
 Kaleidoscope (source: Pixabay)
Kaleidoscope (source: Pixabay) Although machine learning (ML) can produce fantastic results, using it in practice is complex. Beyond the usual challenges in software development, machine learning developers face new challenges, including experiment management (tracking which parameters, code, and data went into a result); reproducibility (running the same code and environment later); model deployment into production; and governance (auditing models and data used throughout an organization). These workflow challenges around the ML lifecycle are often the top obstacle to using ML in production and scaling it up within an organization.
To address these challenges, many companies are starting to build internal ML platforms that can automate some of these steps. In a typical ML platform, a dedicated engineering team builds a suite of algorithms and management tools that data scientists can invoke. For example, Uber and Facebook have built Michelangelo and FBLearner Flow to manage data preparation, model training, and deployment. However, even these internal platforms are limited: typical ML platforms only support a small set of algorithms or libraries with limited customization (whatever the engineering team builds), and are tied to each company’s infrastructure.
At Spark+AI Summit 2018, my team at Databricks introduced MLflow, a new open source project to build an open ML platform. Beyond being open source, MLflow is also “open” in the sense that anyone in the organization—or in the open source community—can add new functionality, such as a training algorithm or a deployment tool, that automatically works with the rest of MLflow. MLflow offers a powerful way to simplify and scale up ML development throughout an organization by making it easy to track, reproduce, manage, and deploy models. In this post, I’ll give a short overview of the challenges MLflow tackles and a primer on how to get started.
Machine learning workflow challenges
At Databricks, we work with hundreds of companies using ML in production. Across these companies, we have repeatedly heard the same set of concerns around ML:
- There are a myriad of disjointed tools. Hundreds of software tools cover each phase of the ML lifecycle, from data preparation to model training. Moreover, unlike traditional software development, where teams select one tool for each phase, in ML you usually want to try every available tool (e.g., algorithm) to see whether it improves results. ML developers thus need to use and productionize dozens of libraries.
- It’s hard to track experiments. Machine learning algorithms have dozens of configurable parameters, and whether you work alone or on a team, it is difficult to track which parameters, code, and data went into each experiment to produce a model.
- It’s hard to reproduce results. Without detailed tracking, teams often have trouble getting the same code to work again. Whether you are a data scientist passing your training code to an engineer for use in production, or you are going back to your past work to debug a problem, reproducing steps of the ML workflow is critical. We’ve heard multiple horror stories where the production version of a model did not behave like the training one, or where one team couldn’t reproduce another team’s result.
- It’s hard to deploy ML. Moving a model to production can be challenging due to the plethora of deployment tools and environments it needs to run in (e.g., REST serving, batch inference, or mobile apps). There is no standard way to move models from any library to any of these tools, creating a new risk with each new deployment.
MLflow: An open machine learning platform
MLflow is designed to tackle these workflow challenges through a set of APIs and tools that you can use with any existing ML library and codebase. In the current alpha release, MLflow offers three main components:
- MLflow Tracking: an API and UI for recording data about experiments, including parameters, code versions, evaluation metrics, and output files used.
- MLflow Projects: a code packaging format for reproducible runs. By packaging your code in an MLflow Project, you can specify its dependencies and enable any other user to run it again later and reliably reproduce results.
- MLflow Models: a simple model packaging format that lets you deploy models to many tools. For example, if you can wrap your model as a Python function, MLflow Models can deploy it to Docker or Azure ML for serving, Apache Spark for batch scoring, and more.
