Music science
How data and digital content are changing music.
 Photo of CDs
Photo of CDs
Music Science Today
Today, technology is an essential part of the music industry:
- Recommendation engines suggest tracks or artists we might like.
- Streaming technology replaces music ownership with service subscriptions.
- Accounting platforms collect billions of playbacks a day, funneling money to the many people involved in a track.
- Content-detection tools ferret out copyright violations and compensate artists when their works are used by others.
- Analytics helps the industry detect breakout successes early on and double-down on marketing investment.
Nearly every aspect of the modern music industry relies on big data, machine learning, and analytics to make better decisions faster. At the intersection of digital content and powerful analytics lies a new discipline, one that Saavn CEO Rishi Malhotra and others call “Music Science.”

Learn faster. Dig deeper. See farther.
Music Science is a relatively new field, blending analytics, accounting, psychology, neuroscience, machine learning, and prediction. It’s staffed by data scientists, analytics experts, tastemakers, economists, and even game theorists. And it’s a multibillion-dollar industry.
Music scientists analyze tracks, fans, and artists. Every interaction is a breadcrumb for producers; every upload a potential source of revenue in a Byzantine labyrinth of rights and permissions.
Music science is fascinating in its own right, in part because music is present in everyone’s lives, transcending culture and age. But it’s also useful as a canary in the big data coal mine, because working with music data provides a test case for what may happen with analytics in other industries. Music data is sprawling, intensely personal, widely shared, changes with time and place, and underlies a vast range of business models.
In this report, you’ll not only see where music science stands today—and where it’s headed—but you’ll get a glimpse of what other industries, and perhaps human society, will look like in coming years.
This report is a result of 6 months’ study and over 70 interviews with scientists, founders, and artists, all of whom were generous with their time and insights. It also only scratches the surface of this fascinating industry.
How We Got Here: Arbitron and the First Age of Analytics
The move to digital content and connected fans may be one of the most significant shifts in the history of music, but it certainly isn’t the only one. The music business is both music and business, which means that a goal of the industry is to make money. Since the first musician wrote down a song so that others could play it, the reproduction of music—and the separation of creation from performance—has been at odds with getting money to its creators or owners. It’s this drive to better link music to business that produced one of the first attempts to quantify music with data: deciding what radio was worth.
Getting Smarter (and More Accurate) with Devices
All of this changed in 2007, when, amidst protest and controversy, Arbitron rolled out its Personal People Meter (PPM). The PPM was a pager-sized listening device worn on the belt that listened for a specific tone—inaudible to humans—that uniquely identified each radio station. No more approximation; no more gaming the panelists’ memories; no more estimation. Listening data was finally accurate.
The PPM had immediate consequences. If a panelist walked into a mall playing Country music, Arbitron knew about it, and credited that station. The information was available sooner, even daily, making programming more responsive to listener behavior. Perhaps most importantly, if a panelist changed channels when a certain song came on, Arbitron knew that, too.
With the introduction of the PPM, big stations found that their old tricks didn’t work any more. Ratings declined for the many stations that had previously enjoyed greater mindshare—sometimes by 30% or more. Listeners were less loyal than they’d thought. Real-time, accurate data redistributed the power, and the money, of broadcast radio.
Gaming the System, Again
Radio is thriving today, but it’s doing so in a race to the lowest common denominator. Whereas in the golden age of wireless a song in “heavy rotation” was played every four hours by mainstream stations, today that song is played as often as every 55 minutes. That’s because the head of programming knows that when listeners hear a popular song they stick around for a couple more, and they only listen in short chunks.
DJs behave differently, too, spending less time announcing and branding the station because they don’t need listeners to remember the radio’s call sign—the PPM already knows. Songs that lose listeners get pulled faster. Arbitron’s new 360 PPM collects data in real time, and doesn’t require a phone line to sync—leading to a strange sort of constant feedback loop, programming what’s on based on the whims of the panel.
More than anything, the PPM is an object lesson in what happens when data is accurate. When a business model runs headlong into the truth, the rules change. When data is collected in real time, the rules change even faster. The ease with which we can collect user data is astonishing, and as each industry replaces surveys, panels, and experts with actual analysis and social data, Old Gods die remarkably quickly.
What’s the Moral of the Story?
The story of how we measure listening behavior isn’t just an interesting case study—it’s a harbinger of what’s about to happen in nearly every industry. The devices in our pockets—well over 1.5 billion smartphones—aren’t just connectors, they’re tracking tools. Even so-called dumb phones, which nearly outnumber humans, offer a treasure trove of raw data.
Today, you don’t need to survey a sample of people to understand what a market is thinking—you can just watch the market. And often, what that market does is very different from what survey respondents had told you in the past.
From Artist to Ear: The New Supply Chain
Although still alive and kicking, gone are the days when radio reigned supreme. The number of paths a song might take from an artist to a fan has exploded in recent years thanks to the proliferation of tools for creating, mastering, promoting, sharing, identifying, streaming, and purchasing music.
Traditionally, a musician would press an album, then use a publisher to get it in front of tastemakers in the hope that it would gather fans. But today, artists can upload music directly to hosted music services like Soundcloud, Mixcloud, and YouTube. There are also myriad upload services—CDBaby, DistroKid, Ditto, Zimbalam, Loudr, and Tunecore—that push a track to many online channels. There are also artist-run sites like Bandcamp and Bandzoogle, and crowd-backed platforms where artists can pre-sell their work.
Songs spread around the world via this new mix of services. As Shazam’s Head of Product, Cait O’Rearden, explains:
We worked on a case study on Mr. Probz, a Dutch artist who went from Holland to the US; and one study on Meghan Traynor, who went from the US to Europe. By sharing data [between Spotify and Shazam] we could see really interesting things, and then Will Page [director of economics at Spotify] laid on radio spins.1
The study showed that in the home country of the artist, all the Shazams went first, then the Spotify went second. But the track went to the US by playlisting, and then it showed up on Shazam, and then radio followed way afterwards.
“Playlisting” is an entirely new term for music discovery that didn’t really exist a decade ago. Today, playlists—created by machines, curated by humans—are one of the dominant ways that music spreads, having replaced radio stations, promoters, record stores, and albums.
In this new age of music consumption, attention becomes a huge problem. The sheer volume and variety of options makes finding new music that fits an individual’s tastes daunting. O’Rearden continues:
That’s a very new phenomenon of digital services actually moving a track around the world without radio airplay. That’s the sort of thing we’re looking at in terms of discovery. But the huge panoply of choice has made it so that it’s never been harder to find something to listen to.
Music analytics firm Next Big Sound, now part of Pandora, knows how attention spreads. Their technology tracks the rise of an artist from their first, lonely tweets through to their ascent on the Billboard charts. The company amasses data about music plays, social mentions, artist interactions, and song purchases into time-series data, such as the one in Figure 1-1.
