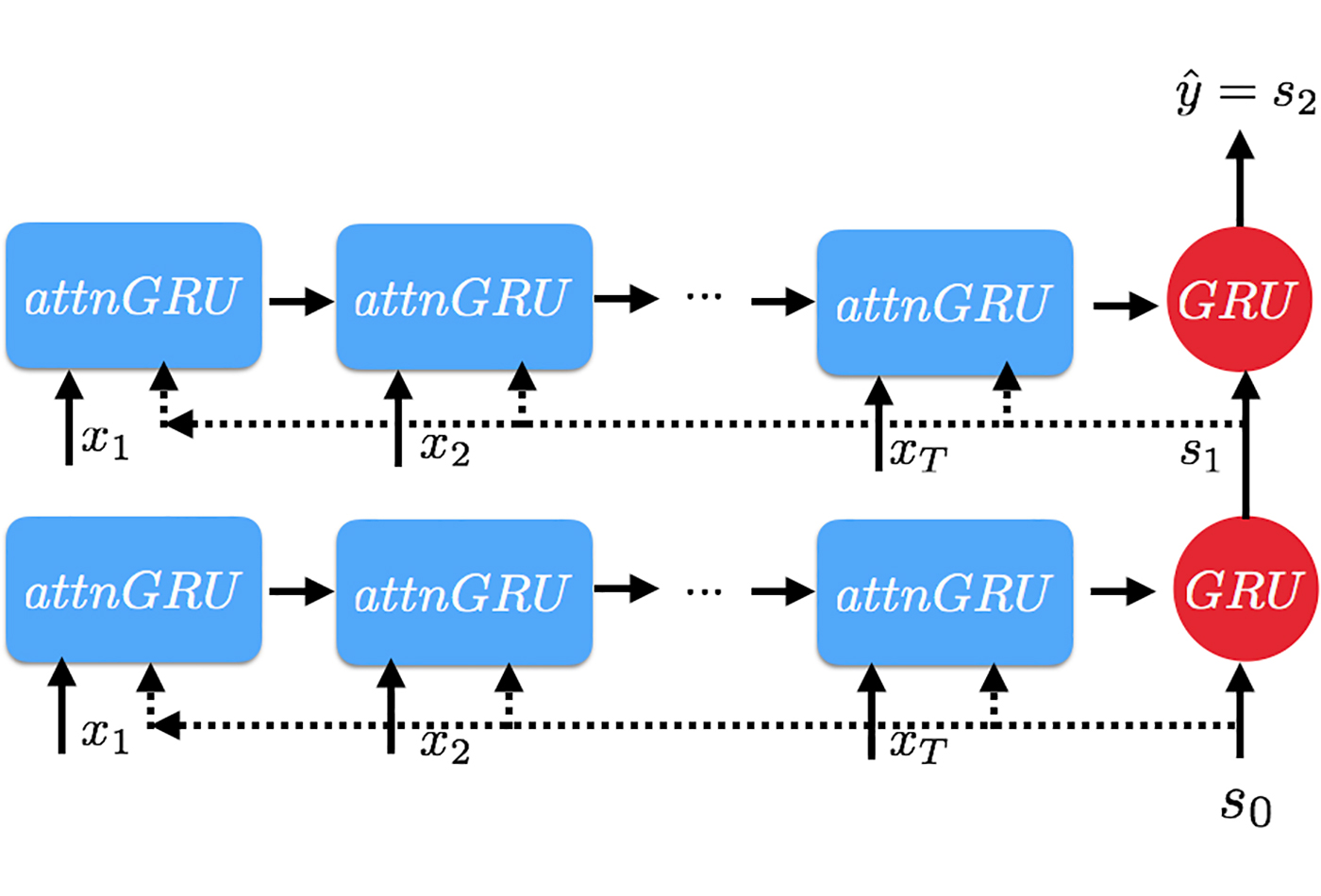 Attention GRU. (source: Goku Mohandas, used with permission.)
Attention GRU. (source: Goku Mohandas, used with permission.)