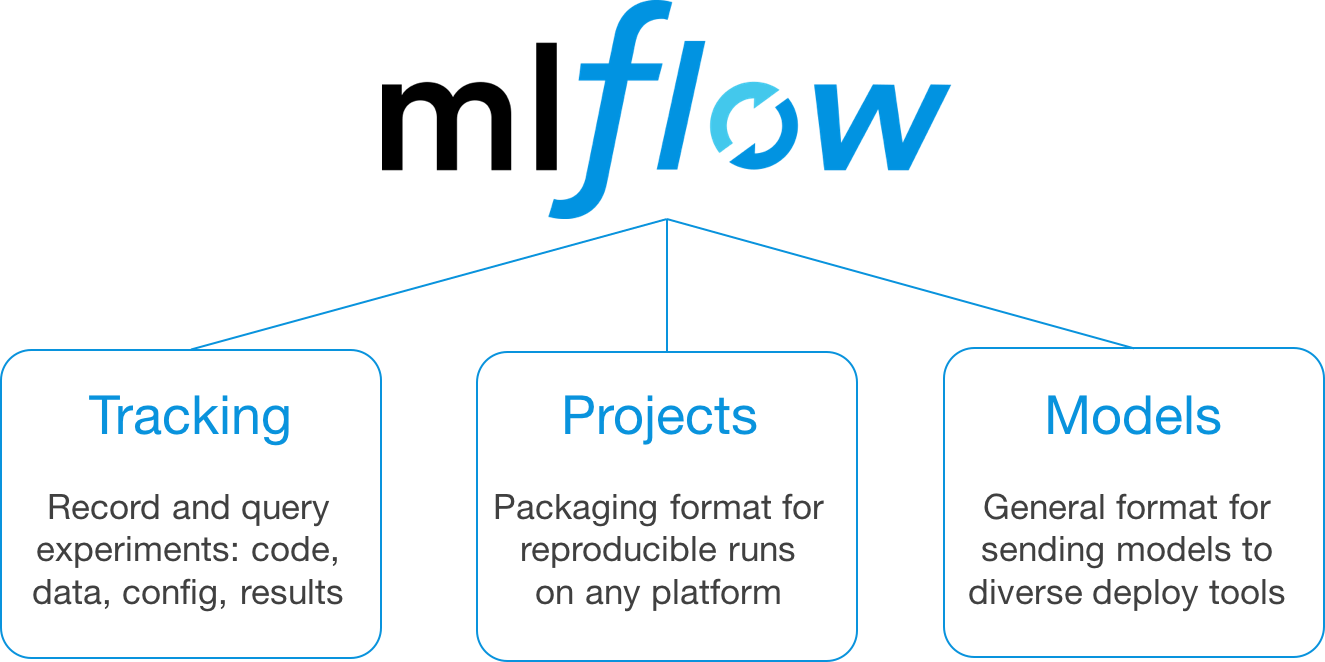
MLflow is designed to be modular, so you can use each of these components on their own in your existing ML process or combine them. Let’s dive into each of these components in turn to see how to use them and how they simplify ML development.
Getting started with MLflow
MLflow is open source and easy to install using pip install mlflow. To get started with MLflow, follow the instructions in the MLflow documentation or view the code on GitHub.
MLflow Tracking
MLflow Tracking is an API and UI for logging parameters, code versions, metrics, and output files when running your ML code to later visualize them. With a few simple lines of code, you can track parameters, metrics, and “artifacts” (arbitrary output files you want to store):
import mlflow
# Log parameters (key-value pairs)
mlflow.log_param("num_dimensions", 8)
mlflow.log_param("regularization", 0.1)
# Log a metric; metrics can also be updated throughout the run
mlflow.log_metric("accuracy", model.accuracy)