“It always seemed like such a black box from a band playing in their garage to headlining a nationwide tour,” says Next Big Sound co-founder Alex White, who has a background in A&R for the music industry. “Nothing happens out of nowhere; what are the steps along the way? One of the things I’m most proud of is the time-series graphs we’re able to show.”
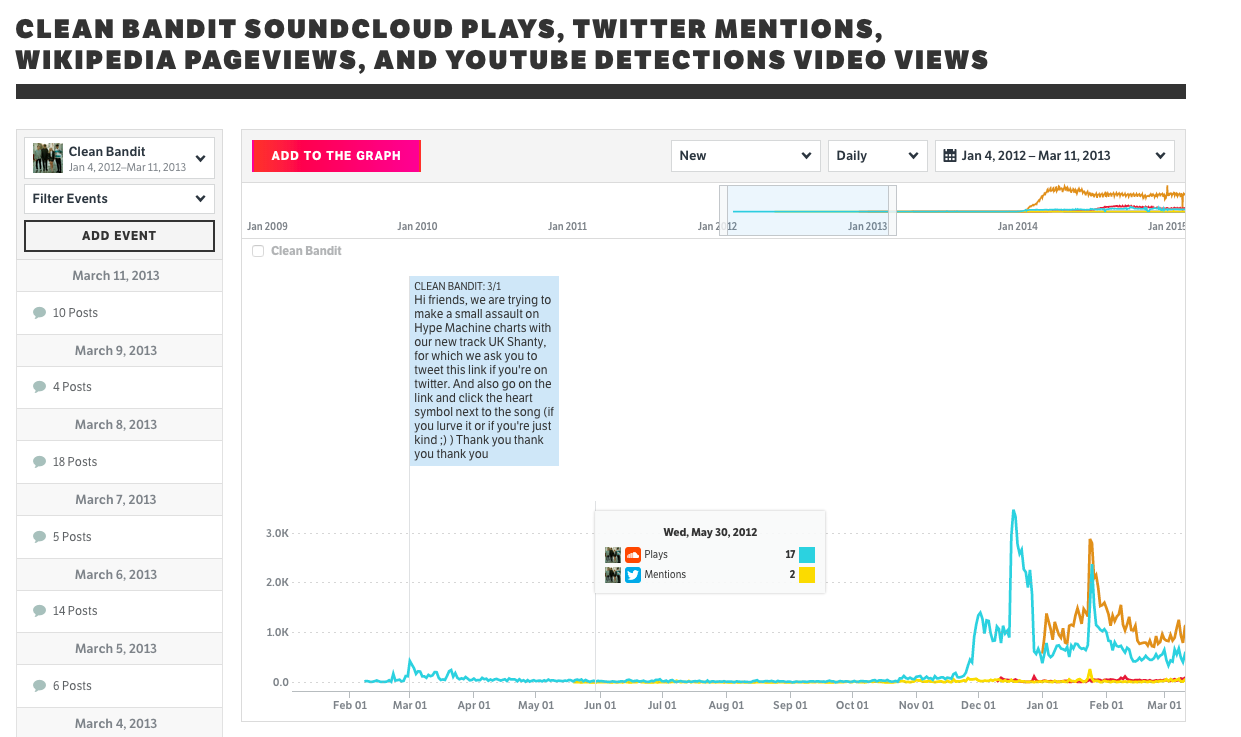
Historically, the end of this path would be a purchase by a fan in either digital or physical format. But with more people consuming music-as-a-service, that purchase may never happen. For today’s artist, the end game is loyalty—a fan that will buy tickets, merchandise, and future songs; share with friends; and even help back new artistic endeavors through crowdfunding.
The Rise of Metadata
One of the reasons music is such a ripe area for analytics is the sheer volume of data associated with a song.
There’s the track itself, which can be analyzed in a number of ways—size, duration, bitrate, key, energy level, beats per minute, even the number of times the soundwave crosses the zero-amplitude line. A number of powerful open source tools, such as Seewave, have made sound analysis easier to implement in recent years.
There’s the medium in which the track was recorded. CD and digital media are by far the most popular, but other source material, from vinyl and cassette to more esoteric formats, is all part of the metadata that can be stored with a track.
There’s how the track was made—who composed it, who performed on it, what instruments were used, what the lyrics are.
There’s how the track fits into the rest of the music landscape. This is most interesting as a set of relationships—which studio musician played drums on a particular track, for example. Music database service Musicbrainz maintains a detailed list of relationships.
Navigating these relationships can be complicated, but fortunately the abundance of data in digital music spawned many attempts to make sense of it all. From Ishkur’s Guide to Electronic Music to more machine-generated maps (such as Liveplasma and Music Map) to hundreds of non-commercial projects, visualization and mapping were some of the first applications to feed on the abundance of digital data. Many of the mapping tools developed for music apply well to other domains, such as graph database visualization.
Much of this information was available before digital music, though it took too much effort to collect. Technology has changed that. CDDB, Musicbrainz, and others work because they crowdsource the task of tagging music across listeners. Now that music is digital, fans can analyze the sounds as easily as producers, and the vanishingly cheap cost of storage means it can be shared with the world.
What is new, however, is engagement metadata. Before connected listening, most information was about production and sales. There was very little insight into consumption beyond panels and focus groups. Now we can find out what happens to tracks after they’re released.
One example of this is Soundcloud, which started as a way for people to comment on a song, on a visualization of the song’s waveform (Figure 1-2).