This article is a gentle introduction to attentional and memory-based interfaces in deep neural architectures, using TensorFlow. Incorporating attention mechanisms is very simple and can offer transparency and interpretability to our complex models. We conclude with extensions and caveats of the interfaces. As you read the article, please access all of the code on GitHub and view the IPython notebook here; all code is compatible with TensorFlow version 1.0. The intended audience for this notebook are developers and researchers who have some basic understanding of TensorFlow and fundamental deep learning concepts. Check out this post for a nice introduction to TensorFlow.
Applying selective attention to deep learning
Attentional interfaces in deep neural networks are loosely based on visual attention mechanisms, found in many animals. These mechanisms allow the organisms to dynamically focus on pertinent parts of a visual input and respond accordingly. This basic idea of selective attention has been carried over to deep learning, where it is being used in image analysis, translation, question/answering, speech, and a variety of other tasks.

Learn faster. Dig deeper. See farther.

These interfaces also offer much needed model interpretability, by allowing us to see which parts of the input are attended to at any point in time. A common disadvantage with deep neural architectures is the lack of interpretability and the associated “black box” stigma. Implementation of these interfaces has not only been shown to increase model performance, but also offer more transparent and sensible results. And as you will see in our implementation below, they produce some interesting visualizations that are consistent with how we would attend to the inputs.
Research on attentional interfaces is very popular these days because they offer multiple benefits. There are increasingly complex variants to the attention mechanisms, but the overall foundation remains the same.

In this article, we will take a look at the fundamental attentional interface, implement it with a small model, and then discuss some recent variants. We will be using attention in natural language understanding (NLU) tasks but will briefly explore other areas as well.