# Log artifacts (output files)
mlflow.log_artifact("roc.png")
mlflow.log_artifact("model.pkl")
You can use MLflow Tracking in any environment where you can run code (for example, a standalone script or a notebook) to log results to local files or to a server, then compare multiple runs. Using the web UI, you can view and compare the output of multiple runs:
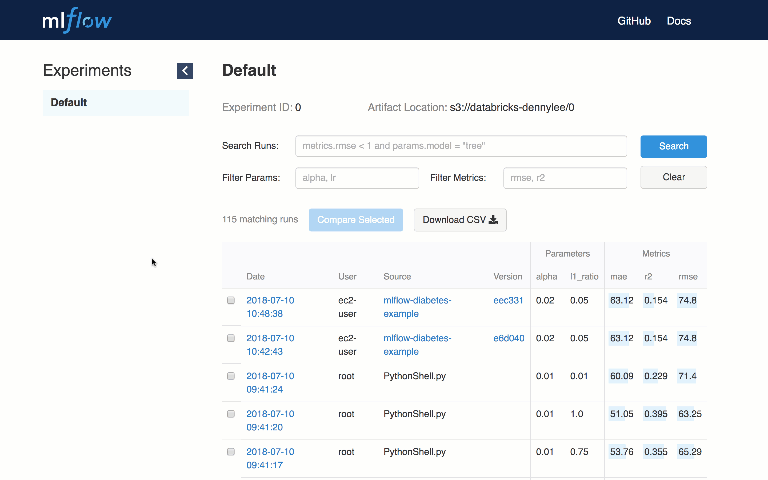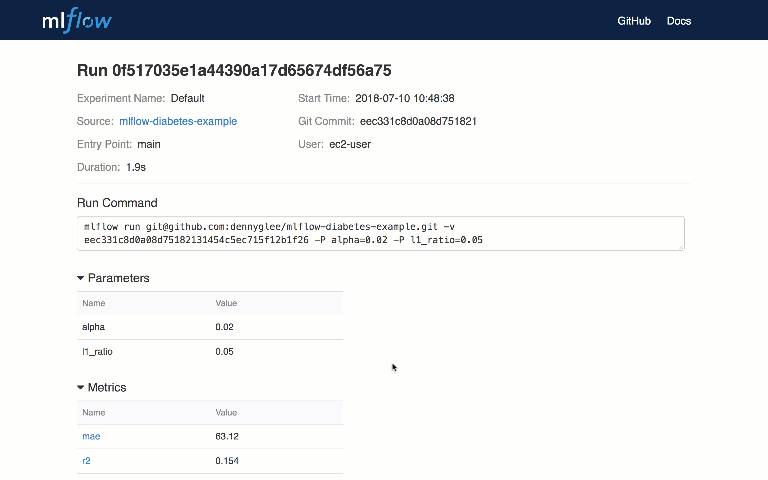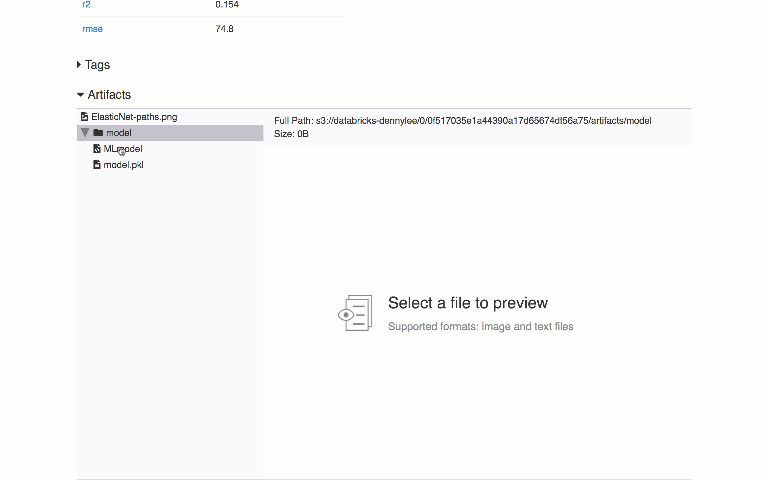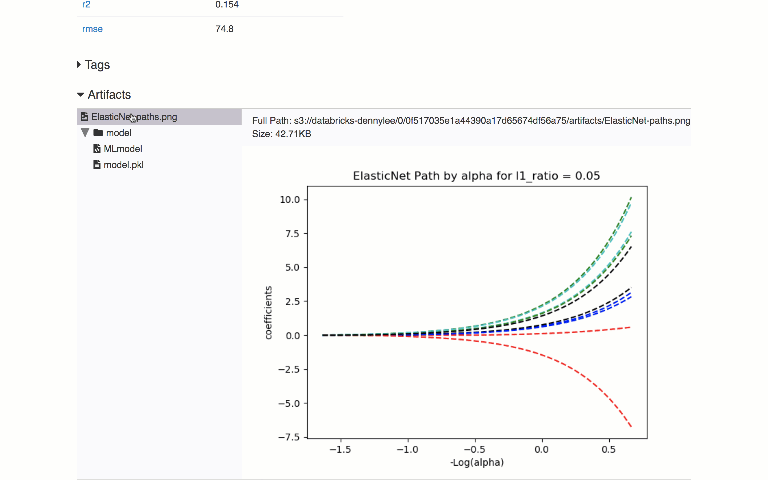
MLflow Projects
Tracking results is useful, but you often need to reproduce them as well. MLflow Projects provide a standard format for packaging reusable data science code. Each project is simply a directory with code or a Git repository, and uses a descriptor file to specify its dependencies and how to run the code. An MLflow Project is defined by a simple YAML file called MLproject.
