Chapter 5. Collecting and Displaying Records
In this chapter, our first agile sprint, we climb level 1 of the data-value pyramid (Figure 5-1). We will connect, or plumb, the parts of our data pipeline all the way through from raw data to a web application on a user’s screen. This will enable a single developer to publish raw data records on the Web. In doing so, we will activate our stack against our real data, thereby connecting our application to the reality of our data and our users.
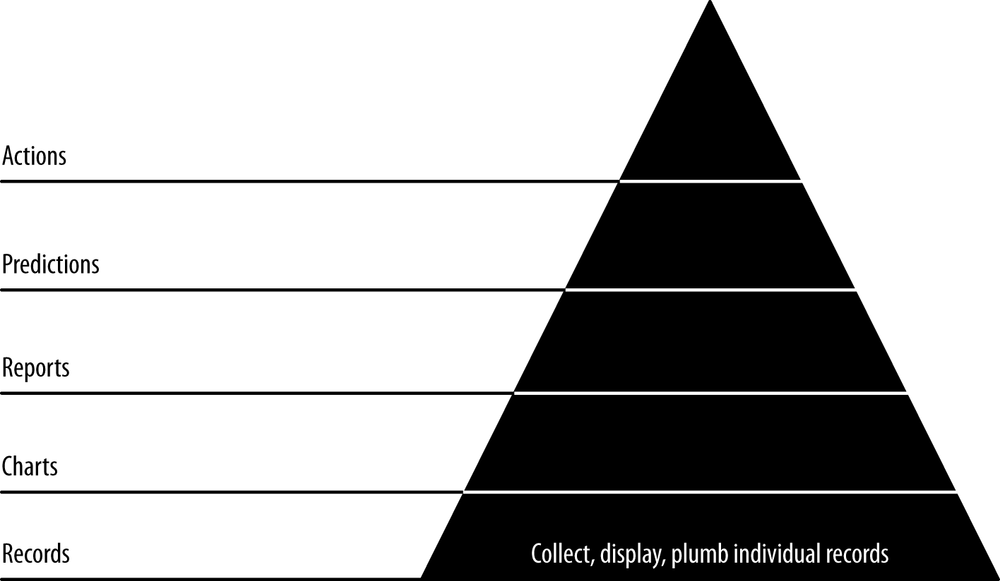
If you already have a popular application, this step may seem confusing in that you already have the individual (or atomic) records displaying in your application. The point of this step, then, is to pipe these records through your analytical pipeline to bulk storage and then on to a browser. Bulk storage provides access for further processing via ETL (extract, transform, load) or some other means.
This setup and these records set the stage for further advances up the data-value pyramid as our complexity and value snowball.
Note
If your atomic records are petabytes, you may not want to publish them all to a document store. Moreover, security constraints may make this impossible. In that case, a sample will do. Prepare a sample and publish it, and then constrain the rest of your application as you create it.
Code examples for this chapter are available at https://github.com/rjurney/Agile_Data_Code/tree/master/ch05 ...
Get Agile Data Science now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