Overview of attentional interfaces
First, let’s take a closer look at the fundamental idea behind an attentional interface.
The attention model takes in j inputs (h1, h2, … hj), along with some information s{i-1} (memory), and outputs vector c, which is the summary of the hidden states focusing on the information s{i-1}. Before we see what goes on internally, it is important to point out there are a couple of different options for attention (i.e., soft, hard), but the type we will focus on will be completely differentiable (i.e., soft). This is because we want to be able to learn where to focus. This also means that we will be focusing everywhere at all times, but we will learn where to place more attention.
We can think of our s{i-1} as the generated context describing what we should focus on. We take the dot product of each input item within this context in order to produce a score. The scores (e from equations on Figure 3) are fed into a softmax to create our attention distribution. We multiply these normalized scores with our original inputs to receive a weighted summary vector for timestep/input i.
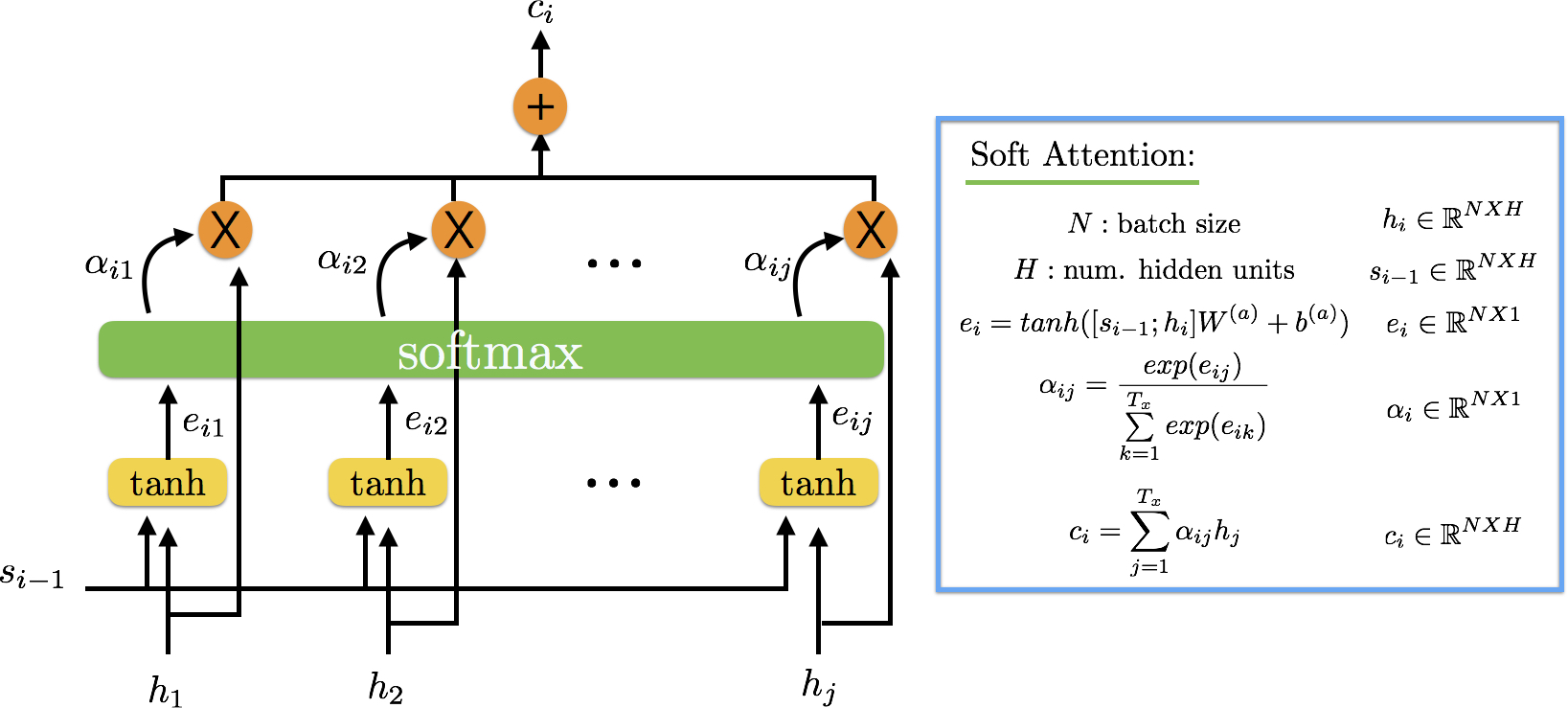
One of the main advantages of using an attentional interface is the opportunity to interpret and visualize the attention scores. We can see for each input where the model places more attention and how that impacts our final result. There are many ways to implement fully differential attentional interfaces, and the internal intricacies can differ. The example we have above is very commonly seen in neural translation models.
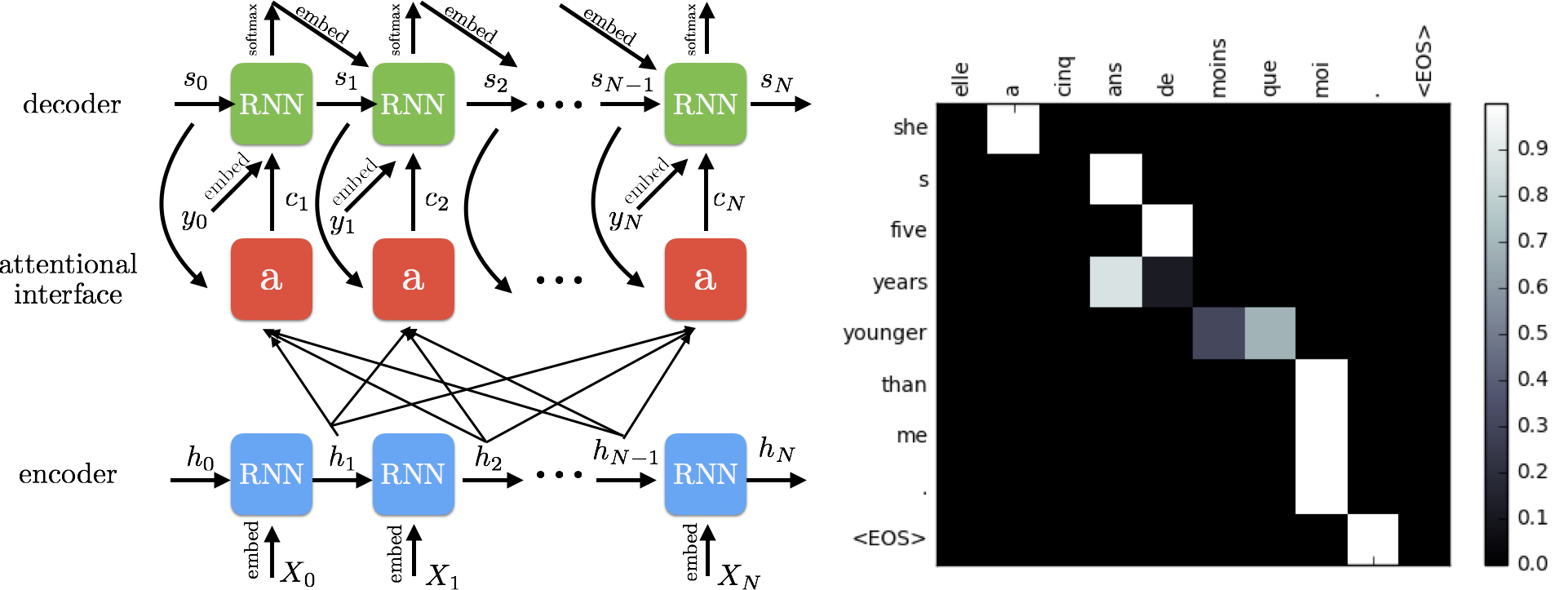
With translation, we don’t want just one summarizing vector using all of the inputs—we want a summarizing vector for each input. This is because translation is not always a one-to-one output. Words in one language may result in multiple words in another, so we need to attend to the entire sentence for all inputs, while using that context information so we know what we have seen so far.