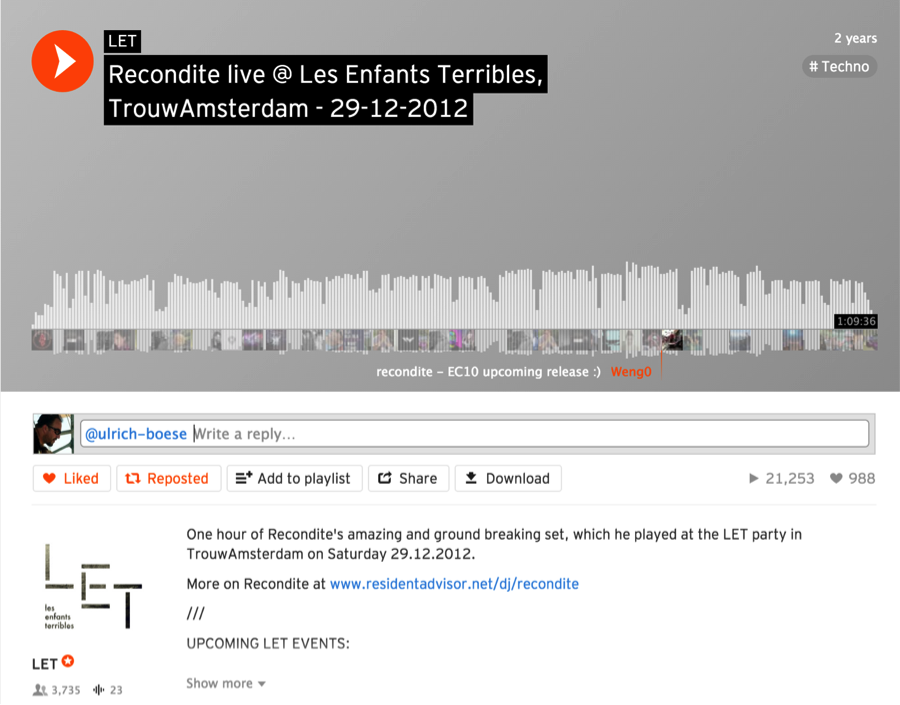
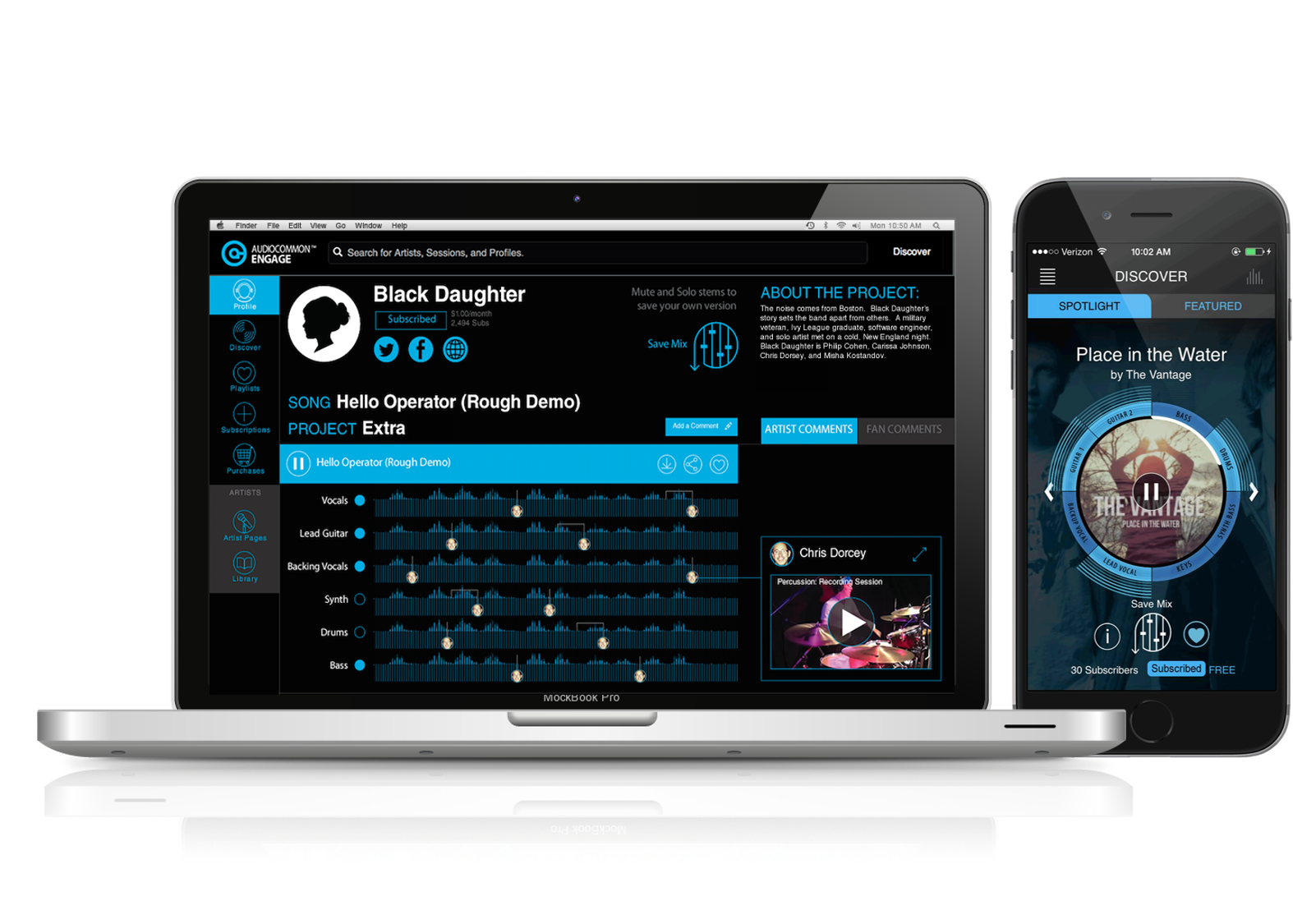
These conversations can be threaded, and make music social; artists can see what fans like about their music, or discuss it with collaborators. Services track every action, like, play, skip, and download, yielding additional insight into how the song is performing in the wild. Startups like Audiocommon (whose interface is shown in Figure 1-3) and Splice take this farther, breaking a track up into component parts and individual instruments, inviting comment, remix, or even re-use.
A Matter of Taste: Recommendations
One of the main uses of music metadata is to make recommendations. Listeners want music they like, and expect a balance of familiarity and novelty from their services. Consider that streaming music platform Deezer lists 35 million tracks in its catalog, with an average length of 3.5 minutes per track. According to the UK’s Entertainment Retailers’ Association, roughly 25% of Deezer’s staff works on song selection and recommendation. And those people get help from computers.
Rishi Malhotra at Saavn says that when it comes to programming music, “you need machine and programmatic algorithms to scale; and you need humans to make it real. As an example: it’s Friday in Los Angeles, 5PM, and it’s pouring rain. Programmatic tells you, ‘Friday, LA, 5PM, play California Girls by David Lee Roth.’ But the human DJ says, ‘it’s Coldplay time right now.’”
Get those recommendations wrong, Malhotra says, and things go badly:
Consumers get their new music product and the first thing they do is fill it up with the stuff that they know. I want my Bob Marley, my Coldplay, my Miles Davis. And that’s the Honeymoon period, and after some time it sort of begins to tail off and you want non-interactive programming to work.
And the thing about non-interactive is that it’s very much a data backbone, but in order to do non-interactive very well you have to have native algorithms and native data. People think that non-interactive is about the first song; but they’re wrong. Because it’s about the second song. The first song, you already told me you want Miles Davis. So if I get that wrong I’m pretty much dead in the water. But it’s really the second song that has to have that sort of vibe to it, and that serendipity that makes you go, ‘OK, cool, this thing gets it,’ and people will begin to invest more to get it better. You get a second song wrong, you won’t get that user back.
When you get the second song wrong, you see it right away. You get algorithm right and you’ll start getting session length that compounds. Right now we do about 44 minutes per session on Saavn, which is a high number; higher than YouTube and Facebook in India. It’s about 5–7 hours a month depending on the platform. But you start getting second song wrong, you’ll start seeing engagement drop, and then you’ll see clicks on the app move up, because people are tapping around, or they’ll back out. So you’ll actually be losing [daily active users], and ultimately [monthly active users]. Until the algorithm is right, we wouldn’t launch a station—because if I acquire somebody for pennies it’s going to take me dollars to get them back.