name: My Project
conda_env: conda.yaml
entry_points:
main:
parameters:
data_file: path
regularization: {type: float, default: 0.1}
command: "python train.py -r {regularization} {data_file}"
validate:
parameters:
data_file: path
command: "python validate.py {data_file}"
Projects can specify their dependencies through a Conda environment. A project may also have multiple entry points for invoking runs, with named parameters. You can run projects using the mlflow run command-line tool, either from local files or from a Git repository:
mlflow run example/project -P alpha=0.5 mlflow run git@github.com:databricks/mlflow-example.git -P alpha=0.5
MLflow will automatically set up the right environment for the project and run it. In addition, if you use the MLflow Tracking API in a Project, MLflow will remember the project version executed (that is, the Git commit) and any parameters. You can then easily rerun the exact same code. The project format thus makes it easy to share reproducible data science code, whether within your company or in the open source community.
MLflow Models
MLflow’s third component is MLflow Models, a simple but powerful way to package models. While many model storage formats (such as ONNX and PMML) already exist, MLflow Models’ goal is different: the goal is to represent how the model should be invoked, so that many different types of downstream deployment tools can use it. To do this, MLflow Models can store a model in multiple formats called “flavors.” These flavors can be library-specific (such as a TensorFlow graph) but can also be very generic flavors like “Python function,” which any deployment tool that understands Python can use.
Each MLflow Model is simply saved as a directory containing arbitrary files and an MLmodel YAML file that lists the flavors it can be used in. Here is a sample model exported from SciKit-Learn:
time_created: 2018-02-21T13:21:34.12
flavors:
sklearn:
sklearn_version: 0.19.1
pickled_model: model.pkl
python_function:
loader_module: mlflow.sklearn
pickled_model: model.pkl
MLflow provides tools to deploy many common model types to diverse platforms. For example, any model supporting the python_function flavor can be deployed to a Docker-based REST server, to cloud serving platforms such as Azure ML and AWS SageMaker, and as a user-defined function in Spark SQL for batch and streaming inference. If you output MLflow Models as artifacts using the MLflow Tracking API, MLflow will also automatically remember which Project and run they came from so you can reproduce them later.
Putting these tools together
While the individual components of MLflow are simple, you can combine them in powerful ways whether you work on ML alone or in a large team. For example, you can use MLflow to:
- Record and visualize code, data, parameters, and metrics as you develop a model on your laptop.
- Package code as MLflow Projects to run them at scale in a cloud environment for hyperparameter search.
- Build a leaderboard to compare performance of different models for the same task inside your team.
- Share algorithms, featurization steps, and models as MLflow Projects or Models that other users in the organization can combine into a workflow.
- Deploy the same model to batch and real-time scoring without rewriting it for two tools.
What’s next?
We are just getting started with MLflow, so there is a lot more to come. Apart from updates to the project, we plan to introduce major new components (such as monitoring), library integrations, and language bindings. Just a few weeks ago, for example, we released MLflow 0.2 with built-in TensorFlow support and several other new features.
We’re excited to see what you can do with MLflow, and we would love to hear your feedback.
Related resources:
- “Lessons learned turning machine learning models into real products and services”
- “Managing risk in machine learning models”: Andrew Burt and Steven Touw on how companies can manage models they cannot fully explain
- “What are machine learning engineers?”: examining a new role focused on creating data products and making data science work in production
- “We need to build machine learning tools to augment machine learning engineers”
- When models go rogue: David Talby on hard-earned lessons about using machine learning in production