We can go ahead and plot the attention scores for translation, and we will see something like Figure 4. Notice how some words, like “me,” very clearly only need to attend to one word. But other words, or groups of words, require attention across multiple words from the source language in order to translate properly.
Basic sentiment analysis and overview architecture
We will be using a sentiment analysis task in order to implement a basic attentional interface. This simple use case will be a nice introduction to how we can add attention to existing models for improved performance and interpretability.
We will be using the Large Movie Review data set, which contains 50,000 reviews that are split evenly into 25,000 train and 25,000 test sets. The data set includes text reviews with ratings from 0-9, but we will use ratings 0-4 as positive and 5-9 as negative sentiment. More specifics, including unlabeled data for unsupervised learning, and data collection details are provided in the readme file contained in the zipped data set.
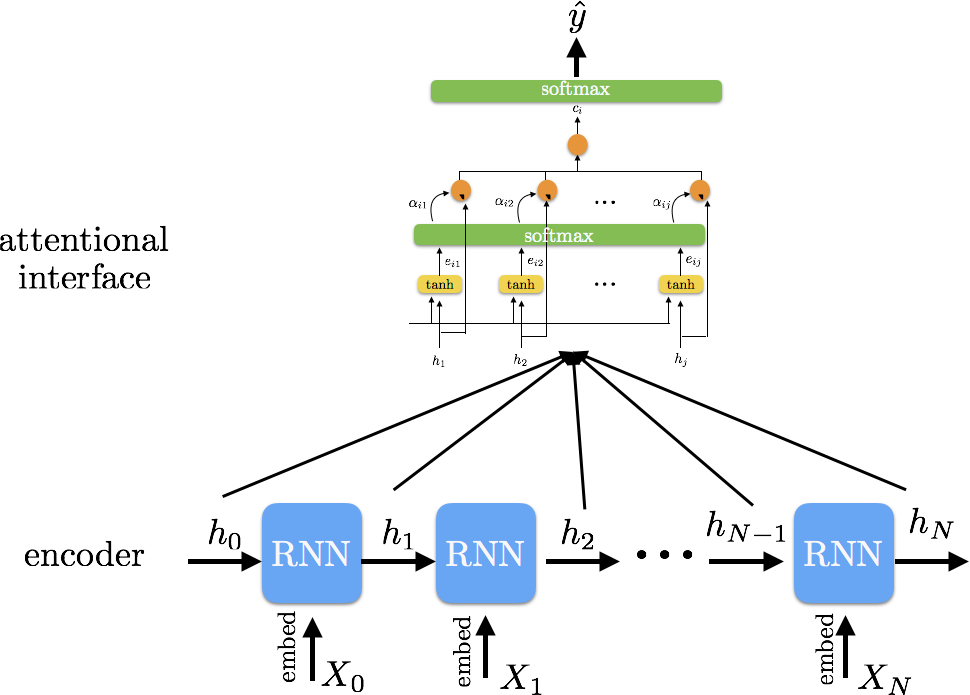
Here is the overview of the architecture, including the attentional interface. We will cover the details of preprocessing, the model, and the training procedure below. In Figure 5, you will notice how the attention layer is almost just like a pluggable interface. We could have just as easily taken the last (relevant) hidden state from the encoder and applied a nonlinearity, followed by normalization, to receive a predicted sentiment. Adding this attentional layer, however, gives us the chance to look inside the model and gain interpretability from the inferences.
