Given the list of states in Figure 4-1, how fast can you determine whether the state "Wyoming" is in the list? Perhaps you can answer this question in less than a second. How long would this task take in a list of 1,000 words? A good guess would be 100 seconds, since the problem size has increased 100-fold. Now, given the same list of states, can you determine the number of states whose names end in the letter s? This task is surprisingly easy because you can quickly see that the states are sorted in increasing order by their last character. If the list contained 1,000 words ordered similarly, the task would likely require only a few additional seconds because you can take advantage of the order of words in the list.

Numerous computations and tasks become simple by properly sorting information in advance. The search for efficient sorting algorithms dominated the early days of computing. Indeed, much of the early research in algorithms focused on sorting collections of data that were too large for the computers of the day to store in memory. Because computers are incredibly more powerful and faster than the computers of 50 years ago, the size of the data sets being processed is now on the order of terabytes of information. Although you may not be called upon to sort such huge data sets, you will likely need to sort perhaps tens or hundreds of thousands of items. In this chapter, we cover the most important sorting algorithms and present results from our benchmarks to give specific guidance on which algorithm is best suited for your particular problem.
Terminology
A collection of comparable elements A is presented to be sorted; we use the notations A[i] and ai to refer to the ith element of the collection. By convention, the first element in the collection is considered to be A[0]. For notational convenience, we define A[low, low+n) to be the subcollection A[low] ... A[low+n−1] of n elements, whereas A[low, low+n] describes the subcollection A[low] ... A[low+n] of n+1 elements.
To sort a collection, the intent is to order the elements A such that if A[i]<A[j], then i<j. If there are duplicate elements, then in the resulting ordered collection these elements must be contiguous; that is, if A[i]=A[j] in a sorted collection, then there can be no k such that i<k<j and A[i]≠A[k].
The sorted collection A must be a permutation of the elements that originally formed A. In the algorithms presented here, the sorting is done "in place" for efficiency, although one might simply wish to generate a new sorted collection from an unordered collection.
Representation
The collection may already be stored in the computer's random access memory (RAM), but it might simply exist in a file on the filesystem, known as secondary storage. The collection may be archived in part on tertiary storage, which may require extra processing time just to locate the information; in addition, the information may need to be copied to secondary storage before it can be processed. Examples of tertiary storage include tape libraries and optical jukeboxes.
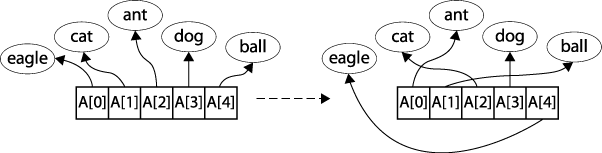
Information stored in RAM typically takes one of two forms: pointer-based or value-based. Assume one wants to sort the strings "eagle," "cat," "ant," "dog," and "ball." Using pointer-based storage, shown in Figure 4-2, an array of information (the contiguous boxes) contains pointers to the actual information (i.e., the strings in ovals) rather than storing the information itself. Such an approach enables arbitrarily complex records to be stored and sorted.
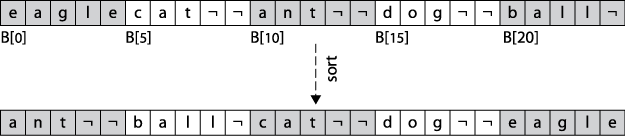
By contrast, value-based storage packs a collection of n elements into record blocks of a fixed size, s (suitable for tertiary or secondary storage). Figure 4-3 shows how to store the same information shown in Figure 4-2 using a contiguous block of storage containing a set of rows of exactly s=5 bytes each. In this example the information is shown as strings, but it could be any collection of structured, record-based information. The "¬" character represents the termination of the string; in this encoding, strings of length s do not have a terminating character. The information is contiguous and can be viewed as a one-dimensional array B[0,n*s). Note that B[r*s+c] is the cth letter of the rth word (where c≥0 and r≥0); also, the ith element of the collection (for i≥0) is the subarray B[i*s,(i+1)*s).