The Music Genome
When it comes to making music recommendations, genres—while subjective—were historically the best way to quickly find similar music. Pandora grew from an attempt to create a better music taxonomy known as the Music Genome Project, and created several patents around the taxonomy and recommendation of music. The taxonomy includes over 400 distinct musical attributes, from broad concepts like rhythm, instrumentation, and song structure to specific elements such as the gender of the vocalist or the level of distortion in guitars.2
The exact makeup of the Music Genome Project is a trade secret. Early on, the company employed trained musicologists who analyzed each song, sometimes asking multiple reviewers to weigh in to ensure consistency. But since that time, Pandora’s Director of Research Oscar Celma says the company relies more on machine learning and software algorithms in order to scale its analysis:
Since 2000, we’ve had 25 music experts analyzing music, and we have almost 2 million songs analyzed manually and rated. This really helps us.
A couple of years ago, we [formed] a team I lead called the Machine Listening team. What we do is use all the information we have manually as a sort of ‘gold standard.’ We have over 400 attributes for different types of music. This means that with a very simple machine learning approach, we can understand if this new song has a familiar voice; has a ukulele.
We can scale this up to many million more songs, even though the curation is not as good as the human component. We can scale that for similarity, which uses machine learning and basic tools.”
Using Data to Curate Recommendations
Streaming services need to discover new tracks, which they learn about from other sources. But with the huge volume of songs appearing online daily—from sites like Soundcloud and submission tools like CDBaby—how can a human find great tracks? One strategy is to use data to scour unheard tracks, looking for signals.
Pandora’s Celma says that one of the biggest things data has given the company is the ability to find these emerging songs. “The biggest thing [data science and machine learning have given us] is trying to discover new music. It’s a really good tool to look at the long tail of artists that in other ways are really hard to discover, because you don’t even know how to spell these artists,” he says. “In our case, with at least 50 million fans and all the information, that really helps us to focus on the long tail of music.”
The interplay between digital services encourages this discovery, too. Jennifer Kennedy, Director of Data Science Engineering at Soundhound, explains:
Using our app in a crowded bar, even with the background noise, you’re able to say, ‘I love this, I’ve never heard it before.’ We have integration with back-end services and we’re integrating with Pandora right now, and Spotify and rdio and folks. So you can feed [the song you’ve identified] into whatever streaming service you’re using. Then, when I’m listening to my Pandora station, all of a sudden I’ve got all sorts of other interesting music that’s very similar.
The whole ecosystem is starting to work together, so it isn’t just one company, it’s the whole data-driven approach on the back-end, that the whole ecosystem is going to make music that much easier for everybody to find and listen to the songs that they love and the music that they love.”
Analytics
The music industry uses analytics for many reasons, such as:
- To determine how tracks are performing
- To decide who gets paid for airplay or purchases, and funnel that money to the right creators and licensors
- To best spend marketing dollars
- To plan out tour dates and timing
- To understand and embrace growing music trends
- To set the price of advertising and sponsorship
Exactly how these things are analyzed has changed in recent years, because now that we consume music in many new ways, we need new kinds of analysis. Tech startups thrive on data, while labels and incumbents have been slow—even averse—to its use. Music players generate playback information; social platforms track sharing; and with a phone in our pocket, every fan is a data collector. Shazam and Soundhound let people identify songs in the wild—at concerts and festivals, on television, in clubs. Arbitron’s 360 provides information on the listening habits of a paid panel, but phone-based tools take analytics from focus group to global census.
Reconciling data about online streaming versus broadcast radio consumption has not gone smoothly. In late 2011, Pandora measured audience listening using average quarter hours, the same metric that Arbitron uses to measure traditional AM/FM radio, and that stations then use to determine advertising rates. Arbitron challenged the legitimacy of Pandora’s use of the measure to compare traditional radio and online audio audience estimates, and the industry still can’t agree on proper measurement. It seems clear, however, that a comprehensive measurement of music consumption will include broadcast, playback, and streaming across many platforms.
Even when you can’t get to the data that would feed your analysis, it’s easy to create your own. Music is inherently social, with fans actively sharing their likes and dislikes. Platforms like Facebook, Twitter, and YouTube include popularity data. Mining this kind of data is what helped Next Big Sound improve its predictions beyond simple playback.
But sometimes, even more basic approaches work. For example, when he was at EMI, David Boyle—now EVP of Insight for BBC Worldwide—started a survey program to better understand the listening habits of fans. He used the resulting studies to create an appetite for data within the company, eventually gaining access to more detailed transactional data that EMI had been sitting on for years.
Over a three-year period, Boyle’s survey project collected listening data on more than a million fans. At its peak, the company was conducting twelve concurrent online interviews with listeners.
We Know All About You
Because music preferences are both intensely personal and widely, publicly shared, analysts can infer a great deal from listening habits alone.
An analysis of the words used in songs shows that the intelligence of music lyrics has dropped in the last decade, with Billboard’s top-ranked songs sliding a whole grade level. Artists like Ke$ha and Katy Perry have few words in their lyrics, and Ke$ha writes at a grade level of 1.5. But does this indicate something about the intelligence of audiences? In a particularly controversial example, Virgil Griffith launched the dubiously causal musicthatmakesyoudumb website, linking college SAT scores to the most popular artists at those schools.
In a slightly less controversial study, music has also been linked to cognitive styles, with more empathetic people preferring mellow, gentle, emotional, even sad low-arousal music; and more systemizing people (i.e., people who tend to focus on understanding systems by analyzing the rules that govern them) preferring positive, cerebral, complex, intense music. The authors of the study point out that this may be useful for clinicians, counsellors, and those dealing with patients on the autism spectrum.
And of course, since we declare our musical tastes on social platforms like Facebook, marketers can target campaigns at us based on the music we listen to and what that says about us—which often includes race, gender, and socioeconomic status.
What’s the Next Big Hit?
The sooner in the lifecycle of a track that musicians and labels can detect success, the better. The timeline for feedback on song popularity varies with the medium: numbers for physical purchases took weeks; digital purchases take days; playback on streaming services takes hours. But, with the right technology, popularity can start to be calculated as soon as when consumers first hear a track.
Services like Shazam and Soundhound—which let users identify tracks they hear in the wild—sell data about what people are trying to identify to the music industry. But the data is part of a virtuous loop of learning: The BBC’s Radio One, for example, uses Shazam’s data in its playlist decisions; Shazam, in turn, uses new tracks from the BBC to seed its library of song signatures, and as a baseline of consumption.
The predictive capability of these services is remarkable. Cait O’Rearden of Shazam cites one example in which both Katy Perry and Lady Gaga released singles in Europe at roughly the same time. Based on the amount of Shazams for each song within the first few hours of their releases, the company knew that Perry’s track would be a hit, but Gaga’s wasn’t likely to thrive.
What Are Music’s Turing Problems?