Setup
We will fetch all the data (trained embeddings, processed reviews, and trained model) by executing the commands detailed in the iPython notebook for this article. We will be using preprocessed data, but for optimal inference performance, you could retrain the model from scratch, using all 25,000 training/test samples. The main focus of this article, however, is on attention mechanisms and how you can add them to your networks for increased interpretability.
Preprocessing components
In this section, we will preprocess our raw input data. The main components are the Vocab class, which we initialize using our vocab.txt file. This file contains all of the tokens (words) from our raw input, sorted by descending frequency. The next helper function we need is ids_to_tokens(), which will convert a list of ids into tokens we can understand. We will use this for reading our input and associating the word with its respective attention score.
Sample the data
Now, we will see what our inputs will look like. The processed_review represents our reviews with ids. The review_seq_len tells us how long the review is. Unless we use dynamic computation graphs, we need to feed in fixed-sized inputs into our TensorFlow models per batch. This means that we will have some padding (with PADs), and we do not want these to influence our model. In this implementation, the PADs do not prove to be too problematic, since inference will depend on the entire summarized context (so no loss masking is needed). And we also want to keep the PAD tokens, even when determining the attention scores, to show how the model learns not to focus on the PADs over time.
The model
We will start by talking about operation functions. _xavier_weight_init() is a little function we made to properly initialize our weights, depending on the nonlinearity that will be applied to them. The initialization is such that we will receive outputs with unit variance prior to sending to the activation function.
This is an optimization technique we use so we do not have large values when applying the nonlinearity, as that will lead to saturation at the extremes—and lead to gradient issues. We also have a helper function for layer normalization, ln(), which is another optimization technique that will normalize our inputs into the Gated Recurrent Unit (GRU) before applying the activation function. This will allow us to control gradient issues and even allow us to use larger learning rates. The layer normalization is applied in the custom_GRU() function prior to the sigmoid and tanh operations. The last helper function is add_dropout_and_layers(), which will add dropout to our recurrent outputs and will allow us to create multi-layered recurrent architectures.
Let’s briefly describe the model pipelines and see how our inputs undergo representation changes. First, we will initialize our placeholders, which will hold the reviews, lens, sentiment, embeddings, etc. Then we will build the encoder, which will take our input review and first embed using the GloVe embeddings. We will then feed the embedded tokens into a GRU in order to encode the input. We will use the output from each timestep in the GRU as our inputs to the attentional layer. Notice that we could have completely removed the attentional interface, and just used the last relevant hidden state from the encoder GRU in order to receive our predicted sentiment, but adding this attention layer allows us to see how the model processes the input review.
In the attentional layer, we apply a nonlinearity followed by another one in order to reduce our representation to one dimension. Now, we can normalize to compute our attention scores. These scores are then broadcasted and multiplied with the original inputs to receive our summarized vector. We use this vector to receive our predicted sentiment via normalization in the decoder. Notice that we do not use a previous state (s{i-1}) since the task involves creating just one context and extracting the sentiment from that.
We then define our loss as the cross entropy between the predicted and the ground truth sentiment. We use a bit of decay for our learning rate with an absolute minimum and use the ADAM optimizer. With all of these components, we have built our graph.