Information is written to secondary storage usually as a value-based contiguous collection of bytes. It is possible to store "pointers" of a sort on secondary storage by using integer values to refer to offset position locations within files on disk. The algorithms in this chapter can also be written to work with disk-based information simply by implementing swap functions that transpose bytes within the files on disk; however, the resulting performance will differ because of the increased input/output costs in accessing secondary storage.
Whether pointer-based or value-based, a sorting algorithm updates the information (in both cases, the boxes) so that the entries A[0] ... A[n−1] are ordered. For convenience, in the rest of this chapter we use the A[i] notation to represent the ith element, even when value-based storage is being used.
Comparable Elements
The elements in the collection being compared must admit a total ordering. That is, for any two elements p and q in a collection, exactly one of the following three predicates is true: p=q, p<q, or p>q. Commonly sorted primitive types include integers, floating-point values, and characters. When composite elements are sorted (such as strings of characters) then a lexicographical ordering is imposed on each individual element of the composite, thus reducing a complex sort into individual sorts on primitive types. For example, the word "alphabet" is considered to be less than "alternate" but greater than "alligator" by comparing each individual letter, from left to right, until a word runs out of characters or an individual character in one word is less than or greater than its partner in the other word (thus "ant" is less than "anthem"). This question of ordering is far from simple when considering capitalization (is "A" greater than "a"?), diacritical marks (is "è" less than "ê"?) and diphthongs (is "æ" less than "a"?). Note that the powerful Unicode standard (see http://www.unicode.org/versions/latest) uses encodings, such as UTF-16, to represent each individual character using up to four bytes. The Unicode Consortium (www.unicode.org) has developed a sorting standard (known as "the collation algorithm") that handles the wide variety of ordering rules found in different languages and cultures (Davis and Whistler, 2008).
For the algorithms presented in this chapter we assume the existence of a comparator function, called cmp, which compares elements p to q and returns 0 if p=q, a negative number if p<q, and a positive number if p>q. If the elements are complex records, the cmp function might only compare a "key" value of the elements. For example, an airport terminal has video displays showing outbound flights in ascending order of the destination city or departure time while flight numbers appear to be unordered.
Stable Sorting
When the comparator function cmp determines that two elements ai and aj in the original unordered collection are equal, it may be important to maintain their relative ordering in the sorted set; that is, if i<j, then the final location for ai must be to the left of the final location for aj. Sorting algorithms that guarantee this property are considered to be stable. For example, the top of Figure 4-4 shows an original collection A of flight information already sorted by time of flight during the day (regardless of airline or destination city). If this collection A is sorted using a comparator function, cmpDestination, that orders flights by destination city, one possible result is shown on the bottom of Figure 4-4.
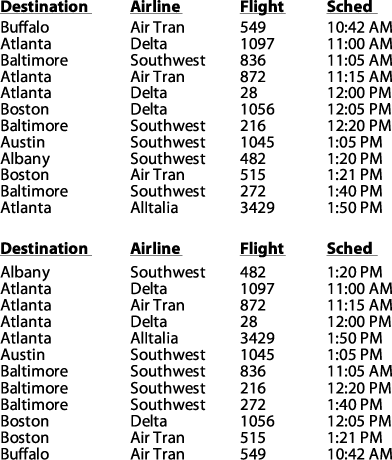
You will note that all flights that have the same destination city are sorted also by their scheduled departure time; thus, the sort algorithm exhibited stability on this collection. An unstable algorithm pays no attention to the relationships between element locations in the original collection (it might maintain relative ordering, but it also might not).
Analysis Techniques
When discussing sorting, invariably one must explain for an algorithm its best-case, worst-case, and average-case performance (as discussed in Chapter 2). The latter is typically hardest to accurately quantify and relies on advanced mathematical techniques and estimation. Also, it assumes a reasonable understanding of the likelihood that the input may be partially sorted. Even when an algorithm has been shown to have a desirable average-case cost, its implementation may simply be impractical. Each sorting algorithm in this chapter is analyzed both by its theoretic behavior and by its actual behavior in practice.