Music science has come a long way since the release of the CD. But there are still a significant number of hard problems to solve.
Preferences Change over Time, and Time of Day
Streaming services and digital storefronts thrive on their recommendations. But the music we want to listen to changes throughout the day, based on our activities—driving, working, exercising—and the people we’re with. Keeping a listener for a long time means adapting to their needs. This is a challenge for two main reasons.
Maximizing listener engagement means adapting what’s playing automatically. Time of day is one clue, since people are likely to be commuting in the morning and evening, working during the daytime, and partying in the evenings and on the weekend. The device that’s streaming content is another clue: mobile devices suggest a moving user, while desktops suggest work. Users provide some cues, skipping inappropriate songs, but as Saavn’s Malhotra observes, users aren’t forgiving when the algorithm doesn’t work. Google’s Douglas Eck, who researches the intersection of music and machine learning for the search giant, points to recent advances in machine learning as a possible solution:
The basic collaborative filtering methodology is matrix factorization of a consumption matrix, where the rows are users and the columns are things that you consumed, and you factorize a few numbers and you come up with numbers to represent every user and numbers to represent everything that’s being consumed like music tracks and artists.
So it turns out that when you start thinking about context, the hot thing in the field right now are these tensor models where you add another dimension. You keep that pretty low dimension, like ten or twenty, but now you have these twenty small transform matrixes that you’re learning that let you take a general similarity space and go, ‘I know Wilco’s similar to Uncle Tupelo because they’re related in playback history and also because one’s a splinter band,’ and now you can ask, ‘what’s similar to Wilco in the morning?’ or ‘what’s similar to Wilco for jogging’ or ‘what’s similar to Wilco for in the car?’ and pull out this really interesting structure.
It just falls out of the math around what’s happening in tensor models for matrix factorization.
Changing listener circumstances pose another problem. A parent looking after a child might stream children’s music for a period of time, giving the algorithm misleading information about their tastes. Distinguishing between the various personas and roles a user can take on across a day is hard to do. Sensors, wearables, and smarter playback systems can help, but some of these may invade privacy, as Samsung learned with its smart televisions.
It’s not just time of day that can stump services. On average, people’s musical tastes evolve quickly from childhood to age 25. But by 30, they “mature” and tend not to change. Many of the big streaming services are now trying to capture audiences for years, even decades, and to do so they need to age with their listeners.
Underlying Filters: User’s Choice vs Serendipity
In a digital service with millions of tracks, users train the service about their preferences. One way they do this is by skipping, or upvoting, tracks. But music also has specific attributes—genres, or even, in Pandora’s case, a music genome. Pandora knows, for example, whether a song has ukulele in it. Someone who isn’t a fan of that instrument might want to block tracks with a ukulele; but would that be a good idea? What if a popular musician incorporated ukulele into a track? Many electronic music fans didn’t like folk music until Avicii decided to bring a folk band on stage.
Spotify/The Echo Nest’s Brian Whitman thinks this balance is important:
The term we’ll use for that is ‘negative curation.’ Is there a way that a system can say, ‘no, don’t do this based on some information that we have on the user’? We don’t rely on that too much. Whereas we might know that a song has ukulele in it, we might know that you normally don’t listen to solo ukulele artists but we also know that over the sum of things you’ve listened to a lot of different kinds of music, and some of it might have had ukulele in it. And so all the other information about that song—that it’s a new hot hit by Avicii; that you tend to like new American Dubstep music—that would override, let’s call this, the ukulele coefficient (to put a terrible phrase on it.)
We would never use, like Pandora might, the binary ukulele yes/no as a filter. [We] might, in the future have a playlist that was called ‘girl’s night out,’ for example, and maybe we would never play that to you because we know you’re not a girl. That might happen. But I don’t think we would ever use musical data as a blank filter on someone, because I think that people like to have their horizons widened, and there’s been so much great music over the years that challenged people’s perceptions of what they thought they’d like. That’s what’s so great about music: what’s really amazing about automated recommenders is that they can sum up all the other things that are in that song and help you understand it anyway.
Striking the right balance between giving users access to granular filters, versus making recommendations that can yield the kinds of serendipity listeners are hoping for when they want to discover new music, is a serious challenge—and one on which streaming services compete.
Detecting Copies and Covers
Modern song detection is extremely powerful. Algorithms from Shazam, Soundhound, Gracenote, and others can detect not only copies of a song, but songs played in noisy environments such as clubs or the background of videos. They can even detect when someone’s singing a cover of a song or humming it.
This poses a legal dilemma. Should an artist be able to take down copies of their song when sung by an aspiring fan? Should a performer be able to restrict whether a family shares a video shot in a public place simply because their song was playing in the background? Without proper guidance, groundbreaking projects like Kutiman’s Thru You—which uses found YouTube clips of everything from a capella vocals to synthesizer demos to short music lesson samples to create new songs—remain trapped in legal limbo.
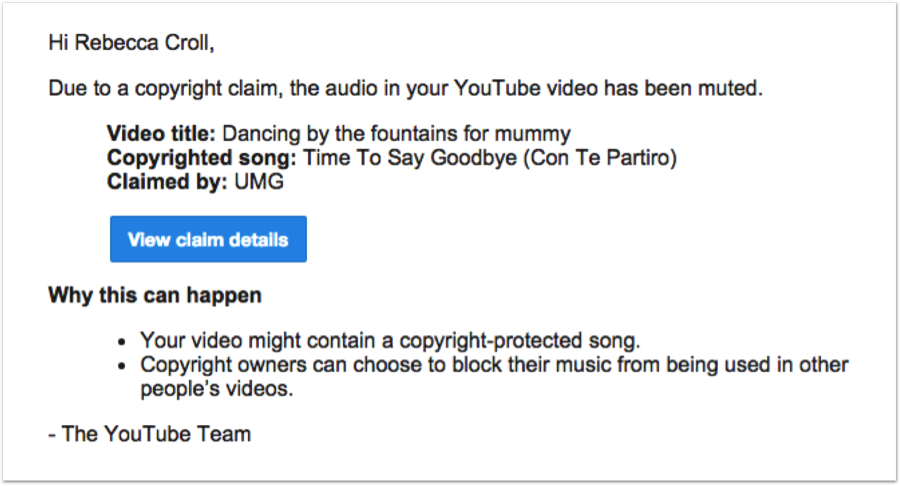
This is a slippery slope from legitimate copy protection to the suppression of public activity, and the law isn’t clear, with thousands of copyright claims being issued every day such as the one in Figure 1-4.
Collaboration and Latency
In 1994, The Future Sound of London released ISDN, an album that took its name from the Integrated Services Digital Network, an early wide-area-network technology. This was an early attempt at live streaming, coming from the artists’ studio across ISDN Primary Rate circuits to three separate radio stations, who then broadcast it to their listeners.