Attention visualization to predict sentiment
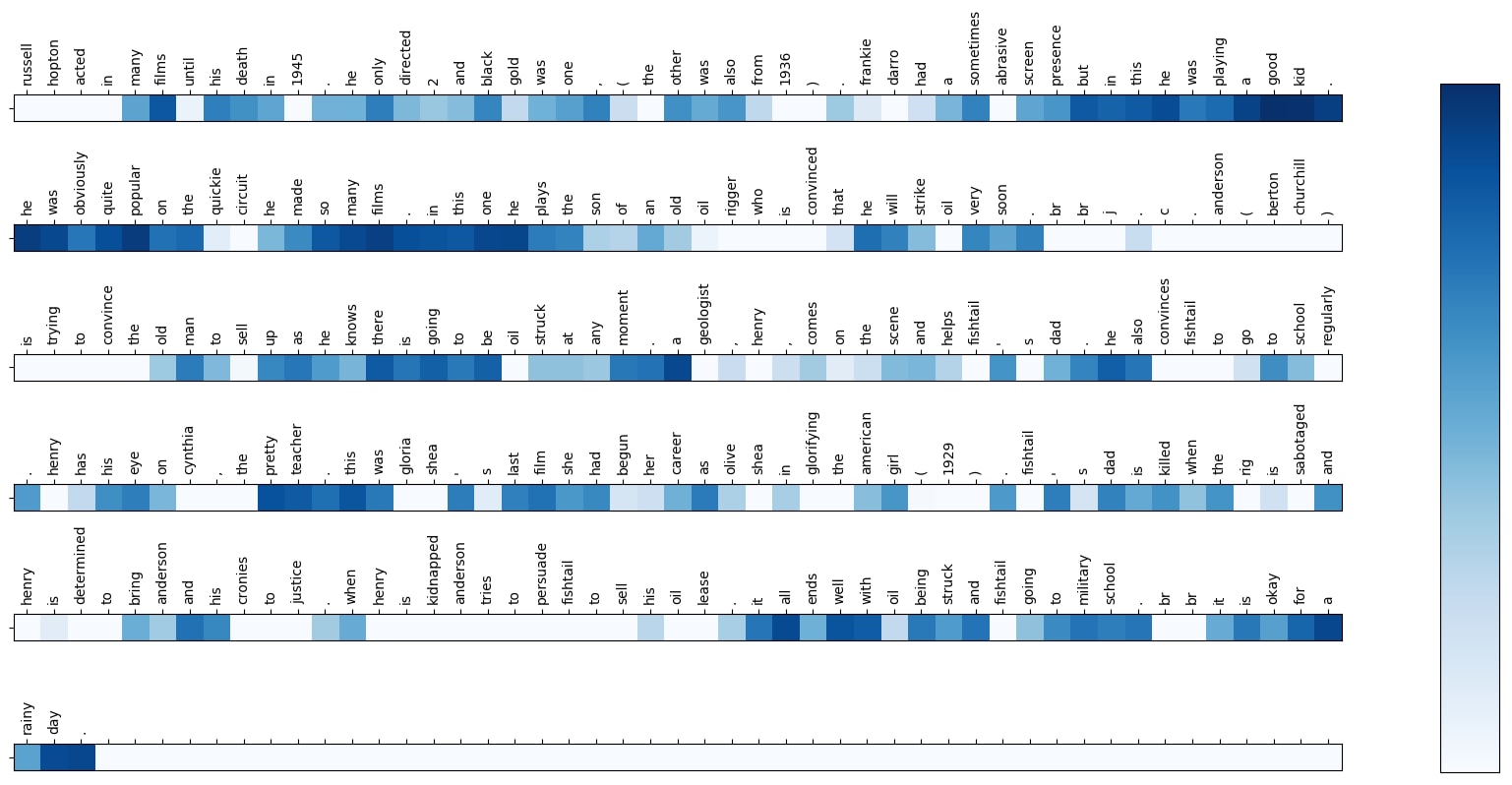
You can see how the model starts with equal attention distribution to all words, and then starts to learn which words are important in order to predict the sentiment. The darker the color, the stronger that particular word is attended to. The first sanity check is that the PAD tokens receive almost no attention; then, we start to see focus on really strong/influential words. Check out a few of the other reviews as well and you will see that almost always, there is quite a bit of attention at the ends of reviews, which is where people give a concluding statement that summarizes their sentiment succinctly.
We used the sentiment analysis task in order to see how simple it is to add an attentional interface to a model. Though we were able to receive some meaningful attention scores for this task, it is not a trivial task to interpret, even with attention. Most reviews (discarding the extremes) will usually talk about the plot for most of the review, so it is interesting that we can use attention to pick up on the brief moments of sentiment. An interesting extension of this implementation would be to only use the extreme reviews, where there is a spew of emotion throughout the review.