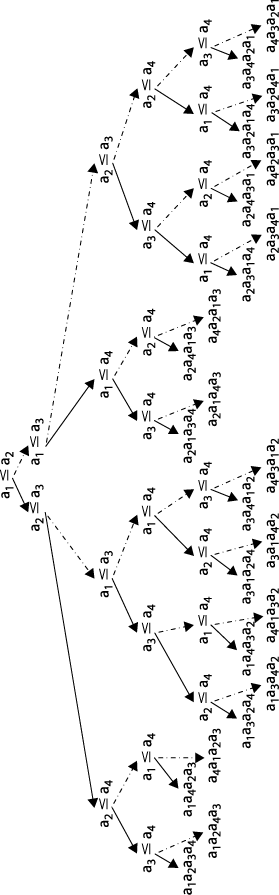
A fundamental result in computer science is that no algorithm that sorts by comparing elements can do better than O(n log n) performance in the average or worst case. We now sketch a proof. Given n items, there are n! permutations of these elements. Every algorithm that sorts by pairwise comparisons corresponds to an underlying binary decision tree. The leaves of the tree correspond to an underlying permutation, and every permutation must have at least one leaf in the tree. The vertices on a path from the root to a leaf correspond to a sequence of comparisons. The height of such a tree is the number of comparison nodes in the longest path from the root to a leaf node; for example, the height of the tree in Figure 4-5 is 5 since only five comparisons are needed in all cases (although in four cases only four comparisons are needed).
Construct a binary decision tree where each internal node of the tree represents a comparison ai≤aj and the leaves of the tree represent one of the n! permutations. To sort a set of n elements, start at the root and evaluate the statements shown in each node. Traverse to the left child when the statement is true; otherwise, traverse to the right child. Figure 4-5 shows a sample decision tree for four elements.
There are numerous binary decision trees that one could construct. Nonetheless, we assert that given any such binary decision tree for comparing n elements, we can compute its minimum height h; that is, there must be some leaf node that requires h comparison nodes in the tree from the root to that leaf. Consider a complete binary tree of height h in which all non-leaf nodes have both a left and right child. This tree contains a total of n=2h−1 nodes and height h=log (n+1); if the tree is not complete, it could be unbalanced in strange ways, but we know that h≥⌈log (n+1)⌉.[7] Any binary decision tree with n! leaf nodes already demonstrates it has at least n! nodes in total. We need only compute h=⌈log (n!)⌉ to determine the height of any such binary decision tree. We take advantage of the following properties of logarithms: log (a*b)=log (a)+log (b) and log (xy)=y*log (x).
| h=log (n!)=log(n*(n−1)*(n−2)*...*2*1) |
| h>log(n*(n−1)*(n−2)*...*n/2) |
| h>log((n/2)n/2) |
| h>(n/2)*log(n/2) |
| h>(n/2)*(log(n) −1) |
Thus h>(n/2)*(log(n)-1). What does this mean? Well, given n elements to be sorted, there will be at least one path from the root to a leaf of size h, which means that an algorithm that sorts by comparison requires at least this many comparisons to sort the n elements. Note that h is computed by a function f(n); here in particular, f(n)=(1/2)*n*log(n)-n/2, which means that any sorting algorithm using comparisons will require on the order of O(n log n) comparisons to sort. In the later section "Bucket Sort," we present an alternative sorting algorithm that does not rely solely on comparing elements, and can therefore achieve better performance under specific conditions.
Common Input
For each sorting algorithm, we assume the input resides in memory, either as a value-based contiguous block of memory or an array of pointers that point to the elements to be sorted. For maximum generality, we assume the existence of a comparison function cmp(p,q), as described earlier.
[7] Recall that if x is not already an integer, the ceiling function ⌈x⌉ returns the smallest integer not less than x (e.g., it rounds the value of x to the next higher integer).
Get Algorithms in a Nutshell now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