While this was an early attempt at live streaming and collaboration, it happened in one place. The musical parts, such as Robert Fripp’s guitar work, had to be recorded in advance, mixed at the band’s studio, and transmitted. Today, despite advances in networking, latency is still unavoidable.
Music is about rhythm. As such, real collaboration at a distance is hard because of latency. Even at the speed of light, it takes 13 milliseconds for light to travel from New York to Los Angeles. Recent years have seen the rise of collaboration tools like Splice (Figure 1-5), a sort of GitHub for music, which allows distributed performers to upload, edit, and annotate their work.
Tools such as Splice record information straight from a Digital Audio Workstation (DAW), including not only notes, but details about software configuration and instrument settings. The result is a platform that handles version control, annotation, and in-the-cloud mixing.

Splice co-founder Matt Aimonetti thinks that while technology might someday make it to live collaboration, at least for the near future, working together will be an asynchronous process:
I personally think we will get there eventually, but I’m not sure whether people will want to do it that much. When we started Splice that was a big question: Do we want to do it synchronously or asynchronously? Coming from a programming background, I like pairing, but I also like to work asynchronously.
When it comes to music I’m not always inspired to work on music. Jamming is great, but depending on the kind of music that you do, especially now where you have one person with all these instruments, building the song, I think there’s value in doing more asynchronously.
I work with somebody in Australia, and we aren’t online at the same time. I used to work in studios, and even in the studio, very often we would do recording separately. I think the creation process has an asynchronous component where everybody is jamming together, getting some ideas, and then there’s the work done in the studio, and I guess we’re focusing more on the studio part.
Nobody Can Predict Number One
Many of today’s hits are formulaic. An astonishing number of them are the work of just a few producers, and delivered by global stars. Swedish producer Max Martin, for example, has had more than 50 top-ten singles, more than Madonna, Elvis, or the Beatles. And yet, the number-one slot eludes formulaic songwriting.
Several industry insiders confessed that while many popular songs follow a formula, the number-one, break-out successes—Adele, Lorde, Gotye, Mika—tend to depart from tradition. Indeed, it’s these tracks that chart the course of musical innovation precisely because they’re novel and different.
Despite this, data-driven analytics has significantly improved how well we can predict hits. Next Big Sound has demonstrated that it can predict future hits, as shown in Figure 1-6, by combining data on listening behavior with social media engagement and mentions of an artist online.
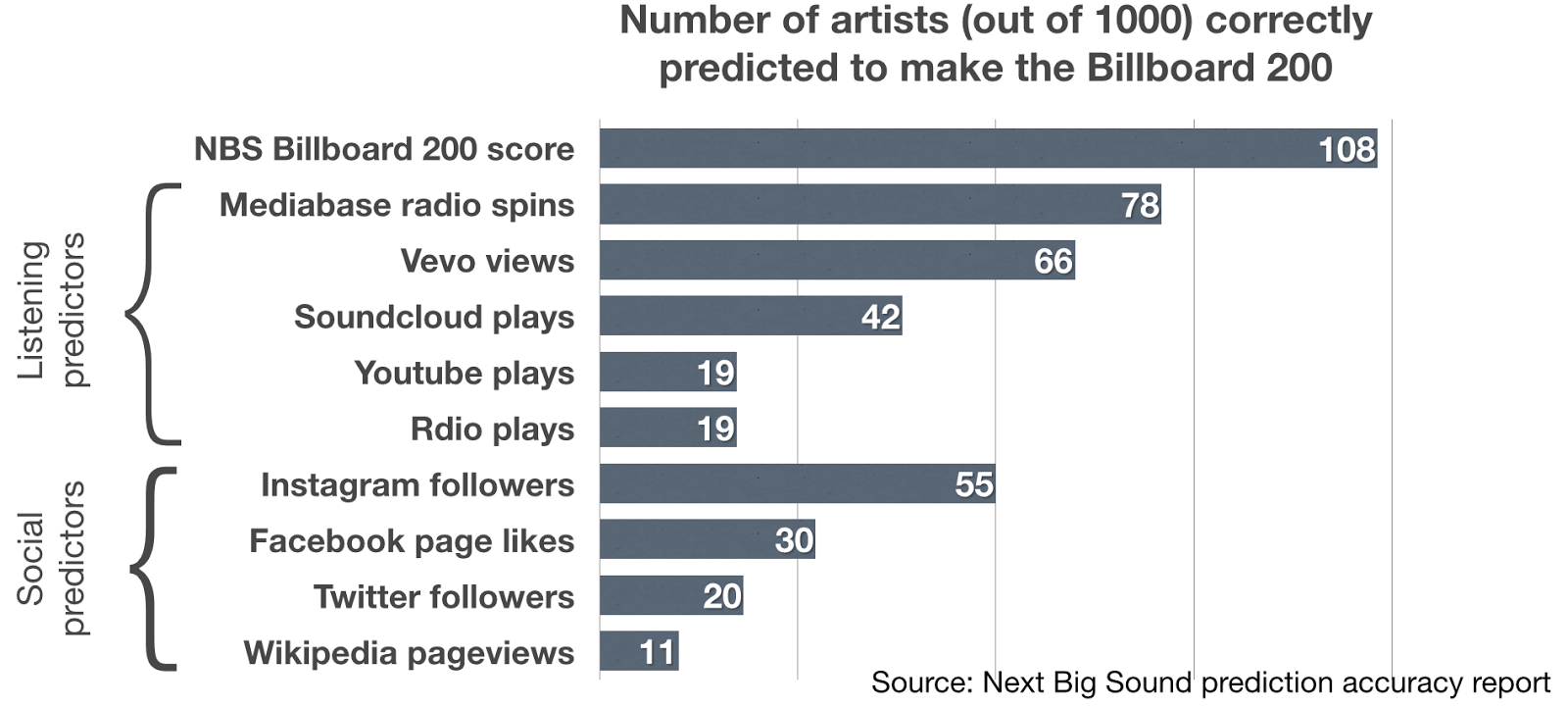
Co-founder Alex White says his company sells its predictive data to the industry. “We track the likelihood within 12 months that a band will make their first appearance on the Billboard 200 chart. It’s a Bayesian model that updates every day based on the new data that comes in and it learns over time how to weigh different sources, for example weighting Myspace less heavily than Spotify or Shazam.”
Fast Algorithms that Aren’t Too Close or Too Far
Google’s Eck says that listener taste is inconsistent, and as a result, algorithms need to learn quickly with fresh data:
That I didn’t like a song on Tuesday and I thumbed it down, the simplest thing is to say, ‘you’re never going to never, ever going to hear that song again. Or the live version. Or any version. And if you give me two thumbs down I’ll erase that artist from your life.’
But where I want to see us to move in the field is that we want models that are really learning fast and locally. We want a model that’s smart enough to come to you with more flexibility, but learn quickly in that session, ‘oh, this is what you’re in the mood for.’ To pick up a few signals—they may be latent signals like skips, or really direct signals, but to recognize that it’s Wednesday morning now, not Tuesday morning, what do you want to hear today?’