Attentional interface variants
Our implementation of the soft attentional interface is one of the basic forms of attention, and we can already start to see some interpretability. This is currently a very active area of research where there are developments in different types of tasks using attention (VQA, translation, etc.), different types of attention, and better attentional interface architecture.
So far, we have seen how attentional processing can be specialized to the task. With the translation task, the attentional interface is applied to each input word and a summarized context is made for each time step. This is because translation is not always a one-to-one task and a word may depend on several words in the target language for the correct translation. However, for our sentiment analysis implementation, it wouldn’t make sense to have a summarizing vector for each input because our output is a binary sentiment. Similarly, there are also processing variants for tasks, such as question and answering (i.e., pointer-based attention to specific spans in the input) and image-based attention (i.e., focusing on different parts of the represented image).
We can also have variants to the architecture of the interface as well. This too is a large, open field of research, and we may cover some of the interesting variants in future articles. Here, we’ll introduce one of the architecture variants that is relevant to our sentiment analysis, or any natural language understanding task.
In the attentional interface we implemented, you may notice that we completely disregard the order of the input review. We process all of the words in the review, but when we read a review and try to determine the sentiment, it is important to have context for what we have already read. A small tweak in the attentional interface can help us overcome this issue.
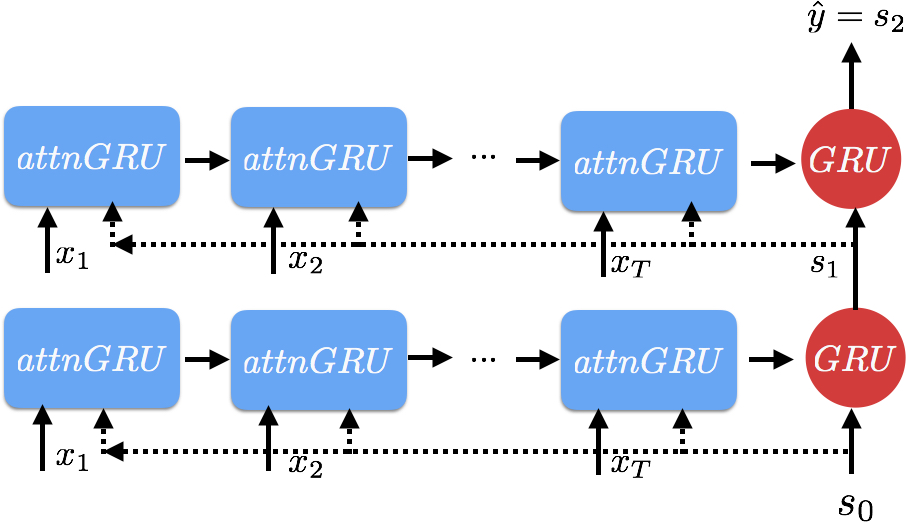
In order to incorporate order of the input into our attentional interface, all we have to do is, first, compute the attention scores for each token in the input. Then, we feed in one token at a time, with the scalar (or vector) attention score in place of the update gate in the GRU. We do this for all tokens in the input and we take the final (relevant output) or all of the outputs—which, of course, depends on our task and model architecture. This tweak allows us to incorporate the order of the input, along attentional scores, giving us both interpretability and a logical architecture.
Caveats
As you may notice, this increased interpretability does come with an increased computation cost. This can be a major factor when using these models for production systems, so it is really important to understand the types of tasks in which these interfaces prove to be really valuable. For the tasks we talked about here, adding these interfaces allows us to overcome the information and interpretability bottlenecks. For the specific task of binary sentiment analysis, we can get similar performance with just a bag-of-words model, but the model ultimately depends on the performance you are looking for and the computational constraints.
Interpretability and why it’s important
As we start to develop increasingly deeper models, it will be important to maintain a high level of interpretability. This becomes more valuable as AI starts to have a greater impact on our everyday lives and we start integrating it everywhere. Attentional interfaces are just the beginning for this field in terms of having transparent models, and we need to keep pushing for increased interpretability.
This post is a collaboration between O’Reilly and TensorFlow. See our statement of editorial independence.