May 2025
Intermediate to advanced
452 pages
6h 3m
Japanese
この作品はAIを使って翻訳されている。ご意見、ご感想をお待ちしている:translation-feedback@oreilly.com
分散データ分析システムの実装( )では、部門や企業全体の計算ニーズを満たすために、社内のマシンのクラスタやクラウドベースの予約容量などの計算リソースのプールを管理する必要がある。チームやプロジェクトが長期にわたって同じニーズを持つことはまれであるため、コンピュータのクラスタは、いくつかのチーム間で共有されるリソースである場合に最適に償却され、マルチテナントの問題に対処する必要がある。
2つのチームのニーズが異なる場合、それぞれにクラスタのリソースへの公平で安全なアクセスを与え、同時にコンピューティングリソースを長期にわたって最適に利用できるようにすることが重要になる。
この必要性により、大規模クラスタを使用する人々は、モジュール化によってこの異種性に対処し、データプラットフォームの交換可能な部分としていくつかの機能ブロックを出現させることを余儀なくされている。 例えば、機能ブロックとしてデータベース・ストレージを参照する場合、その機能を提供する最も一般的なコンポーネントはPostgreSQLやMySQLのようなリレーショナル・データベースであるが、ストリーミング・アプリケーションが非常に高いスループットでデータを書き込む必要がある場合、Apache Cassandraのようなスケーラブルなカラム指向データベースがより良い選択となる。
この章では、ストリーミング・データ・プラットフォームのアーキテクチャを構成するさまざまな要素を簡単に調べ、完全なソリューションに必要な他のコンポーネントに対する処理エンジンの位置づけを確認する。 ストリーミング・アーキテクチャのさまざまな要素を把握した後、ストリーミング・アプリケーションへのアプローチに使用される2つのアーキテクチャスタイル、LambdaアーキテクチャとKappaアーキテクチャを調べる。
私たち 、データプラットフォームとは、ほとんどのステークホルダーにとって有用であることが期待される標準コンポーネントと、ビジネスが解決したい課題に特化した目的を果たす特殊化システムの構成であると考えることができる。
図3-1は、このパズルのピースを示している。
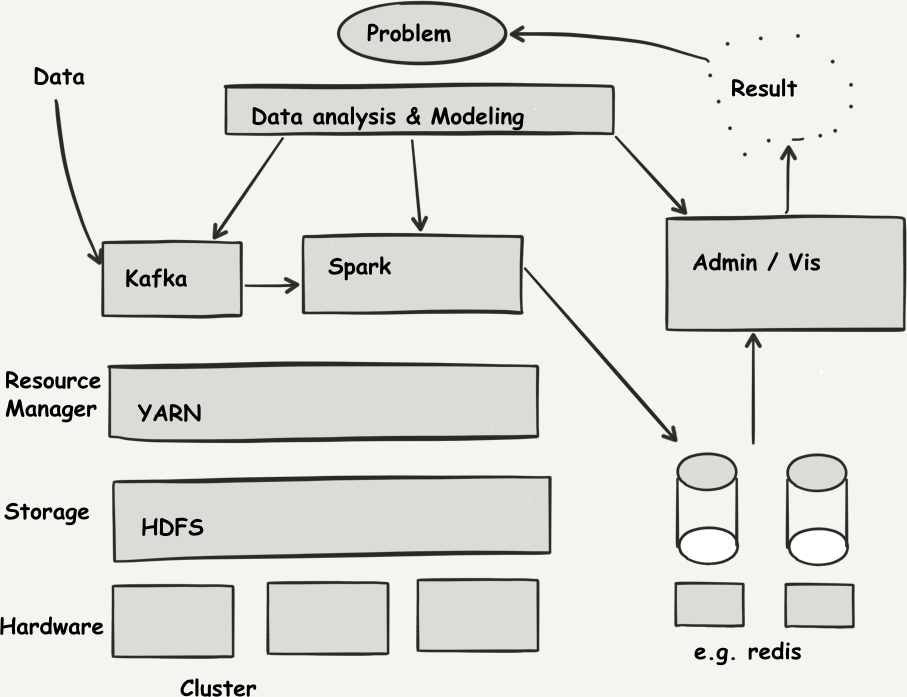
スキーマの一番下にあるベアメタルレベルから、ビジネス要件によって要求される実際のデータ処理まで行くと、次のような発見がある:
オンプレミスのハードウェア、データセンター、または(Amazon、Google、Microsoftが提供するTシャツサイズのような)同種のクラウドソリューションで仮想化される可能性があり、基本演算子がインストールされている。
このベースラインインフラストラクチャの上に、マシンが計算結果や入力を保存するための永続化ソリューションへの共有インタフェースを提供することが期待されている。このレベルでは、Hadoop分散ファイルシステム(HDFS)のような分散ストレージソリューションがある。 クラウド上では、この永続化レイヤーは、Amazon ...
Read now
Unlock full access