That’s a really interesting data model because it requires freshness, it requires models that can learn really fast. It’s a really tough problem to make a product that does that.
Sometimes recommendations are too good. In addition to temporal and situational changes, algorithms that select songs need to find tracks listeners want—but not ones that match their existing music collections. Eck explains:
People don’t necessarily like you to recommend them things they like. ‘Why are you recommending me Wilco? I already like Wilco.’ Those are the responses you get. It’s only one segment of listeners, but [Google] gets complaints like, ‘you recommended me Wilco,’ and we get permission to go look at their music collection, and we’re like, ‘dude, you don’t listen to much—you sometimes listen to Uncle Tupelo on that crazy day, but you usually listen to Wilco; isn’t it okay for us to be playing Wilco?’
There’s this question of user trust and explaining recommendations that suggests that it’s not enough to know what someone likes. It’s enough to know what someone wants to see right now.
Given the huge impact that the right algorithms have on listener loyalty, much of today’s music streaming industry hinges on ubiquitous data collection, fast convergence on what listeners want based on every possible signal, and the ability to balance novelty and familiarity in just the right ways.
However, there’s a bottleneck to how quickly we can learn what users like—one that comes from the users themselves. Researchers estimate that it takes five seconds to decide if we don’t like a song, but twenty-five to conclude that we like it. Unlike an art gallery or a web storefront—where you can display a wall of images and have someone’s eye saccade across it quickly—you can’t play several sounds at once.
Even when listeners say they like a song, it’s not clear what the impact of social pressure is. Google’s Eck cites research that shows neural scans and other biometric measurements are a better indicator of actual preference than what users declare.
On the Horizon
The field of music science is exploding. What does the future hold?
Transition to Music-as-a-Service
Music purchases are giving way to streaming. This isn’t just a shift in commerce—it fundamentally means that we’ve moved from a world where listeners “pulled” music from publishers with their purchases, to one where the services “push” songs based on algorithms. In theory, this allows a far wider range of music to reach audiences—rather than playing one song repeatedly, services can play algorithmically similar songs.
The other consequence of push-based music is that every listener action trains the algorithms. There’s less need for phone-ins and feedback groups when every service learns from its users.
New Ways to Listen
Saavn’s Malhotra points out that “every car is about to ship with a SIM card, and that makes it a rolling hotspot.” Our music will follow us from the bedside, to the commute, to the office, to the gym. Devices can offer context, changing how we consume music. Jeremy Silver, author of Digital Medieval and longtime digital music executive, calls content a gateway drug for cloud services, helping keep us loyal to whatever Internet cloud we rely on for messaging, email, photo sharing, and social graph. Content loyalty may influence our choice of everything from phone, to home audiovisual equipment, to car, to other forms of entertainment.
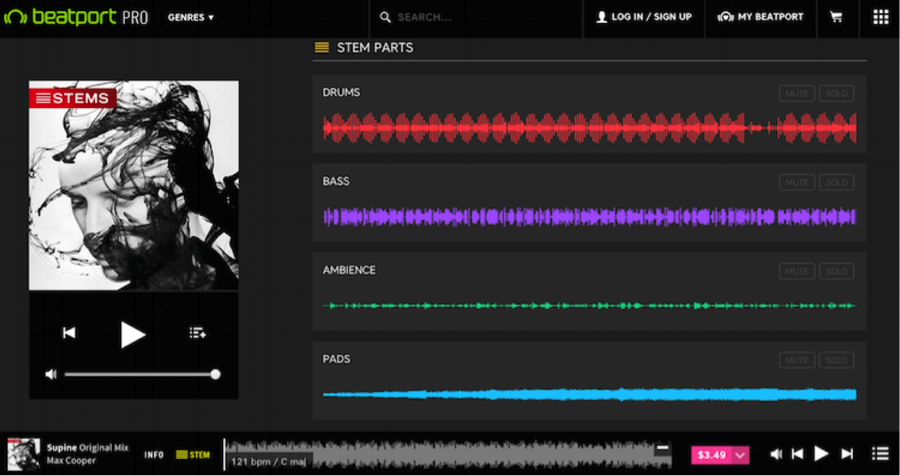
It’s not just which brands of listening service we subscribe to—the playback tools themselves will change how we listen. A variety of new music players let the listener control which parts of the music they hear. Native Instruments’ new Stems format (shown in Figure 1-7) sold via Beatport and built into a variety of music software tools, delivers not only the finished song, but its component parts.
Google Maps creator Lars Rasmussen’s new startup, Weav, includes multiple versions of each song part as shown in Figure 1-8, allowing the track to change as the user adjusts playback speed.
Music Intelligence Merges with Distribution
Streaming services need to be superb at choosing the next song. Fans expect music discovery; and song variety gives the services a competitive edge. In the last year, there has been a tremendous amount of investment and acquisition in the industry:
- Spotify bought The Echo Nest, which was based on music intelligence research from MIT, for US $100M in March 2014.
- Apple bought MusicMetric, an analytics firm, for a rumoured US $50M in January 2015.
- Pandora bought analytics firm Next Big Sound in May 2015 for an undisclosed amount.
- Saavn closed a $100M investment round in July 2015. When the company launched, advisor DJ Patil (now the US Government’s Chief Data Officer) urged them to “be a data company as much as a music company.”
Licensing Is Unclear
When it comes to payment, digital music is complex. Songs might include samples; tracks might be used in amateur and professional videos; payment might come from purchases, streaming, or shared advertising revenue.
It’s clear that the music industry is undergoing a significant reset. Labels and publishers that deliver music digitally simply can’t sustain the revenues they once enjoyed when they shipped physical music. Artists, armed with data from companies like Kobalt and Next Big Sound, are finally aware of just how little money from their songs they actually see.
It’s been said that while humans are bad at keeping notes, software has no choice but to do so. The same is true of digital playback. Now that songs have metadata and services will be the dominant model of music delivery, detailed accounting is sure to follow. That means trillions of plays a year, each analyzed, aggregated, and calculated into royalty payments.
Splice co-founder Matt Aimonetti explains that most of the people using Splice are in the Electronic Dance Music and Hip-Hop space, possibly because they’re technically savvy. In that world, attribution and re-use is common. “You don’t really take a track and reproduce the same track without giving credit,” he says. Amionetti thinks that services which combine the source of samples with the production of new music might resolve this, ensuring everyone gets attribution and compensation: “There’s this discussion we’re having internally about what would have happened [in the legal battle over Robin Thicke’s Blurred Lines, which Marvin Gaye’s estate accused the singer of stealing] if [original composer] Marvin Gaye were still alive, which obviously nobody can tell for sure.”
In many ways, collaborative services like Splice, which encourage re-use, are a sort of pre-nuptial agreement for sampling. Aimonetti explains:
The licensing things we’re looking at are, with some of the tracks, if you [re-use or sample] them, you agree to say, ‘if I distribute something, there will be a percentage that will go to the original author.’ It will be simpler—if you accept that, here’s the deal. If you want a song, you can get everything, but you have to give 40, 60, 80 percent.
We’re building this concept of channel, and a channel is everything going around an artist or specific theme… We realize that in the EDM [electronic dance music] space, a lot of people break out because they remix someone else that’s well known, and they do a great song, and they get picked up by the artist, by the label, and then they release the remix.
So we have this concept of endorsement where if I release a track and somebody’s remixing it and it’s great, it might not be published on my label, but I might endorse it, and I think that’s very valuable, especially if you have a full-time job and you just want to do some music. You don’t care about making money.
As tools for creation and collaboration move online, they can track song provenance and handle the complex problem of licensing and attribution throughout a song’s entire lifecycle, from initial composition to engineering to distribution.
Algorithms as Musicians?
Will machines ever get better than humans at making music? For decades, researchers have been trying to generate songs automatically, using everything from the numbers in pi to cellular automata. But as Google’s Eck explains, this isn’t an easy challenge.
It turns out you can generate music in one of two ways. [One way is that] you can give the computer the blueprint, the overall structure of what you’re trying to generate, and the computer fills in the gaps. David Cope has done a lot of work on this. Now [the other way,] thinking about Deep Networks—it turns out that in some really important ways, music is harder than speech to learn with a recurrent network or other filtering approaches.
Music has this tendency to be repeated in long chunks, which turns out to be a challenge for technical reasons. Yet this chunking, this idea that you’re going to spit out some pattern, and then repeat that pattern but shift it up a bit or something, is the hallmark of Western, metrical music. And no-one has managed to take a simple model—a model that has the capacity to learn a time series like a recurrent neural network—and make it generate structurally correct music.
For me, at least, one of the mysteries of my career is how can six-year-olds do jump-rope music—how are they so good at it—that if you violate the musical structure or skip a note they notice; if you ask them to make up a song kids’ brains do this really, really well. But fundamentally this idea of music being in time, of music having this structure that’s really predictable, that you can set up these expectancies and see them violated, it’s the hallmark of what makes music, music. And computers really can’t do it well, which I think is great. I think it’s lovely.
Soundhound’s Kennedy agrees. “For the computer to recognize music, it’s all in the frequency domain…which is a different way, I think, than how the brain actually processes against the time domain. That being out of sync means that for the computer to do it—to actually mimic what humans hear and feel and process music is just plain different.”
Human/Machine Hybrids
Once listeners tire of their familiar tracks, they want suggestions. Machine-assisted, human-curated playlists are the near future of music services. And once algorithms get good enough, making a playlist we nearly never skip, many listeners will find that they don’t need on-demand choice; this could, in turn, lead other services to rely on the lower-cost statutory license that Pandora enjoys today. In other words, when a curated playlist is better than what you’d choose yourself, you don’t need choice, and that affects industry revenues significantly.
Once recommendation and playlist algorithms get good enough across all services, human curation will make the difference. Perhaps realizing this is what made Apple hire BBC’s Zane Lowe, one of the world’s most influential radio tastemakers. And then, of course, we’re back to a world much like radio, in which a few heavyweight influencers decide what gets attention—only this time, they’re doing it with data from trillions of interactions between people and sounds, in real time, worldwide.
Conclusions
The shift from physical to digital music, and its movement from our homes to the cloud, is fundamentally altering our relationship to songs. We’re creating a perpetual musical feed, a soundtrack to our entire lives, constantly sampling our behavior and adjusting itself to us.
The traditional music industry struggled to apply data to its art at first, because labels were intent on monetizing distribution rather than art. As Moby said of music publishing and rights start-up Kobalt in an interview with the New York Times, “Kobalt is more like a tech company than a music company. As a result, no one ever told them to steal from their artists.” Labels intentionally blinded themselves to the power of data, and are only now recovering.
But modern artists have a vast range of ways to create their music, from desktop DAWs and self-publishing services, to uploading to Soundcloud, to pressuring their fans for attention on Hype Machine, to distributing their tracks via CDBaby. The industry’s gatekeepers have let the walls crumble, leaving only ambition and an Internet connection as the barriers to publishing a song.
It’s About Musicians and Fans
Google’s Eck is also a musician, and he’s quick to remind us what the music industry should be about. “I think it’s important to keep in mind that behind everything we’re trying to achieve with music recommendation and making search better for music and getting people to stream music in their cars is that, this is music, and there are musicians working their hearts out to reach listeners and listeners who are absolutely obsessed with music.”
Next Big Sound’s White agrees. “The more philosophical question is, do you believe ‘there are hits out there that if enough people heard them they would be number one worldwide super smashes,’ or do you think that ‘if a song is good enough it will be heard and number one?’ I have heard enough phenomenal music that is not charting or renowned or even breakeven or languishing in obscurity to know that there are talented musicians who will never be known, period.
I hope that [data] fixes that, because even if it’s a small group, even if it’s fifty people interacting with a guy who’s recording EDM tracks in his bedroom, that amount of activity and repeats and streams will trip off alarms and the labels and radio and promotional outlets and other powers that be will listen and flag it and spread wider, and the ‘best music’ that people like the most will be given the audience it deserves.”
It’s Not About Copying, It’s About Feedback Loops
In his book An Engine Not A Camera, Donald Mackenzie talks about how economists once viewed themselves as detached from the market, impartial and observing, like a camera. This wasn’t the case, though—markets and financiers used the work of economists to create new financial instruments, such as derivatives, which in turn shaped the market. The economists weren’t a camera, they were part of an engine.
The same thing is happening in music. The feedback loops have always been there—late-night callers asking for their favorite tracks; musicians inspired by a new band or technology, which creates genres like Grunge or Glitch. But with digital music, personalization, big data, and streaming services, the feedback loops have tightened dramatically, leading us into what could be an era of tremendous innovation and a musical renaissance.
“It’s time to stop focusing on what was or ‘should’ be,” said Liam Boluk, a venture capitalist focusing on the digital video space, about the music industry’s decline. “Industries don’t rebuild themselves.” As incumbents come to terms with a changed world and realize that digital services are here to stay, the music industry is ready to find a new normal.
And it’ll be data that shows it how to do so.
A World More Organic
Perhaps aptly, the best insight comes from a musician. As Amanda Palmer says of algorithms, “You can definitely say, ‘piano, minor key, chick singer.’ But I would love to believe—and you can call me an optimist in this department, or you can call me a Luddite—but I would love to believe that there is a really big, important X-factor that humans making machines cannot solve for.
The same way I really don’t want to live in a world where we agree that because Google can scan every great artwork in the world and generate wonderful new masterpieces for our walls and our museums—why don’t we just agree that that’s not a good idea, and that we would rather live in a world with a more organic process?
Which is not to say that AI is not useful, and that machines are not useful, and that math is not useful; but where’s the fucking romance in algorithming ourselves to death?”